Nginx
是什么:
- HTTP Web服务器、反向代理、内容缓存、负载平衡器、TCP/UDP代理服务器和邮件代理服务器。
- Nginx以高效的epoll、kqueue、eventport作为网络IO模型,在高并发场景下,Nginx能够轻松支持5w并发连接数的响应,并且消耗的服务器内存、CPU等系统资源消耗却很低,运行非常稳定。
**网站:**http://nginx.org/en/
功能:
- web服务器:
- 静态文件服务:非常适合处理静态文件(js,css,html,图片等),能够快速的高效将这些图片发送到客户端。
- 动态内容处理:通过后端应用的服务器(uwsgi,fastcgi等)配合进行动态数据的请求处理。
- 目录索引和自动索引:可以自动生成目录列表,方便用户查看文件。
- 反向代理服务器:
- 负载均衡:nginx可以将客户端请求分发到多个后端,支持多种算法(轮询,最少连接,ip哈希)。
- 缓存:可以缓存后端服务器的响应,减少前端对后端的请求,减轻服务器的压力。
- ssl/tls:支持ssl/tls加密和解密,减轻后端服务器的负担。
- http2/支持:支持 HTTP/2 协议,提高页面加载速度。
- 邮箱代理:smtp/pop3/imap 可以作为邮箱服务器的代理,支持ssl/tls加密。
特点:
- 官网直接获取源码,免费用。
- 高性能,官网提供测试数据,性能残暴,1秒内能支持5万个tcp连接。
- 消耗资源很低,有数据证明在生产环境下3万左右的并发tcp连接,开启10个nginx进程消耗不到150M。
- 有能力可以自己对nginx进行二次开发,如淘宝的tengine。
- 模块化管理,nginx有大量的模块(插件),运维根据公司的业务需求,按需编译安装设置即可。
能做什么:
- 提供静态页面展示,网页服务。
- 提供多个网站、多个域名的网页服务。
- 提供反向代理服务(结合动态应用程序)。
- 提供简单资源下载服务(密码认证)。
- 用户行为分析(日志功能)。
**在线生成nginx配置:**https://www.digitalocean.com/community/tools/nginx?global.app.lang=zhCN(进行可视化操作)
运行架构模式:
- 基于事件驱动的异步非阻塞模型,这种架构使得 Nginx 能够高效地处理高并发请求。
- 事件驱动模型:件驱动模型来处理连接和请求,这种模型基于非阻塞 I/O 和事件通知机制。
- 非阻塞I/O:避免在读或者写数据是阻塞进程。
- 事件通知:通过事件通知机制(epoll,kqueue,select)来监控文件描述符可读,可写的状态,从而更高效处理多个连接。
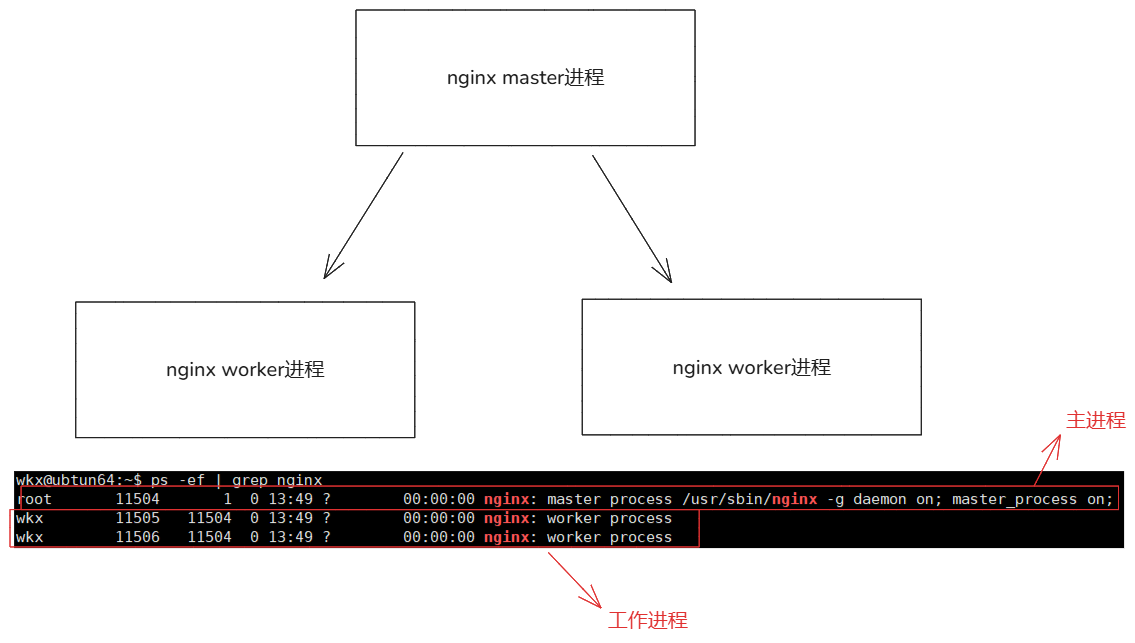
- 分为主进程与工作进程的模式。
- 主进程:也就是nginx的启动进程,负责监控工作进程。主要职责:读取解析配置文件,绑定端口创建套接字文件,启动管理工作进程,捕获和处理各种信号,日志轮转和维护。
- 工作进程:实际进行操作请求的进程,负责客户端的连接和请求。工作职责:接受客户端连接请求,处理请求生成响应,将响应发送给客户端,释放连接资源。
- 多进程并发处理,通过多个工作进程来处理并发请求,提高系统的并发能力。每个工作进程可以独立运行在不同的 CPU 核心上,充分利用多核处理器的性能。操作系统会自动将传入的连接均匀分配给各个工作进程。
1.Nginx基础内容
1-1.Nginx处理HTTP请求
# 请求报文组成:
1.请求头
2.请求体
3.空行
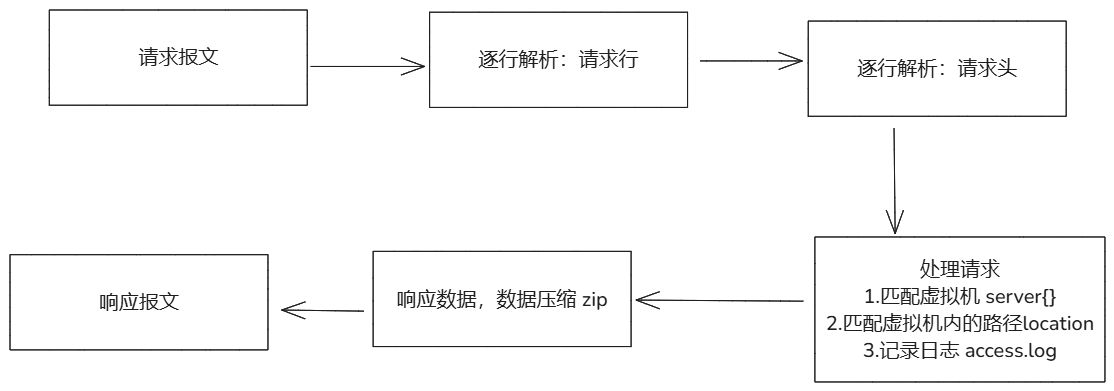
当访问:http://10.0.0.1:80/123.png
1.拆解使用的协议:http
2.使用什么浏览器访问的,什么系统访问的
3.根据你的url匹配nginx的虚拟机,返回响应的资源
4.资源内部可能有 图片 文本 等文件类型的资源,网络传输消耗大,就会使用nignx gzip压缩资源
5.在进行返回用户访问的响应体
1-2.Nginx的核心模块
# 这些模块是 Nginx 的基础功能模块,总是默认启用,可以通过官方文档查看这个模块支持的指令参数。
ngx_http_core_module:提供 HTTP 服务的基本功能,如请求处理、响应等。
ngx_http_log_module:支持日志功能。
ngx_http_connection_pool_module:管理连接池。
ngx_http_request_body_filter_module:处理请求体。
ngx_http_upstream_module:支持上游服务器(如代理功能)。
ngx_http_static_module:提供静态文件服务功能。
ngx_http_autoindex_module:支持目录列表功能。
ngx_http_index_module:支持默认索引文件功能。
ngx_http_alias_module:支持别名功能。
ngx_http_ssi_module:支持服务器端包含(SSI)功能。
ngx_http_gzip_module:支持 Gzip 压缩功能。
ngx_http_browser_module:支持基于浏览器的条件功能。
ngx_http_referer_module:支持基于来源(Referer)的条件功能。
ngx_http_rewrite_module:支持 URL 重写功能。
ngx_http_proxy_module:支持 HTTP 代理功能。
ngx_http_fastcgi_module:支持 FastCGI 功能。
ngx_http_uwsgi_module:支持 uWSGI 功能。
ngx_http_scgi_module:支持 SCGI 功能。
ngx_http_memcached_module:支持 Memcached 功能。
ngx_http_limit_conn_module:支持连接限制功能。
ngx_http_limit_req_module:支持请求限制功能。
ngx_http_empty_gif_module:支持返回空 GIF 图片功能。
ngx_http_secure_link_module:支持安全链接功能。
ngx_http_stub_status_module:支持状态页面功能。
1-3.Nginx的可选模块
# 这些模块在默认编译时通常也包含,但可以通过编译选项禁用,可以通过官方文档查看指令参数。
ngx_http_ssl_module:支持 SSL/TLS 功能。
ngx_http_realip_module:支持获取真实 IP 功能。
ngx_http_addition_module:支持在响应前后追加内容。
ngx_http_xslt_module:支持 XSLT 功能。
ngx_http_image_filter_module:支持图片处理功能。
ngx_http_geoip_module:支持 GeoIP 功能。
ngx_http_sub_module:支持响应体替换功能。
ngx_http_dav_module:支持 WebDAV 功能。
ngx_http_flv_module:支持 FLV 视频流功能。
ngx_http_mp4_module:支持 MP4 视频流功能。
ngx_http_gunzip_module:支持解压 Gzip 功能。
ngx_http_gzip_static_module:支持静态文件 Gzip 功能。
ngx_http_auth_request_module:支持基于请求的认证功能。
ngx_http_random_index_module:支持随机索引功能。
ngx_http_secure_link_module:支持安全链接功能。
ngx_http_degradation_module:支持降级功能。
ngx_http_perl_module:支持 Perl 脚本功能。
1-4.Nginx的安装方式
1.二进制文件,适合需要特定版本的用户。
从官方网站上下载二进制文件包,解压即可使用。
2.命令安装,最简单和最常用的方式,适合大多数用户。# nginx模块上不需要操心,安装了大部分模块。
# 配置仓库地址:https://nginx.org/en/linux_packages.html
sudo apt install nginx
sudo yum install nginx
3.源码编译安装,适合需要特定版本的用户,需要特定的操作。# 漏装模块可能导致有些功能无法使用,还需要重新编译。
# 编译安装的参数(一定要看):https://nginx.org/en/docs/configure.html
1.安装依赖环境
yum install pcre pcre-devel openssl openssl-devel zlib zlib-devel gzip gcc gcc-c++ make httpd-tools -y
2.下载nginx源码包
wget -O /opt/nginx-1.18.0.tar.gz https://nginx.org/download/nginx-1.18.0.tar.gz
tar -zxvf /opt/nginx-1.18.0.tar.gz
cd nginx-1.18.0
3.编译参数生成makefile文件
./configure --user=www --group=www --prefix=/opt/nginx-1-18-0 --with-http_stub_status_module --with-http_ssl_module --with-pcre
4.编译安装
mask && mask install
1-5.Nginx管理命令
使用nginx本身命令管理
nginx -t # 检查nginx.conf配置文件的语法
nginx -s reload # nginx重新加载nginx.conf
nignx -s stop # 关闭nginx服务 kill -9 nginx pid,通过nginxpid文件进行关闭nginx的,如果无法关闭请查看pid文件与nginx启动pid是否相同,进行修改即可
nginx # 启动nginx
nginx -c 指定的配置文件路径 # 指定使用那个配置文件
如果使用nginx yum安装请使用 systemctl命令操作
systemctl reload nginx # 加载nginx.conf,master进程不变,worker进程变化
systemctl restart nginx # 重启nginx,master进程变化,worker进程变化
使用lsof 命令可以清晰分别出使用的nginx是那个(对于多个nginx的情况)
lsof -p nginx-pid
# 注意
1.nginx二进制命令不能多次进行执行,会报错,因为第一次启动时占用了80或者其他端口,多次启动就会导致端口报错问题
2.用什么命令启动,就用什么命令管理,(你用nginx本身命令操作,同时又用systemclt命令操作是不可以的)
1-6.Nginx文件说明
etc/nginx/mime.types # 用于定义文件扩展名与 MIME 类型的映射关系。MIME 类型(也称为 Internet 媒体类型)是标准,用于表示文档、文件或字节流的性质和格式。
etc/nginx/fastcgi.conf # 用于定义传递给 FastCGI 应用服务器的参数。FastCGI 是一种用于 Web 服务器和应用程序之间的通信协议,广泛用于运行 PHP、Python 等语言的应用程序。
etc/nginx/uwsgi_params # 用于定义传递给 uWSGI 应用服务器的参数。uWSGI 是一个广泛使用的应用服务器,用于在 Web 服务器后面运行 Python、Perl、Ruby 等语言的应用程序
etc/nginx/scgi_params # 用于定义 SCGI相关的参数。SCGI 是一种用于 Web 服务器和应用程序之间的通信协议, Nginx 和 SCGI 应用程序之间的通信顺畅,提高应用的性能和稳定性。
etc/nginx/nginx.conf # 主配置文件,定义了 Nginx 的全局配置,包括 HTTP、事件处理、日志等。
etc/ngin/conf.d/ # 子配置文件(虚拟主机,负载均衡等配置)
usr/sbin/nginx # 可执行文件
usr/sbin/koi-win # 定义了从 KOI8-R 编码到 Windows-1251 编码的转换表
usr/sbin/koi-utf # 定义了从 KOI8-R 编码到 UTF-8 编码的转换表
usr/sbin/win-utf # 定义了从 Windows-1251 编码到 UTF-8 编码的转换表
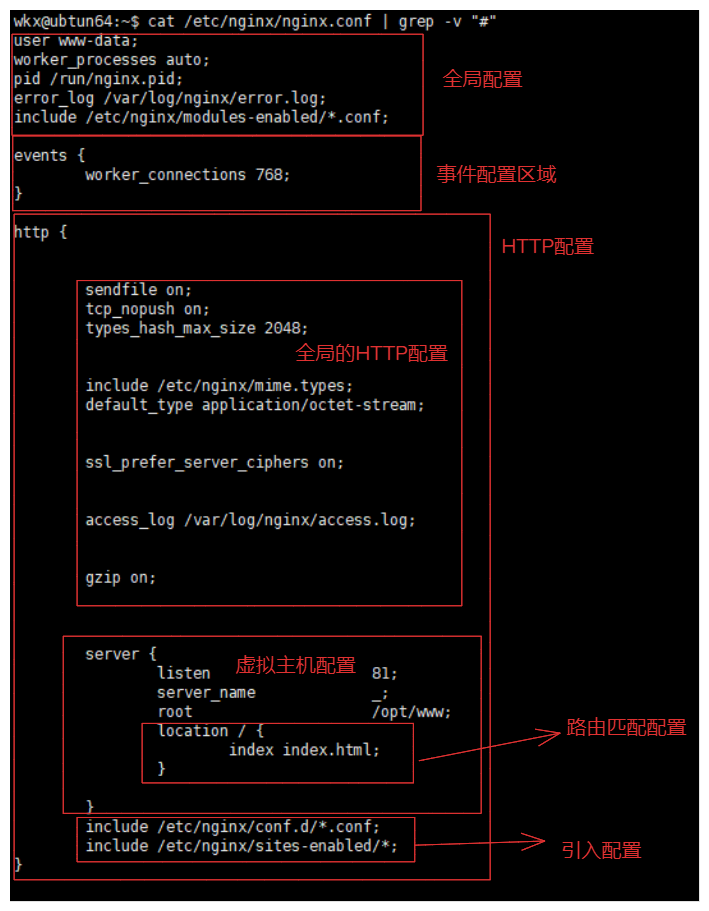
2.Nginx的配置区域
区域说明:
- 全局配置(影响整个nginx的整体运行指令)
- 事件配置区域(该区域定义了事件模块的配置,主要影响 Nginx 的并发处理能力)
- HTTP配置(定义HTTP模块的全局配置以及虚拟主机配置)
- 全局的HTTP配置(如
include mime.types(引入 MIME 类型映射表)、default_type(默认文件类型)、sendfile(启用文件传输优化)、keepalive_timeout(长连接超时时间)等。)- 虚拟主机配置(定义了虚拟主机的配置,包括监听端口、域名、访问日志、错误日志等。)
- 路由匹配配置(用于定义对特定 URL 路径的处理规则,例如静态文件服务、反向代理等。)
- 上游服务器配置(定义了后端服务器组,用于负载均衡和反向代理)
- 其他配置
stream上下文:用于配置 TCP/UDP 流的代理。types上下文:定义文件扩展名与 MIME 类型的映射。if上下文:用于条件判断,根据条件执行特定的指令
配置区域:
文档:
- 中文:https://wizardforcel.gitbooks.io/nginx-doc/content/index.html
- 原文档:https://nginx.org/en/docs/index.html
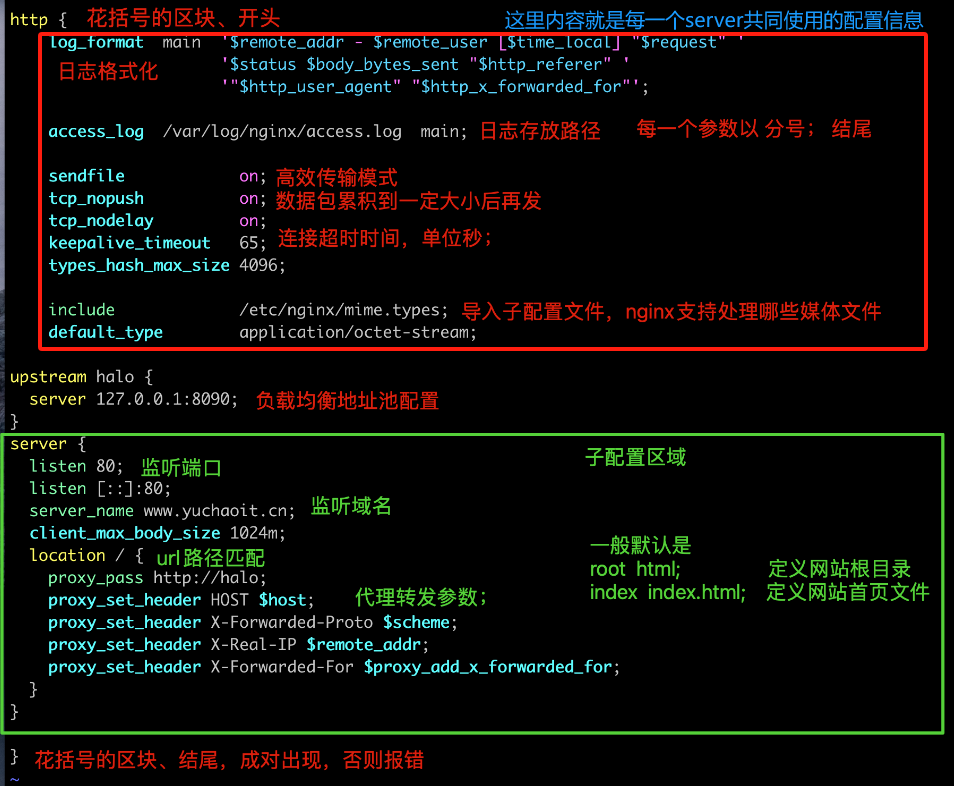

2-1.全局区域配置(main)
文档地址:
https://nginx.org/en/docs/ngx_core_module.html
常用指令:
worker_connections 是 events的参数
例如:
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
| 常用指令 | 指令作用 |
|---|---|
| user | 指定 Nginx 工作进程运行的用户和用户组。例如:设置用户与用户组相同:user op01;,设置用户与用户组不同:user op01 dev02。可以使用ps -eo uid,gid,comm 进行确认当前nginx的工作进程的用户与用户组。 |
| daemon | 控制 Nginx 是否以守护进程模式运行。1.daemon:on;守护进程模式在后台运行,默认。 2.daemon:yes非守护进程模式运行,会在前台运行(终端)。 |
| pid | 指定 Nginx 的 PID 文件路径。例如:/var/run/nginx.pid |
| lock_file | 指定锁文件的路径(用于防止多个 Nginx 实例同时运行)默认:/var/run/nginx.lock 或者 /var/lock/nginx.lock 注意:当前是特定配置指令。 |
| error_log | 定义错误日志的路径和日志级别,例如:logs/error.log error;除了支持mian区域,还支持: http, mail, stream, server, location区域。在main区域配置未被覆盖的模块和虚拟主机的错误日志记录。 |
| worker_processes | 设置工作进程的数量。也就是实际的的进程数量。例如:worker_processes: 1; 当前的工作进程就是1,worker_processes: auto;设置可以让让 Nginx 自动检测 CPU 核心数量,并为每个核心分配一个工作进程。 |
| worker_cpu_affinity | 将工作进程绑定到特定的CPU核心上,需要与worker_processes配合。例如:worker_cpu_affinity 0001 0010 0100 1000;将 4 个工作进程分别绑定到 4 个 CPU 核心,使用worker_cpu_affinity auto; (1.9.10才支持)自动绑定工作进程的CPU核心。 |
| worker_rlimit_nofile | 设置每个工作进程能打开的最大文件描述符号数量。如果不设置有 ulimit -n系统默认配置。需要与worker_connections参数配合是这个参数的两倍。例如:worker_connections:1024; worker_rlimit_nofile:worker_connections*2=2048。 |
| worker_priority | 设置工作进程的优先级。范围-20 - 20 之间,负数越高优先级越高。操作系统会优先级来分配CPU的时间片,优先级越高Nginx工作进程就会获取更多的CPU时间片。 |
| timer_resolution | 设置定时器的分辨率。默认:timer_resolution:0;即每次接收到内核事件时都会调用。例如:timer_resolution 100ms;只会在每 100 毫秒内调用一次gettimeofday(),而不是每次接收到内核事件时都调用。对定时器精度要求不高,可以考虑使用该指令优化性能。 |
| env | 设置环境变量。除了支持mian区域,还支持: http, mail, stream, server, location区域。例如:env nginx001=nginx002 |
| events | 事件区域的指令配置。 |
| include | 导入其他文件的配置到配置中。例如:include mime.types; |
# 补充点:
1.worker_cpu_affinity 与 worker_processes参数的说明:
如果只使用 worker_processes: auto; 也是可以的,那么工作进程直接由CPU自行调度使用,作系统会根据当前的负载情况和调度策略,动态地将工作进程分配到可用的 CPU 核心上。# 适用于通用场景
CPU那么就会出现当前情况:
worker_processes: 5; 就会出现 'CPU01 上有 3 个工作进程','CPU02 上有 2 个工作进程','其他 CPU 核心上没有工作进程',在低负载的情况下不会有很大的影响,但是在高负载的情况下性能会受到影响。
# 建议:这样可以使用CPU核心最大化。
worker_processes: auto;
worker_cpu_affinity: auto;
2.worker_rlimit_nofile
文件描述符号:操作系统用于访问文件和网络连接的资源。
需要与worker_connections(evnets配置的参数)参数配合,worker_rlimit_nofile的设置的值最少是worker_connections的两倍。
3.timer_resolution
说明:用于控制工作进程(worker process)中定时器的分辨率。它的主要作用是减少工作进程对 gettimeofday() 系统调用的频率,从而优化性能。
gettimeofday():用于获取当前时间,提供了高精度的时间信息,通常用于需要精确时间戳的场景。
# 注意事项:
1.如果你的应用对定时器精度要求不高,可以考虑使用该指令优化性能。
2.高并发并且不要求定时器精度。可以考虑设置一个较大的时间间隔。
3.该指令在大多数现代操作系统中有效,但具体效果可能因系统而异。
4.env注意事项:
1.Nginx 内部使用的环境变量(如 NGINX_*)通常用于特定的内部机制,用户不应直接设置这些变量。
2.某些环境变量可能只在特定模块中有效,或者在模块初始化时检查,因此在运行时通过 env 设置可能不会生效
3.获取借助外部攻击(如 envsubst)在启动 Nginx 之前动态生成配置文件。
2-2.事件区域配置(events)
文档地址:
https://nginx.org/en/docs/ngx_core_module.html
例如:
events {
worker_connections 1024; # 每个工作进程的最大连接数,只需要设置这个配置即可,其他的配置使用默认的就行除非有特殊需求。
}
# 关于惊群现象说明:
多个进程或者线程同时等待一个事件时,当该事件发生时,所有等待的进程或线程都会被唤醒,但最终只有一个进程或线程能够成功处理该事件,其他进程或线程则会重新进入休眠状态。浪费资源。
# 注意:
只需要设置worker_connections配置即可,其他的配置使用默认的就行除非有特殊需求。这些默认值通常已经经过优化,适用于大多数场景。
| 指令 | 说明 |
|---|---|
| worker_connections | 设置工作进程的最大连接数,也就是说当前工作进程最大并发数量。例如:worker_connections:1024; |
| use | 指定使用的事件驱动模型。默认:Nginx 会自动选择最适合当前操作系统的事件驱动模型。相关参数select,poll,kqueue ,epoll,/dev/poll ,eventport ,例如:use epoll; |
| accept_mutex | 控制是否启用连接序列化,以防止“惊群”现象。默认值:on,开启后则工作进程将依次接受新连接。例如:accept_mutex on。 |
| multi_accept | 控制是否允许一个工作进程同时接受多个新连接。默认值:off,当设置为 on 时,一个工作进程可以同时接受多个新连接,而不是每次只接受一个。例如:multi_accept on; |
2-3.HTTP配置区域(http)
# 说明:
这些参数适用于HTTP区域内容全部的虚拟主机。使用的模块:ngx_http_core_module,这个模块是nginx的核心模块,提供HTTP服务的功能和配置指令,这些指令用于全局HTTP行为,适用于全部的服务器与虚拟主机,属于NGINX默认自带的,无需安装。
例如:
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
client_max_body_size 8m;
large_client_header_buffers 4 64k;
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 5;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
server_tokens off;
autoindex on;
index index.html index.htm;
}
# 注意下面的指令包含的模块如下:
ngx_http_gzip_module
ngx_http_core_module
ngx_http_log_module
ngx_http_charset_module
ngx_http_headers_module
ngx_http_autoindex_module
ngx_http_limit_conn_module
ngx_http_proxy_module
# 这些内部模块的指令参数可以支持在HTTP区域或者server区域或者loaction区域使用,需要查看文档确定。
| 参数指令 | 说明 | 使用 |
|---|---|---|
| server_tokens | 禁止在错误页面和响应头中显示 Nginx 版本信息。默认server_tokens:on;。在访问时,会在响应头中显示Server属性上显示当前nginx版本。 |
server_tokens:off; |
| lingering_close | 控制 Nginx 关闭客户端连接的方式,默认:lingering_close:on;。参数说明(on,off,always):on会启用规则预测客户端是否可能发送更多的数据,如果可能那么就会等待处理这些数据,然后关闭连接,保持客户端兼容性,但可能会消耗更多资源。off会立即关闭连接,不会等待客户端发送更多数据,导致客户端收下RST报文,从而忽略服务端的错误信息,这样设置不推荐,可能会破坏协议。always无条件地等待并处理客户端发送的额外数据。这可以进一步提高客户端兼容性,但可能会导致更多的资源消耗。 |
lingering_close:on; |
| lingering_time | 在关闭连接前处理客户端额外数据的总时间,默认:lingering_time:30s;只有lingering_close开启这个参数生效。 |
lingering_time:30s; |
| lingering_timeout | 等待客户端更多数据到来的最大时间,默认:lingering_timeout:5s;只有lingering_close开启这个参数生效。 |
lingering_timeout:5s; |
| client_body_timeout | 读取请求体数据的超时时间。默认:client_body_timeout 60s;。在nginx接受到请求数据后,客户端没有在发送请求任何数据,就关闭连接返回超时错误(nginx接受请求体一刻开始计算)。 |
正常:client_body_timeout:60s;大文件上传:client_body_timeout:120s; |
| client_body_buffer_size | 设置读取客户端请求体的缓冲区大小。默认:32位平台默认是client_body_buffer_size 8k;, 64位平台是client_body_buffer_size 16k;。请求的数据写入到内存的缓冲区中,减少磁盘I/O操作。 |
正常:client_body_buffer_size 32k;大文件上传:client_body_buffer_size 128k; |
| client_max_body_size | 允许的最大请求体大小。默认:client_max_body_size:1m;,客户端请求携带数据的大小。 |
大文件:client_max_body_size 100M; |
| client_header_buffer_size | 读取客户端请求头缓冲区大小,默认:client_header_buffer_size 1k;。如果请求头的包含长的Cookie或者其他,可以以适当的增加大的缓冲区。不能超过large_client_header_buffers配置单个缓冲区的大小。 |
client_header_buffer_size 32k; |
| client_header_timeout | 读取客户端请求头的超时时间,默认:client_header_timeout 60s;。客户端在指定时间内没有发送完整的请求头,理大量慢速客户端请求的应用,可以适当增加这个值。 |
client_header_timeout 60s; |
| large_client_header_buffers | 用于存储大型请求头的缓冲区数量和大小。默认:large_client_header_buffers 4 8k;4个缓冲区,每个缓冲区大小为8kb。 |
large_client_header_buffers 4 64k; |
| send_timeout | nginx向客户端发送响应数据的超时时间。默认:send_timeout 60;,如果客户端没有在60秒内接受到数据,nginx就会认为客户端已经断开连接,并且会关闭当前连接。针对网络差,数据传输慢,大文件可以将当前参数设置时间长一些。 |
send_timeout 60; |
| reset_timedout_connection | 用于控制当连接超时是否重置连接。当客户端与服务器之间的连接超过了预设的超时时间,Nginx 会自动关闭连接。默认:reset_timedout_connection off;。off表示当连接超时时,nginx不会发送 RST 包,而是按照正常的 TCP 断开流程处理。on向客户端发送一个 TCP RST 包,直接重置连接,而不是走正常的四次挥手断开连接。 |
reset_timedout_connection off; |
| tcp_nodelay | 禁用 Nagle 算法,确保数据包立即发送,而不是等待缓冲区填满或确认收到之前的包。默认:tcp_nodelay on;。适用于实时性高并发场景。 |
tcp_nodelay on; |
| tcp_nopush | 在 Linux 上启用 TCP_CORK 选项,将多个小数据包合并为一个较大的数据包发送,减少网络开销。默认:tcp_nopush off;适用于大量数据或者静态文件,提高传输效率。 |
tcp_nopush off; |
| sendfile | 启用或者禁用零拷贝,用于高效传输文件内容。默认:sendfile off;。适用于静态文件传输,css,js等。 |
sendfile off; |
| sendfile_max_chunk | 优化传输大文件时,防止将整个工作进程给占用。默认:sendfile_max_chunk 2m;。0代表没有限制。可以优化 Nginx 在处理大文件时的行为,防止一个连接独占工作进程,公平的分配资源,从而提高整体性能。2m指sendfile() 调用传输的最大数据量为 2MB。 |
sendfile_max_chunk 2m; |
| keepalive_timeout | 设置客户端与服务端连接的超时时间。默认:keepalive_timeout 75s;。超时时间特指 HTTP Keep-Alive 模式下的连接保持时间,如果超时,服务器就会关闭连接,防止频繁的建立关闭TCP连接,消耗资源。 |
keepalive_timeout 75s; |
| keepalive_requests | 控制HTTP Keep-Alive 连接服务器请求的最大数量,当达到最大数量连接关闭。默认:keepalive_requests 1000;。当客户端通过HTTP Keep-Alive发送了1000个请求,就会关闭这个链接。如果发送了1001个就会对创建一个新的连接,重新从1开始计算。 |
keepalive_requests 1000; |
| open_file_cache | 设置文件描述符缓存,用于缓存文件元数据和文件描述符,减少对磁盘的访问次数,提高文件读取效率。默认:open_file_cache off;。max设置缓存最大文件元数据数值,inactive设置文件在缓存中保存不活跃时间,30s内没有访问就移除缓存。 |
open_file_cache max=10000 inactive=30s; |
| open_file_cache_valid | 设置验证缓存中文件元信息的时间间隔。默认:open_file_cache_valid 30s;需要开启open_file_cache才会生效。会检查缓存中的文件元数据是否最新的,不是就会更新缓存。 |
open_file_cache_valid 60s; |
| open_file_cache_min_uses | 设置文件元数据在缓存中保持的最小使用次数。默认:open_file_cache_min_uses 1;。需要开启open_file_cache才会生效。如果文件在open_file_cache设置的inactive时间内少于open_file_cache_min_uses值就会被移除缓存。 |
open_file_cache_min_uses 2; |
| open_file_cache_errors | 控制是否缓存文件元数据访问错误。默认:open_file_cache_errors off;。需要开启open_file_cache才会生效。会缓存文件访问错误信息进行记录,防止再次访问错误的元数据。 |
open_file_cache_errors on; |
| gzip | 开启,对响应数据的压缩,提高相应效率。默认:gzip off; |
gzip off; |
| gzip_vary | 在响应头中添加 Vary: Accept-Encoding,以便代理服务器(如 CDN)可以根据客户端是否支持 Gzip 压缩来缓存不同的响应。默认:gzip_vary off; |
gzip_vary off; |
| gzip_proxied | 控制是否对代理请求进行 Gzip 压缩。默认:gzip_proxied off;参数off(关闭),expired(如果响应标头包含“Expires”字段,且该字段的值禁用缓存,则启用压缩;),no-cache(如果响应标头包含带有“no-cache参数的“Cache-Control”字段,则启用压缩),no-store(如果响应标头包含带有“no-store”参数的“Cache-Control”字段,则启用压缩),private(如果响应标头包含带有“private”参数的“Cache-Control”字段,则启用压缩),no_last_modified(如果响应标头不包括“Last Modified”字段,则启用压缩),no_etag(请求头中不包含ETag字段启用压缩),auth(请求头中包含Authorization字段启用压缩),any(为所有代理请求启用压缩) |
gzip_proxied off; |
| gzip_comp_level | 设置 Gzip 压缩级别,范围从 1(最快,压缩率最低)到 9(最慢,压缩率最高)。默认:gzip_comp_level 1;。压缩等级越高压缩率越高,但是效率会慢。 |
gzip_comp_level 1; |
| gzip_types | 指定需要进行 Gzip 压缩的 MIME 类型。默认:gzip_types text/html; |
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript; |
| gzip_min_lengt | 设置压缩的最小长度,长度由响应头中的Content-length字段确认,默认:gzip_min_lengt 20;。注意:20是20字节的意思。可以控制不对小文件进行压缩,防止增加CPU负载。 |
gzip_min_length 1k; |
| gzip_buffers | 设置压缩的缓冲区的数量和大小,取决于当前操作系统。默认:gzip_buffers 16 8k; |
gzip_buffers 16 8k; |
| gzip_http_version | 设置压缩的最低的版本。默认:gzip_http_version 1.1; |
gzip_http_version 1.1; |
| gzip_disable | 根据条件禁止压缩。 | gzip_disable MSIE [4-6]\.; |
| log_format | 设置日志的格式。 | log_format combined '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"'; |
| access_log | 设置日志写入的位置和使用什么样的日志格式(log_format配合使用)。 | access_log logs/access.log combined; |
| error_log | 设置作为日志的存存储位置与级别。使用方式:error_log path 级别 |
error_log logs/error.log error |
| charset | 设置字符集。会在响应头Content-Type中进行显示,默认:charset off;。 |
charset utf-8; |
| error_page | 定义显示错误的uri(错误的显示的页面)。设置方式:1.响应静态的错误页面。2.响应uri。 | error_page 404 /404.html; error_page 500 502 503 504 /50x.html; |
| types_hash_max_size | 增加哈希表的最大大小,减少哈希冲突,提高查找速度(值越高速度越快,消耗的内存越大。)。默认:types_hash_max_size 1024; |
types_hash_max_size 1024; |
| types_hash_bucket_size | 增加哈希表的桶大小,提高哈希表的存储能力,减少冲突(桶越大,存储的键值对就越多,消耗内存越大。)。默认:types_hash_bucket_size 64; |
types_hash_bucket_size 64; |
| add_header | 添加自定义的响应头,在响应头中进行显示。使用:add_header name value |
add_header xxx 123; |
| root | 设置请求的跟目录(基础路径)。一般作用与server/location区域。例如:root /opt/html/ |
root /opt/html/; |
| index | 设置请求的主页。一般作用与server/location区域,需要配合root指令使用。例如:index index.$geo.html index.html |
index index.html; |
| server | 设置虚拟主机配置。只能作用于http区域。 | |
| try_files | 指定顺序检查文件,并且使用第一个找到的文件进行请求处理。例如: try_files $uri $uri/index.html $uri.html =404;。根据指令值顺序找到文件,并且返回。相对于index指令来说,更灵活处理动态请求与静态文件。 |
try_files $uri $uri/index.html $uri.html =404; |
| default_type | 设置默认的MIME类型。default_type <MIME-type>; |
default_type text/html; |
| include | 用于包含其他配置文件的内容。可以将配置进行拆分成多个小文件,通过include进行导入,便于管理和维护。使用:include <file>; |
include conf.d/*.conf; |
# 参数说明:
1.client_max_body_size与client_body_buffer_size与client_body_timeout
# 针对大文件上传优化
client_max_body_size 100M; # 允许的最大请求体大小
client_body_buffer_size 128k; # 内存缓冲区大小
client_body_timeout 120s; # 从客户端读取请求体的超时时间
2.large_client_header_buffers 与 client_header_buffer_size 说明:
# 优化请求头大小,针对大的请求头进行优化
large_client_header_buffers 4 64k; # 4 个缓冲区,每个缓冲区大小为 64K
client_header_buffer_size 32k; # 初始缓冲区大小,设置的缓冲区不能超过64kb
# 为什么large_client_header_buffers 4 64kb,多个缓冲区和缓冲区大小?
因为:处理大型请求头的缓冲区数量和大小。会根据请求头的实际大小动态分配缓冲区,确保请求头数据可以被完整存储。
如果请求头的大小为 72KB,Nginx 会这样处理:
第一个缓冲区:使用一个 64KB 的缓冲区来存储前 64KB 的数据。
第二个缓冲区:使用第二个 64KB 的缓冲区来存储剩余的 8KB 数据。
3.send_timeout与reset_timedout_connection进行配合使用
# 优化连接资源
reset_timedout_connection 开启后可以解决
1.当前网络不稳当导致确认接受数据时,可以减少服务器端处于等待状态的连接数量。
2.在高并发场景下,服务器会因为大量的处于等待连接而导致资源耗尽,可以及时的释放一些资源。
send_timeout 10s; # 设置发送超时时间为 10 秒
reset_timedout_connection on; # 启用重置超时连接
# 注意:
1.如果开启reset_timedout_connection,如果用户的网络环境差,就会导致用户无法连接到服务器(一直处于重置连接)
2.使用reset_timedout_connection参数需要配合send_timeout进行使用,适当的减少send_timeout的时间('避免服务等等待时间过长'),可以有效利用reset_timedout_connection('减少time_wait状态TCP链接,释放更多的资源')参数对服务器进行优化。
4.keepalive_requests 与 keepalive_timeout
# 优化连接资源
# keepalive_requests 1000; 解释:
当客户端链接发送请求到服务器,会建立一个 TCP 连接。每一次客户端发送一个请求,就会被nginx计数,当达到1000时,就会关闭这个连接(连接的寿命结束),重新建立一个新的 TCP 连接开始重新计数。
# keepalive_requests 优点:
1.连接复用,减少开销。
2.限制连接请求数量,防止连接占用时间长,避免资源泄露。
# 注意:
使用 keepalive_requests 需要与 keepalive_timeout进行配合使用。
keepalive_requests 1000; # 每个 Keep-Alive 连接最多处理 1000 个请求
keepalive_timeout 60s; # Keep-Alive 连接的超时时间为 60 秒
# 解释:
在60内可以最大接受客户端请求1000个,如果超出会关闭当前连接,新建连接重新计算。如果60秒内没有1000,时间到后(这个时间内没有新的请求)连接也会关闭。
5.open_file_cache 与 open_file_cache_valid 与 open_file_cache_min_uses 与 open_file_cache_errors
# 优化静态资源
说明:
1.合理配置这些指令可以显著提高 Nginx 在处理静态文件时的性能,减少磁盘 I/O 操作,提高响应速度。
2.特别适用于静态文件服务,如图片、CSS、JavaScript 等。
3.open_file_cache 的 max 值应根据服务器的文件描述符限制(ulimit -n)进行调整,以避免资源耗尽。
open_file_cache max=10000 inactive=30s; # 默认关闭
open_file_cache_valid 60s; # 需要 open_file_cache 开启后生效,
open_file_cache_min_uses 2; # 需要 open_file_cache 开启后生效
open_file_cache_errors on; # 需要 open_file_cache 开启后生效
open_file_cache_valid 60s; 解释:
每60s就会检查缓存中的文件元数据是不是最新的,如果不是就会更新。
open_file_cache_min_uses 2; 解释:
会根据 inactive=30s,30秒内文件有没有使用 2 次,如果没有就会移除缓存。
6.gzip相关
来源于 ngx_http_gzip_module 模块,主要作用是将数据进行压缩传输。一般设置HTTP区域中,让全局虚拟机使用。
gzip on; # 启用 Gzip 压缩
gzip_vary on; # 添加 Vary: Accept-Encoding
gzip_proxied any; # 对所有代理请求进行 Gzip 压缩
gzip_comp_level 5; # 设置压缩级别为 5
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript; # 设置需要压缩的 MIME 类型
gzip_min_length 1k; # 设置最小长度为 1KB
gzip_buffers 16 8k; # 设置 16 个缓冲区,每个缓冲区大小为 8KB
gzip_http_version 1.0; # 支持 HTTP/1.0 和更高版本
gzip_disable "msie6"; # 禁用对 MSIE 6 的 Gzip 压缩
注意:
1.性能影响:虽然 Gzip 压缩可以减少传输数据量,但压缩和解压过程会消耗 CPU 资源。在高并发场景下,需要权衡压缩带来的性能提升和 CPU 负载。
2.静态文件:对于静态文件,可以预先压缩并存储压缩后的文件,以减少运行时的压缩开销。
3.客户端支持:确保客户端支持 Gzip 压缩。大多数现代浏览器都支持 Gzip 压缩,但某些旧版本浏览器可能不支持。
7.charset相关
来自于ngx_http_charset_module模块,主要作用设置字符集的格式。
8.关于 types_hash_max_size 与 types_hash_bucket_size 参数
作用:
为了快速处理静态数据集,例如服务器名称, 映射指令的值, MIME 类型,请求头字符串的名称 nginx 使用哈希表。
例如:
nginx会使用哈希表存储MIME理性映射。哈希表通过哈希函数将键(如文件扩展名)映射到一个桶(bucket)中,然后在桶中存储对应的值(如 MIME 类型)。
目的:
1.减少哈希冲突:当两个不同的键通过哈希函数映射到同一个桶时,就会发生哈希冲突。哈希冲突会降低查找效率,因为需要在桶中进行额外的查找操作。
2.加快查找速度:指从哈希表中查找一个键值对的速度。减少哈希冲突可以提高查找速度,因为冲突越少,查找操作越直接。
2-4.Server配置区域(server)
server 区域是 Nginx 配置文件中定义虚拟主机的配置块,可以包含多个字段,用于配置特定虚拟主机的行为。通过合理配置这些字段,可以灵活地管理虚拟主机的请求处理、错误页面、代理、重写等行为。
配置示例:
server {
listen 80;
server_name example.com www.example.com;
root /var/www/html;
index index.html index.htm;
location / {
try_files $uri $uri/ /index.html;
}
location /api {
proxy_pass http://backend;
}
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html;
add_header X-Frame-Options SAMEORIGIN;
}
| 指令 | 说明 | 示例 |
|---|---|---|
listen |
指定配置的服务器的监控端口。使用:listen <port> [default_server]; |
listen 80; |
server_name |
指定域名或者IP地址。使用:server_name <domain> [alias ...]; |
server_name example.com www.example.com; |
root |
配置基础路径,nginx会与root配置的路径与location路径进行拼接,找到指定的文件位置(接口)。使用:root <path>; |
root /var/www/html; |
index |
设置默认的索引文件。使用:index <file> [file ...]; |
index index.html index.htm; |
location |
定义特定路由处理规则。使用:location [modifier] <path> { ... } |
location / { try_files $uri $uri/ /index.html; } |
error_page |
定义错误页面处理规则。使用:error_page <code> [code ...] <uri> [uri ...]; |
error_page 500 502 503 504 /50x.html; |
return |
直接返回指定的HTTP状态码与响应内容。使用:return <code> [text]; |
return 503 "Site is under maintenance"; |
rewrite |
重写URI。使用:rewrite <regex> <replacement> [flag]; |
rewrite ^/old/(.*)$ /new/$1 permanent; |
proxy_pass |
请求代理到后端。使用:proxy_pass <url>; |
location /api { proxy_pass http://backend; } |
ssl_certificate |
设置ssl证书。使用:ssl_certificate <path>; |
ssl_certificate /etc/nginx/ssl/example.com.crt; |
ssl_certificate_key |
设置私钥文件路径。使用:ssl_certificate_key <path>; |
ssl_certificate_key /etc/nginx/ssl/example.com.key; |
add_header |
添加请求头。使用:add_header <name> <value> [always]; |
add_header X-Frame-Options SAMEORIGIN; |
try_files |
按顺序查找文件,并返回第一个找到的文件或进行内部重定向。使用:try_files <file> [file ...] <uri>; |
try_files $uri $uri/ /index.html; |
location说明:
可以设置端口,地址,UNIX套接字的路径。只指定地址或者port。地址可以是主机名称。
# 例如:
listen 127.0.0.1:8000;
listen 127.0.0.1;
listen 8000;
listen *:8000;
listen localhost:8000;
listen unix:/var/run/nginx.sock; # 套接字
指定ipv6
listen [::]:8000;
listen [::1];
关于location的参数:
default_server:指定默认的服务器,当请求的域名或者ip没有匹配到时server_name,nginx就会将请求转发到这个配置参数的服务器上
listen 80 default_server;
ssl : 指定服务器监听的端口号,并启用 SSL/TLS 支持。
listen 443 ssl;
backlog:设置监听队列的最大长度,即未完成的 TCP 连接的最大数量。
listen 80 backlog=512;
bind:显式绑定到指定的 IP 地址和端口。# 默认是隐式绑定全部的网络。
listen 192.168.1.1:80 bind; # 只会监听192.168.1.1,不会监听其他的网站(在多网络服务器很有用)。
注意:
bind个参数不是必要的,如果真需要绑定指定的网络,可以:listen 192.168.1.1:80;
http2:启用 HTTP/2 协议。需要正常配置SSL/TLS,才能使用(HTTP/2 是通过 SSL/TLS 加密来实现的)。
listen 443 ssl http2;
ipv6only:控制 IPv6 地址是否仅用于 IPv6 连接,还是同时用于 IPv4 和 IPv6 连接。
语法:listen <port> ipv6only=on|off
listen [::]:80 ipv6only=on;
reuseport:启用 SO_REUSEPORT 选项,允许多个进程或线程绑定到同一个端口,提高性能。
listen 80 reuseport;
# 目的:提高服务器的并发处理能力和性能,特别是在多核系统上。
# 注意:
1.SO_REUSEPORT 选项需要操作系统支持。在 Linux 系统中,需要内核版本 3.9 或更高。
2.只有具有相同有效用户 ID 的进程才能绑定到同一个端口,以防止端口劫持。(nginx用户运行的,那么只能有nginx用户使用,其他的用户会被拒绝)
# 优点:
1.避免“惊群效应”:在多线程或多进程服务器中,避免多个线程或进程竞争同一个监听套接字,从而减少锁竞争。
2.内核层面负载均衡:内核会自动将传入的连接均匀分配给各个监听套接字,提高负载均衡效果。
3.提高性能:通过减少锁竞争和提高负载均衡,reuseport 可以显著提高服务器的性能,特别是在高并发场景下。
backlog:设置监听套接字的待处理连接队列的最大长度。。默认情况下,在FreeBSD、DragonFly BSD和macOS上,backlog设置为-1,在其他平台上设置为511。在高并发场景下,如果队列过小,就会导致连接被拒绝,增加这个值可以提高连接处理能力。
listen 80 backlog=1024;
# 待处理连接队列:
当客户端发起连接请求时,如果服务器当前正在处理其他连接,新的连接请求会被放入待处理连接队列中等待处理。
例如:listen 80 backlog=1024;
server虚拟机正在处理A请求,新的连接请求(尚未完成三次握手 的连接请求)就会放入队列中等待(1023)。如果队列满了(超出backlog值),新连接就会拒绝。
# 注意:
backlog 的值不能超过操作系统的 somaxconn 参数值。
sysctl -w net.core.somaxconn=65535 # 设置值。
3-4.关于配置文件顺序
# nginx加载配置文件时存在顺序的。
1.通过主配置文件的 'include' 指令进行加载。
include /etc/nginx/conf.d/*.conf;
2.指令包含的是一个目录,Nginx 会按照文件名的字母顺序加载文件。
/etc/nginx/conf.d/01-site1.conf # 先加载 01-site1.conf
/etc/nginx/conf.d/02-site2.conf # 后加载 01-site1.conf
# 加载指令块
1.全局指令
2.events 块
3.http 块
4.server 块
5.location 块
3.Nginx虚拟主机
虚拟主机的概念:
- 是 Web 服务器的一个功能,允许在同一个物理服务器上运行多个独立的网站或 Web 应用。每个虚拟主机都有自己的域名、IP 地址(可选)、文档根目录、配置文件等,从而实现资源的隔离和管理。
为什么配置虚拟主机:
- 资源共享:在一台物理服务器上运行多个网站,可以实现共享CPU,内存,磁盘。从而提高整体的使用率。
- 成本:通过一台物理服务器,运行多个网站,减少了硬件的成本。
- 隔离性:运行多个网站,它们之间的配置是独立的,相互之间不会有任何干扰。
- 灵活性:可以根据不同的网站,配置不同。
- 安全性:通过隔离不同网站的资源,可以提高安全性,防止一个网站的漏洞影响到其他网站。
虚拟主机的方式:
- 基于域名:基于域名的虚拟主机允许你在同一台服务器上为不同的域名提供不同的内容。
- 基于IP:基于 IP 地址的虚拟主机允许你在同一台服务器上为不同的 IP 地址提供不同的内容(需要虚拟主机分配一个IP,需要服务器有多个网卡【物理或者虚拟】)。
- 基于端口:允许在同一台物理服务器上不同的端口提供不同的内容,需要每个虚拟主机分配一个独立的端口。
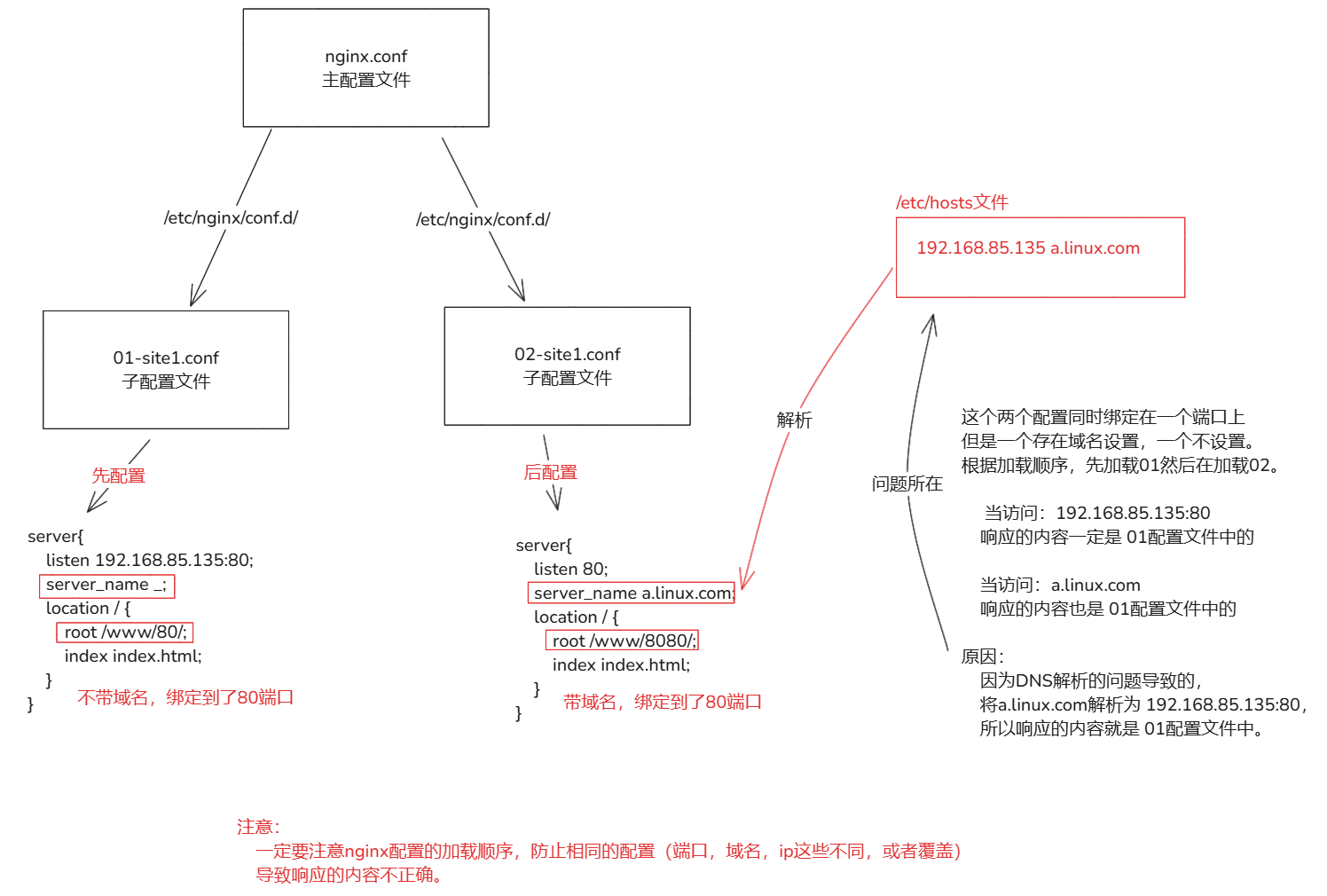
3-1.基于IP
1.添加一个虚拟的网卡,确保网卡没有被占用
ip addr add 10.0.0.88/24 dev ens33
2.创建配置文件
1. /etc/nginx/conf.d/88.conf
server {
listen 10.0.0.88:80;
server_name _;
root /www/88/;
location / {
index index.html;
}
}
1. /etc/nginx/conf.d/135.conf
server {
listen 192.168.85.135:80;
server_name _;
root /www/135/;
location / {
index index.html;
}
}
3.重启nginx,查看网络端口情况
sudo systemctl restart nginx
sudo netstat -tnlp4
4.访问
curl 192.168.85.135:80
curl 10.0.0.88:80
# 注意:为什么不同的ip可以绑定 80 端口
1.65535 个端口 是指单个 IP 地址上的可用端口号范围。
2.在多虚拟主机或多网卡的场景中,每个 IP 地址都可以独立使用这些端口
3.根据请求的 IP 地址将流量路由到对应的虚拟主机,因此可以使用相同的端口
# 端口补充,为什么是 65535 个端口
1.TCP 和 UDP 协议中,端口号是 16 位的无符号整数,所以是最大值: 2的16次方 -1 = 65535
2.端口的范围 1-65535。0号端口用于特殊目的,所以端口是 65535(需要减一的所在)
# 总结:
如果使用ip方式来创建nginx的虚拟机:
1.服务器需要有多个网卡,不然无法实现。
2.每个ip最大的端口数 65535,也就是说多网卡可以绑定端口取决于的网卡数 * 65535。
当使用ip方式创建时,会根据访问的不同ip地址,将请求数据转发到具体的网卡上。
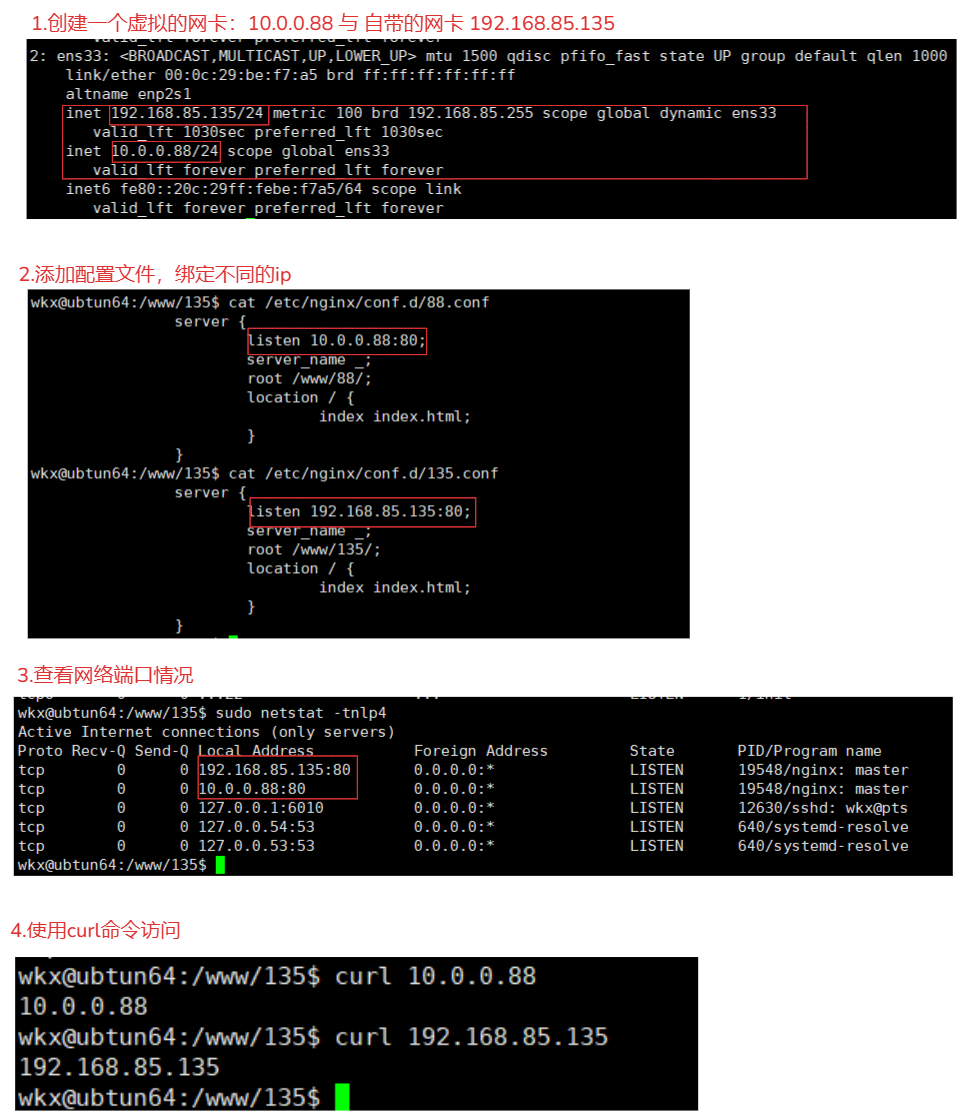
3-2.基于端口
# 基于端口的配置在生产环境比较少见,用于特殊场景,例如公司内部测试平台网站,使用特殊端口的后台,OA系统、网站后台,CRM后台等。
1.添加配置文件
vim /etc/nginx/conf.d/port.conf
server{
listen 10.0.0.88:8110; # 使用 8110 端口
server_name _;
location / {
root /www/8110/;
index index.html;
}
}
server{
listen 10.0.0.88:8112; # 使用 8112 端口
server_name _;
location / {
root /www/8112/;
index index.html;
}
}
2.重启查看网络端口信息
sudo systemctl restart nginx
sudo netstat -tnlp4
3.访问
curl 10.0.0.88:8112
curl 10.0.0.88:8110
# 使用场景:
1.同一个ip下的多个服务,当服务器只有一个ip时,可以通过不同的端口进行区分它们。
2.内部服务与外部服务的隔离,外部的服务可以通过标准的80/443端口,内部的后台服务可以通过8080/8081等。
3.测试与生产环境同存,在开发或者测试阶段,可以根据端口来区分,避免与生产环境冲突。
# 目的:
1.资源优化:
使用基于端口的虚拟主机可以在同一台服务器上运行多个服务,而无需为每个服务启动独立的 Nginx 进程,从而节省系统资源
2.灵活的配置:
通过配置不同的端口,可以灵活地为每个服务指定独立的配置文件和访问路径,便于管理和维护。
3.服务隔离:
每个服务通过不同的端口运行,彼此之间相互独立,互不干扰,这有助于提高系统的稳定性和安全性。
4.简化部署:
在同一台服务器上运行多个服务时,基于端口的虚拟主机可以简化部署过程,避免了为每个服务单独配置 IP 地址或域名的复杂性。
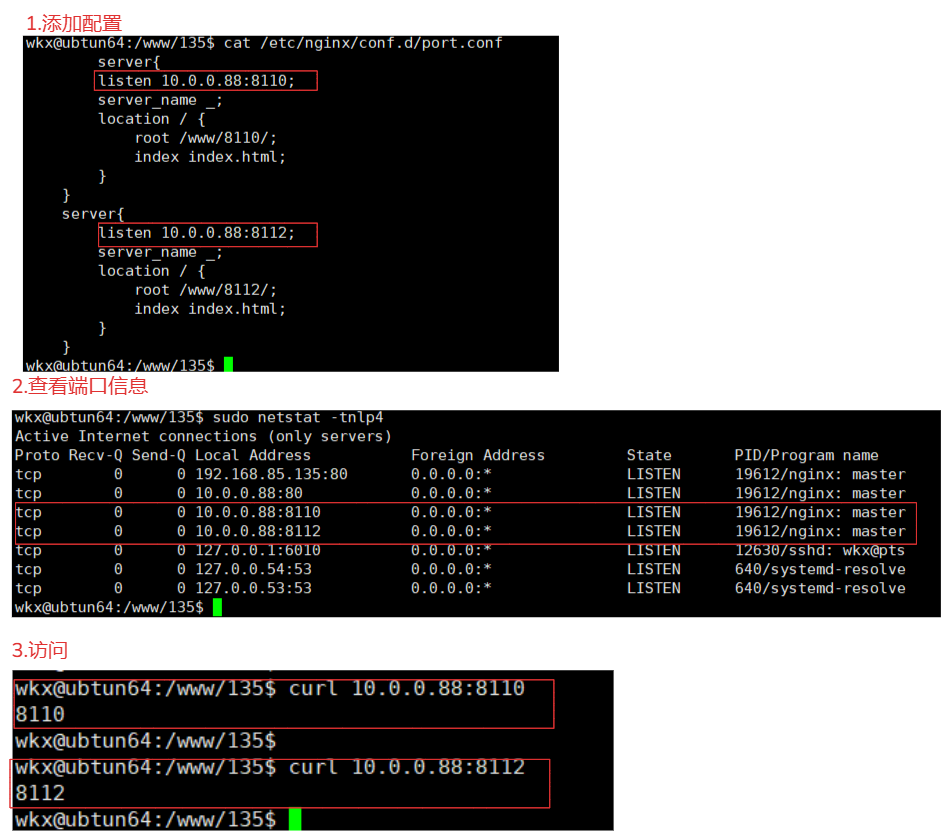
3-3.基于域名
1.编辑配置文件
# 设置一个 a.linux.com域名与b.linux.com
sudo vim /etc/nginx/conf.d/dnsname.conf
server {
listen 80;
server_name a.linux.com;
root /www/a/;
location / {
index index.html;
}
}
server {
listen 80;
server_name b.linux.com;
root /www/a/;
location / {
index index.html;
}
}
2.修改hosts文件,进行域名绑定ip,使用ping进行确定是否可以ping通。
192.168.85.135 a.linux.com b.linux.com
3.重启进行访问
sudo systemctl restart nginx
curl a.linux.com
curl b.linux.com
# 注意:
1.使用多域名的方式,它的工作原理是根据Host 请求头才是区分不同域名的关键,而端口只是通信入口。
2.通过 server_name 指令匹配请求中的 Host 请求头,从而将请求路由到正确的虚拟主机。
3.即使多个域名绑定到同一个端口,Nginx 也能够正确区分它们,不会发生冲突。
3.Nginx的Location
当前指令在:ngx_http_core_module 模块中。
location是nginx的核心重要功能,可以设置网站的访问路径,一个web server会有多个路径,那么location就得设置多个。
一般网站会基于动态请求,或者静态请求,也有根据业务,决定nginx的不同匹配规则。需要理解location的匹配规则,通过不同的规则方式实现业务。
文档:
https://nginx.org/en/docs/http/ngx_http_core_module.html#location
作用:
根据请求 URI 设置配置。
语法:
location 匹配规则 {
# 配置内容
}
3-1.匹配优先级
对比:
修饰符 类型 匹配方式 区分大小写 优先级 示例 备注 =精确匹配 完全匹配指定的 URI 是 最高 /exact只匹配完全相同的 URI,不匹配任何其他路径 ^~前缀匹配 匹配以指定路径开头的 URI 是 高(优先于正则匹配) /prefix、/prefix/abc匹配成功后不再匹配其他正则表达式 ~正则匹配 匹配符合正则表达式的 URI 是 中(按配置顺序) /regex、/abc/regex按配置文件中的顺序匹配 ~*正则匹配 匹配符合正则表达式的 URI 否(不区分大小写) 中(按配置顺序) /regex、/abc/regex按配置文件中的顺序匹配 顺序说明:
# 注意: 允许使用正则表达式符号。 # 在url匹配优先级时 1.先匹配有 符号(优先级) 如果没有执行第2步 2.再进行匹配到没有 符合 比如:指定url 如果没有指定第3步 3. 低级匹配 location / {} # 顺序: 1.只有当请求的 URI 完全等于指定的路径时才会匹配。# 精准匹配 location = /uri {} 2.前缀匹配 ^~ 开头(区分大小写)。 location ^~ /uri {} # 如果请求的 URI 以指定的路径开头,并且匹配成功后,Nginx 不会再去匹配其他正则表达式的 location 块,直接使用当前的 location 块处理请求。 3.前缀匹配 ~ 开头(区分大小写)。 location ~ /uri {} 4.前缀匹配 ~* 开头(不区分大小写)。 location ~* /uri {} 5.匹配以指定路径开头的 URI。 location /uri {} 6.匹配所有路径。# 匹配全部路径 location / {} # 它的优先级要高于 ~* 与 ~ 符号,因为/ 等同于 location /uri {} 这种方式。测试:
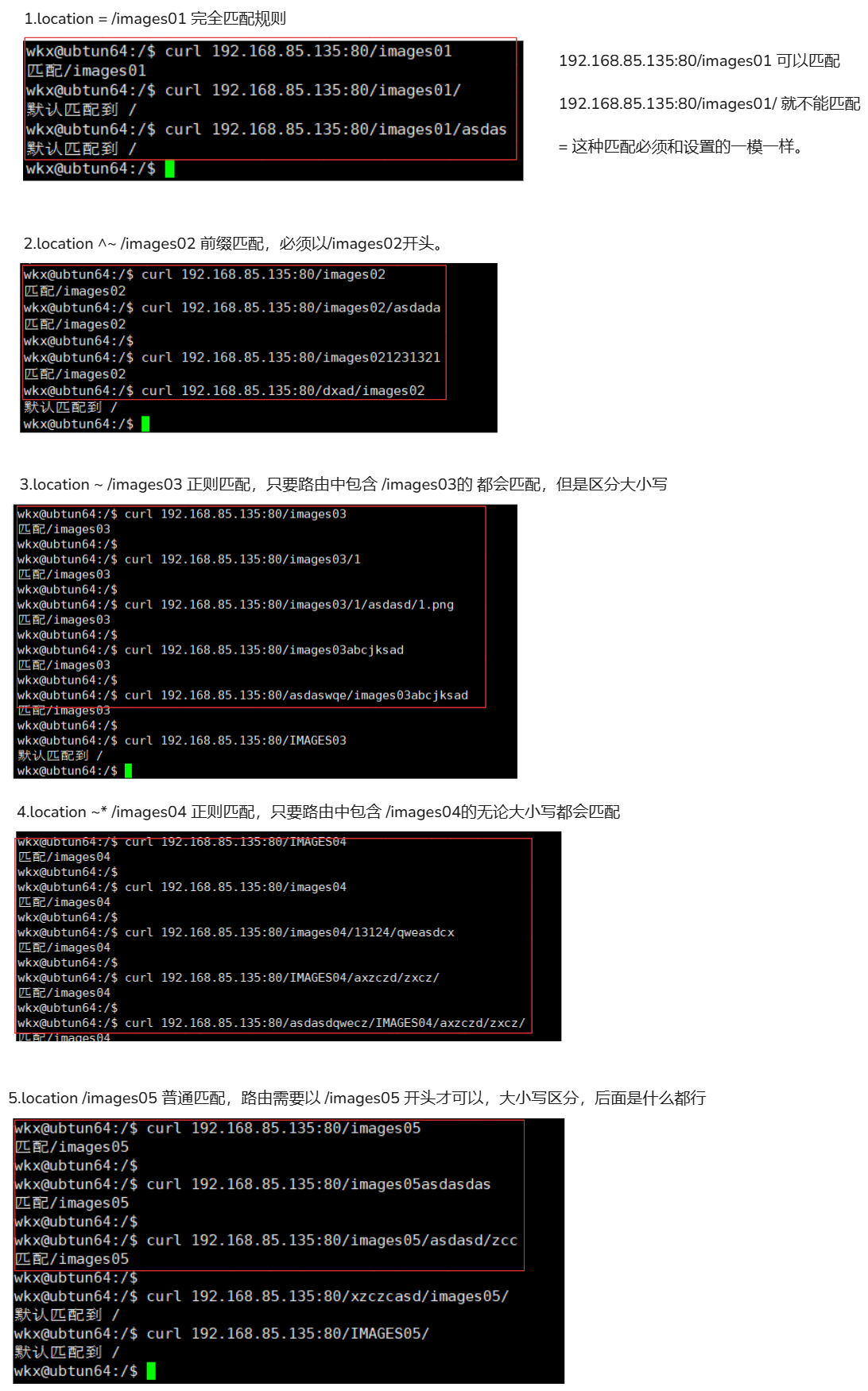
1.配置文件 server { listen 80; server_name _; location = /images01 { return 200 "匹配/images01 \n"; } location ^~ /images02 { return 200 "匹配/images02 \n"; } location ~ /images03 { return 200 "匹配/images03 \n"; } location ~* /images04 { return 200 "匹配/images04 \n"; } location /images05 { return 200 "匹配/images05 \n"; } location / { return 200 "默认匹配到 / \n"; } } 2.访问 1. location = /images01 # 属于完全匹配 # 后缀路由必须是 /images01 可以匹配,如果不是就不行。 curl 192.168.85.135:80/images01 # 不可以匹配 curl 192.168.85.135:80/images01/ curl 192.168.85.135:80/images01/asdas # 使用 = 属于完全匹配,多一个字符少一个字符都不行,必须与路由一模一样才行。 2. location ^~ /images02 # 前缀匹配 区分大小写 ^~ 开头 /images02 匹配的路由 开头必须是 /images02 # 可以匹配 curl 192.168.85.135:80/images02 # 因为 URI 以 /images02 开头。 curl 192.168.85.135:80/images02/asdada # 因为 URI 以 /images02 开头。 curl 192.168.85.135:80/images021231321 # 因为 URI 以 /images02 开头。 # 不能匹配 curl 192.168.85.135:80/dxad/images02 # 开头不是 /images02 无法匹配 curl 192.168.85.135:80/IMages02 # 区分大小写,所以无法匹配 # 使用 ^~ 正则匹配只要开头符合这个规则(/images02),那么无论你的路由是什么样子的都可以。 3.location ~ /images03 # 正则匹配 ~ 正则, ~ /images03 只要访问的路由中包含 /images03 那么就会匹配到当前 location # 可以匹配 curl 192.168.85.135:80/images03 # 因为 URI 包含 /images03 。 curl 192.168.85.135:80/images03/1 # 因为 URI 包含 /images03 。 curl 192.168.85.135:80/images03/1/asdasd/1.png # 因为 URI 包含 /images03 。 curl 192.168.85.135:80/images03abcjksad # 因为 URI 包含 /images03 。 curl 192.168.85.135:80/asdaswqe/images03abcjksad # 因为 URI 包含 /images03 。 # 不可以匹配 curl 192.168.85.135:80/IMAGES03 # 区分大小写 4. location ~* /images04 # 正则匹配 不区分大小写 ~* 正则,~* /images04 不区分大小写的正则匹配,只要规则中包含(/images04)就能匹配到 # 可以匹配 curl 192.168.85.135:80/asdasdqwecz/IMAGES04/axzczd/zxcz/ # 包含/images04大写的 curl 192.168.85.135:80/IMAGES04/axzczd/zxcz/ # 包含/images04大写的 curl 192.168.85.135:80/images04/13124/qweasdcx # 包含/images04 curl 192.168.85.135:80/images04 # 包含/images04 curl 192.168.85.135:80/IMAGES04 # 包含/images04大写的 5. location /images05 # 正常匹配路由,普通的路由。 # 可以匹配 curl 192.168.85.135:80/images05 # 以 /images05 开头 curl 192.168.85.135:80/images05asdasdas # 以 /images05 开头 curl 192.168.85.135:80/images05/asdasd/zcc # 以 /images05 开头 # 不可以 curl 192.168.85.135:80/xzczcasd/images05/ # 没有以 /images05 开头 curl 192.168.85.135:80/IMAGES05/ # 区分大小写 6. location / # 默认匹配 只要以上规则无法匹配到的都会到 / 匹配中。 如果没有其他更具体的 location 匹配规则,任何请求都会匹配到 location /。
3-2.支持的正则
| 则表达式 | 说明 |
|---|---|
^ |
匹配输入字符串的起始位置。例如:^/user 匹配以 /user 开头的 URI。 |
$ |
匹配输入字符串的结束位置。例如:\.html$ 匹配以 .html 结尾的 URI。 |
* |
匹配前面的字符零次或多次。例如:colou*r 匹配 color 或 colour。 |
+ |
匹配前面的字符一次或多次。例如:go+l 匹配 gol、gool、gooool 等。 |
? |
匹配前面的字符零次或一次。例如:apple(s)? 匹配 apple 或 apples。 |
. |
匹配除换行符之外的任何单个字符。例如:b.t 匹配 bat、but、b@t 等。 |
\ |
将后面接着的字符标记为特殊字符。例如:\.jpg$ 匹配以 .jpg 结尾的 URI。 |
\d |
匹配一个数字。例如:\d+ 匹配一个或多个数字。 |
{n} |
重复 n 次。例如:a{3} 匹配 aaa。 |
{n,} |
重复 n 次或更多次。例如:b{2,} 匹配 bb、bbb、bbbb 等。 |
{n,m} |
重复 n 到 m 次。例如:c{2,4} 匹配 cc、ccc、cccc。 |
[] |
定义匹配的字符范围。例如:[aeiou] 匹配任何一个元音字母;[0-9] 匹配任何一个数字。 |
[c] |
匹配单个字符 c。例如:[abc] 匹配 a、b 或 c。 |
[a-z] |
匹配 a-z 小写字母的任意一个。 |
[a-zA-Z0-9] |
匹配所有大小写字母或数字。 |
() |
表达式的开始和结束位置,用于捕获分组。例如:(abc) 匹配 abc。 |
3-3.关于反斜杠说明
| 路由 | 匹配方式 | 说明 | 区分大小写 |
|---|---|---|---|
/images |
前缀匹配 | 匹配以 /images 开头的 URI。 |
是 |
/images/ |
前缀匹配 | 匹配以 /images/ 开头的 URI。匹配 /images/ 和 /images/ 后面跟任何内容的 URI。 |
是 |
1.配置
server {
location /images01 {
return 200 "匹配/images01 \n";
}
location /images02/ {
return 200 "匹配/images02/ \n";
}
location / {
return 200 "不匹配 \n";
}
}
2.测试说明
1. location /images01 # 只能匹配 /images01开头的
# 匹配
curl 192.168.85.135:80/images01/adasdas
curl 192.168.85.135:80/images011111154654
# 不匹配
curl 192.168.85.135:80/asdasda/images01
curl 192.168.85.135:80/IMages01
2. location /images02/ # 只能匹配 /images02/ 开头的
# 匹配
curl 192.168.85.135:80/images02/adasdas
curl 192.168.85.135:80/images02/
# 不匹配
curl 192.168.85.135:80/images02
curl 192.168.85.135:80/asdasda/images02/
curl 192.168.85.135:80/IMages02/
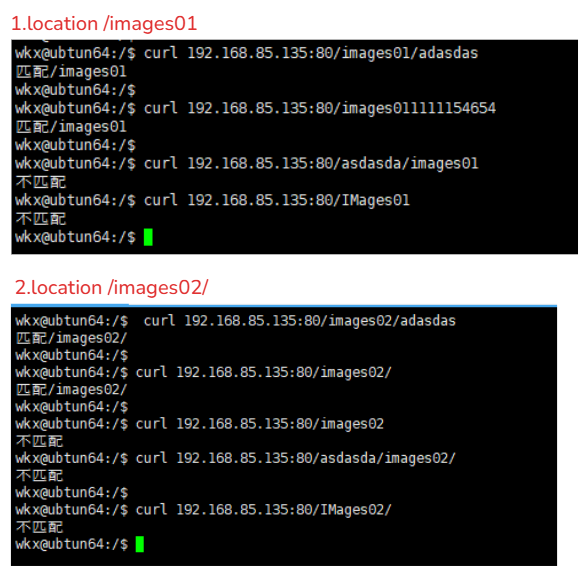
3-4.location实际用法
1.必选规则,设置反向代理,官网也推荐该用法,可以加速处理,因为首页会频繁被访问
# 该location 一般直接设置反向代理,转发给后端应用服务器,或者是静态页;
location = / {
proxy_pass http://yuchaoit.cn;
}
2.静态文件处理,nginx强项,两个模式,二选一即可。
这个表示当用户请求是 http://abc.cn/static/hello.css 这样的请求时,进入/www目录下,寻找static文件夹, 也就是/www/static/hello.css文件
1.匹配静态文件路由
location ^~ /static/ {
root /www/;
}
2.匹配静态文件后缀
# 这个表示请求是以如下静态资源结尾的,进入到/www/下寻找该文件,匹配任何以.gif结尾的请求,支持正则、
location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ {
root /www/;
}
3.还有就是通用规则,用于处理未定义的url,默认匹配
# 一般网站除了静态文件的请求,默认就是动态请求,因此直接转发给后端
location / {
proxy_pass http://my_django:8080/;
}
# 注意:一般情况下的 location url 匹配机制是根据后端的设计的url来进行制定的,而不是胡乱制定的
3-5.location重要的指令
| 指令参数 | 作用 | 示例配置 | 说明 |
|---|---|---|---|
root |
设置请求的根目录路径 | location /images { root /var/www/html; } |
如果请求 /images/example.jpg,Nginx 会尝试提供 /var/www/html/images/example.jpg |
alias |
设置请求的别名路径 | location /images { alias /var/www/html/images; } |
如果请求 /images/example.jpg,Nginx 会尝试提供 /var/www/html/images/example.jpg |
index |
指定默认的索引文件 | location / { index index.html index.htm; } |
如果请求 /,Nginx 会尝试提供 /index.html 或 /index.htm |
try_files |
尝试提供多个文件中的一个,需要配合root指令使用。 | location / { try_files $uri $uri/ /index.html; } |
如果请求 /example,Nginx 会依次尝试提供 /example、/example/ 和 /index.html |
rewrite |
对请求的 URI 进行重写 | location /old-path { rewrite ^/old-path/(.*)$ /new-path/$1 permanent; } |
将 /old-path/example 重写为 /new-path/example,并返回 301 永久重定向 |
proxy_pass |
将请求代理到另一个服务器 | location /api { proxy_pass http://backend-server; } |
将请求的 /api 路径代理到 http://backend-server |
return |
直接返回指定的响应 | location /maintenance { return 503 "Site is under maintenance"; } |
返回 503 状态码和自定义消息 |
error_page |
定义错误页面的处理规则 | location / { error_page 404 /404.html; } |
如果请求返回 404 错误,Nginx 会提供 /404.html |
autoindex |
启用目录列表 | location /files { autoindex on; } |
如果请求 /files,Nginx 会列出 /files 目录中的文件 |
expires |
设置响应的缓存过期时间 | location /images { expires 1d; } |
设置 /images 路径下的文件缓存过期时间为 1 天 |
add_header |
添加自定义响应头 | location / { add_header X-Custom-Header "MyValue"; } |
在响应头中添加 X-Custom-Header: MyValue |
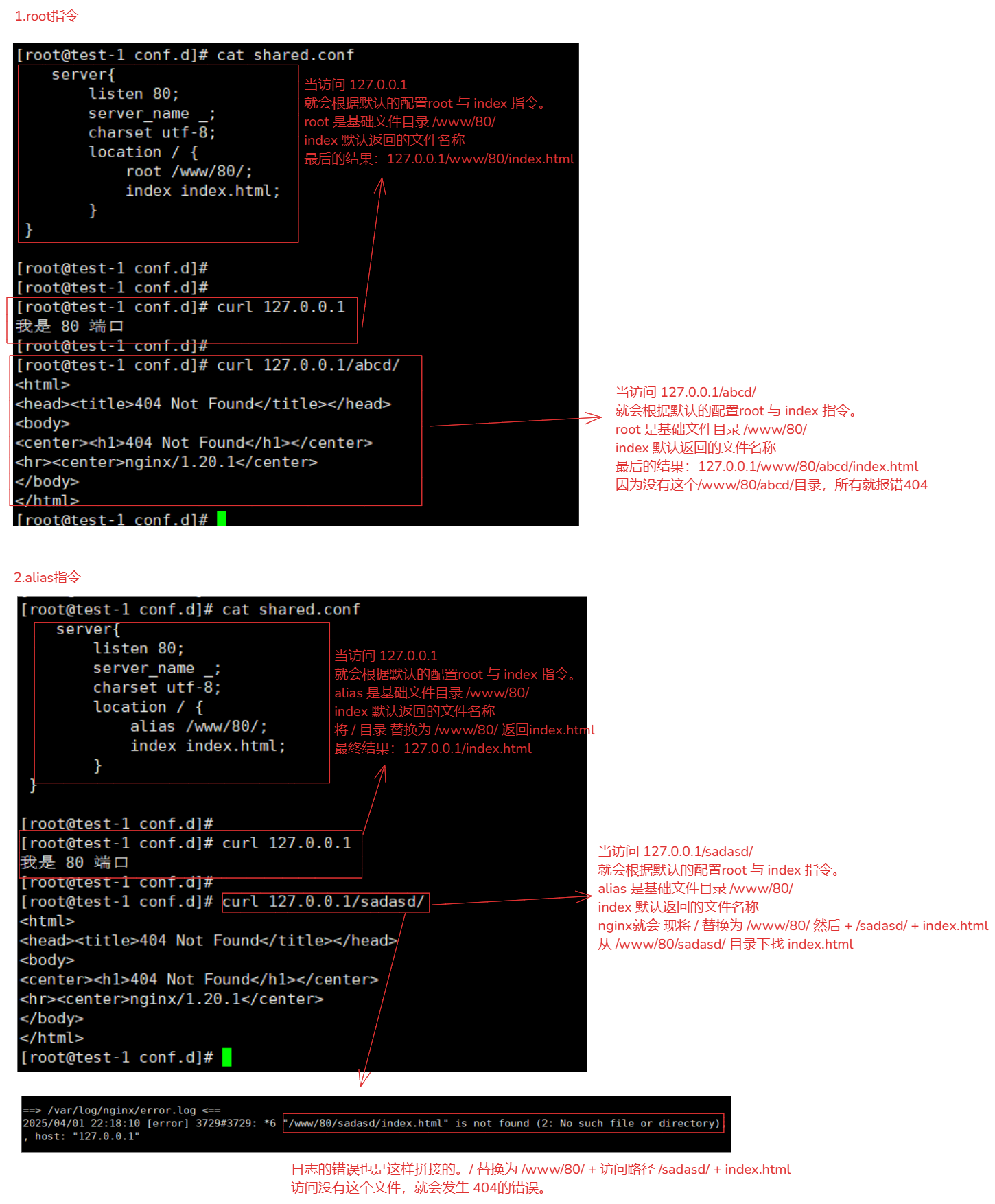
3-5-1.root 和 alias 解释
root指令的作用:
- 而是用于指定请求的文件路径的基础目录。它会根据请求的 URI 和 root 指定的目录来确定文件的实际路径。理解 root 的工作方式非常重要,因为它决定了 Nginx 如何查找和提供静态文件。
location / { root /www/80/; # 默认会将访问的路径与 root 指令的路径进行拼接 index index.html } 例如访问:http://127.0.0.1 就是在请求:http://127.0.0.1/www/html/index.html 例如访问:http://127.0.0.1/abcd/ 就是在请求:http://127.0.0.1/www/html/abcd/index.html # 可以理解为访问路径 与 root基础路径 进行拼接。alias指令作用:
- 是直接替换请求路径为指定的路径。
location / { # 注意:alias 指令后面的路径必须以斜杠 / 结尾,否则可能会导致路径映射错误。 alias /www/80/; # 会直接替换访问的路径使用 alias 指定的路径 index index.html } 例如访问:http://127.0.0.1/ 本质上请求:http://127.0.0.1/index.html 解释: 会将 / 替换为 /www/80/,然后将剩余的路径 /index.html 附加到后面,最终路径为 /www/80/index.html。 例如访问:http://127.0.0.1/sadasd/ 请求报错出现404错误。 因为:alias 是将请求路径替换为指定的文件系统路径。 / 替换为 /www/80/ 在与 sadasd/进行拼接:/www/80/sadasd/index.html # 文件不存在,Nginx 会返回 404 错误。区别:
root: location / { root /www/html/; index index.html; } 请求 http://example.com/:返回 /www/html/index.html。 请求 http://example.com/subdir/:返回 /www/html/subdir/index.html。 alias: location /api { alias /www/api/; index index.html; } 请求 http://example.com/api:返回 /www/api/index.html。 请求 http://example.com/api/somefile.html:返回 /www/api/index.html。 root:适用于处理通用的文件路径,通常用于网站的根目录。 alias:适用于处理特定的路径映射,例如 API 或特定的子目录。对比:
特性 rootalias作用 指定基础目录,所有请求路径都会相对于这个目录解析。 替换请求路径的一部分为指定的文件系统路径。 路径拼接 请求路径会被附加到 root指定的目录后面。请求路径的剩余部分会被附加到 alias指定的路径后面。适用场景 适用于处理通用的文件路径,通常用于网站的根目录。 适用于处理特定的路径映射,例如 API 或特定的子目录。 配置示例 root /www/html/;alias /www/api/;路径结尾 不需要以斜杠结尾。 通常需要以斜杠结尾,以表示目录。如果不以斜杠结尾,可能会导致路径映射错误。 图解:
root 和 alias 区别描述:
# 配置: location /api { alias /www/80/; # root /www/80/; root index.html; } 使用alias 访问:curl 127.0.0.1/api/121/ 使用root 访问:curl 127.0.0.1/api/121/

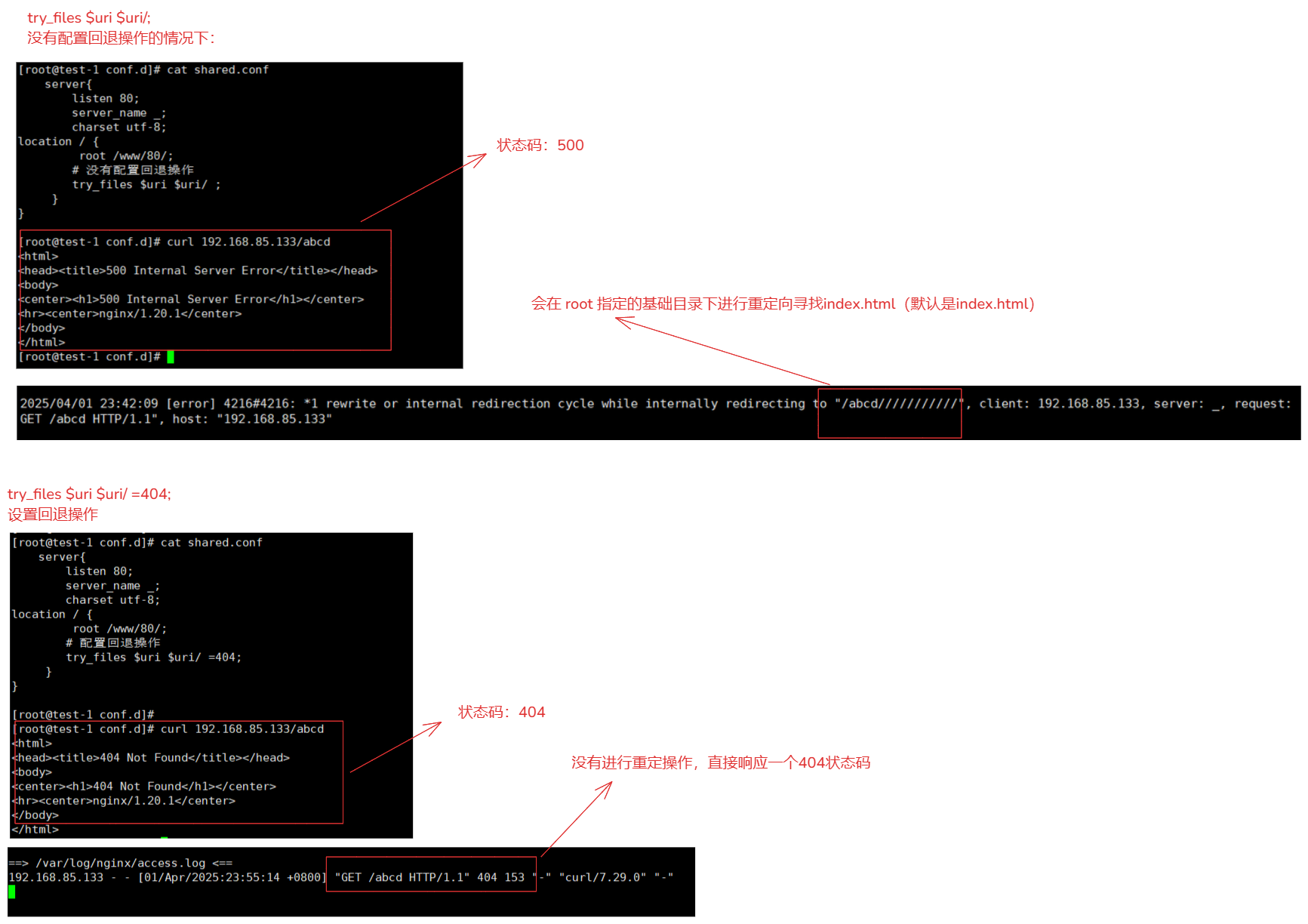
3-5-3.try_files解释
使用:
try_files <file1> [<file2> <file3> ...] [fallback];[<file2> <file3> ...]:如果 不存在,则依次尝试查找这些文件。[fallback]:如果所有文件都不存在,则执行的回退操作,可以是一个错误页面(如 =404[响应状态码],或其他路径 /index)。- 文件路径的组层会根据 root 与 alias 指定路径。
行为解释(作用):
- 尝试查找指定文件文件目录(请求的路径与 root 或者 alias 配置拼接或者替换)。
- 如果路径是一个目录,会从该目录下找index文件(默认是index.html,可以另外指定)。
- 如果将try_files指定的找完了,还是找不到就会执行指定的回退操作(如果指定的情况下)。
- 用于尝试提供多个文件中的一个,如果第一个文件不存在,尝试第二个,依此类推,最后可以指定一个默认文件或返回 404 错误。。
场景:
- 单页应用(SPA):确保所有路径最终返回 index.html。
try_files $uri $uri/ /index.html;- 静态文件服务:优化文件查找逻辑,确保请求的文件存在时直接返回,不存在时返回默认文件或错误页面。
try_files $uri $uri/ =404;- 自定义错误页面:返回自定义的错误页面,而不是默认的 404 错误。
try_files $uri $uri/ /404.html =404;- 复杂路由逻辑:根据请求路径返回不同的文件或执行不同的操作。
try_files $uri $uri/ /api/index.html;回退操作:
例如: location / { root /www/html/; try_files $uri $uri/; # 没有设置回退操作。 } location / { root /www/html/; try_files $uri $uri/ =404; # 设置回退操作。 } # 最后回退操作的目的: 如果没有找到try_files配置的情况下,提供一个明确的处理方式。 最终就会响应一个状态404(也可以响应一个其他的内容),而不是返回一个意外的页面或错误。 # 除了 try_files $uri $uri/ =404; 还可以这样操作 1.如果没有找到最终回到跟目录下 index.html(回到首页) try_files $uri $uri/ /index.html; 2.如果没有找到直接返回 /404.html try_files $uri $uri/ /404.html; 3.回退到指定的路径 location / { root /www/html/; try_files $uri $uri/ @fallback; } location @fallback { rewrite ^ /index break; }
例如简单的:
try_files $uri $uri/ /index.html;
location / {
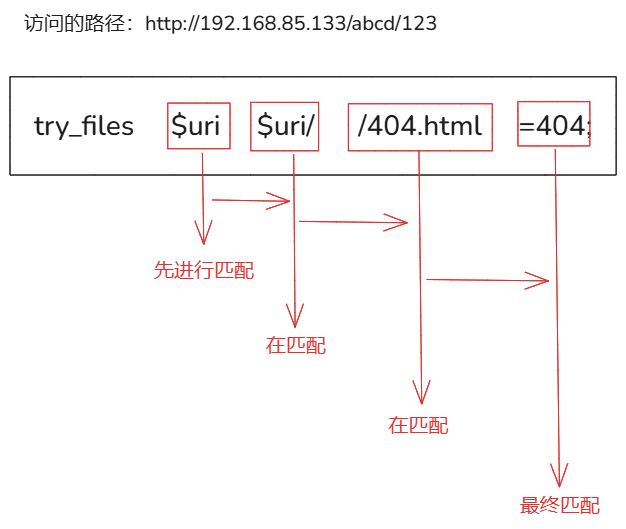
root /www/html/;
try_files $uri $uri/ /index.html;
}
请求 http://example.com/somefile.html:
1.找 /www/html/somefile.html 文件不存在
2.找 /www/html/somefile.html/ 还是不存在
3.最终找不到,则返回 /www/html/index.html。
例如复杂的:
try_files $uri $uri/ /404.html =404; 执行流程:
location / {
root /www/html/;
try_files $uri $uri/ /404.html =404;
}
1.首先尝试查找 /www/html/nonexistentfile.html。
2.如果文件不存在,尝试查找 /www/html/nonexistentfile.html/。
3.如果仍然找不到,尝试返回 /www/html/404.html。
4.如果 /www/html/404.html 也不存在,返回 HTTP 404 错误。
# 为什么需要 =404
1.即使 /404.html 文件不存在,Nginx 也会返回一个标准的 HTTP 404 错误,而不是尝试其他路径或返回其他内容。
2.如果没有 =404,Nginx 会继续尝试其他路径,可能导致无限回退或返回意外的内容。
3-5-4.rewrite 与 return解释
说明:
- rewrite 与 return都来自于Nginx模块:ngx_http_rewrite_module
- 文档:https://nginx.org/en/docs/http/ngx_http_rewrite_module.html
return解释:
- 用于直接返回指定的状态码和响应内容。常用于维护页面或重定向。
- 适用上下文:
server, location, ifreturn语法:
return code [text]; return code URL; return URL; 可以使用的状态码:# 301、302、303、307和308 301:永久重定向 302:临时重定向 例如: location /api { return 301 www.baidu.com; # 将请求重定向到另一个 URL。 } location /api { add_header Content-Type text/plain; # 自定义字符串会在浏览器下载。设置Content-Type避免自动下载。 return 200 'Hello, World!'; # 返回自定义的响应内容。 } location /api { return 403; # 返回特定的 HTTP 状态码 } location /api { return 302 /api001?args=abcd; # 将请求重定向到服务器配置中的另一个 location。 } # 注意: 1.return 指令可以用于重定向请求到另一个 URL,也可以返回自定义的文本或者是特定的状态码。通常使用'30x'状态码。 2.对于返回自定义文本或状态码,可以使用其他状态码,如 200 或 404。rewrite解释:
- 用于对请求的 URI 进行重写。
- 可以使用正则表达式捕获路径中的部分,并将其替换为新的路径。
- 适用上下文:
server, location, ifrewrite语法:
rewrite regex replacement [flag]; rewrite 正则[或者不是可以] 替换的内容 [标志参数]; flag【标志参数】: last:基于虚拟机内部的实现的url跳转操作。对其所在的server{}标签重新发起修改后的URL请求,再次匹配location{}。 break:基于虚拟机内部的实现的url跳转操作。在本条规则匹配完毕后,终止匹配,不再匹配后面的location{}; redirect:返回带有302代码的临时重定向。 permanent:返回带有301代码的永久重定向。 例如: location /oldpage { rewrite ^/oldpage$ /newpage permanent; # 当访问的是 /oldpage 就进行跳转到 /newpage } location / { rewrite ^/(.*)/old/(.*)$ /$1/new/$2 permanent; # 将/old 替换为 /new } 解释: 1.使用了正则表达式 ^/(.*)/old/(.*)$ 匹配 URL,并捕获两个分组($1 和 $2)。 2.重定向到 /$1/new/$2,其中 $1 和 $2 是正则表达式中的捕获分组,分别对应捕获的值。 3.permanent 标志表示这是一个永久重定向。详细请看
5-8.rewrite_module跳转: 跳转
3-5-5.expires解释
说明:
- rewrite 与 return都来自于Nginx模块:ngx_http_headers_module
- 文档:https://nginx.org/en/docs/http/ngx_http_headers_module.html
作用:
- 用于设置响应的缓存过期时间。可以指定缓存时间(如 1d 表示 1 天)。
- 主要设置HTTP响应头中
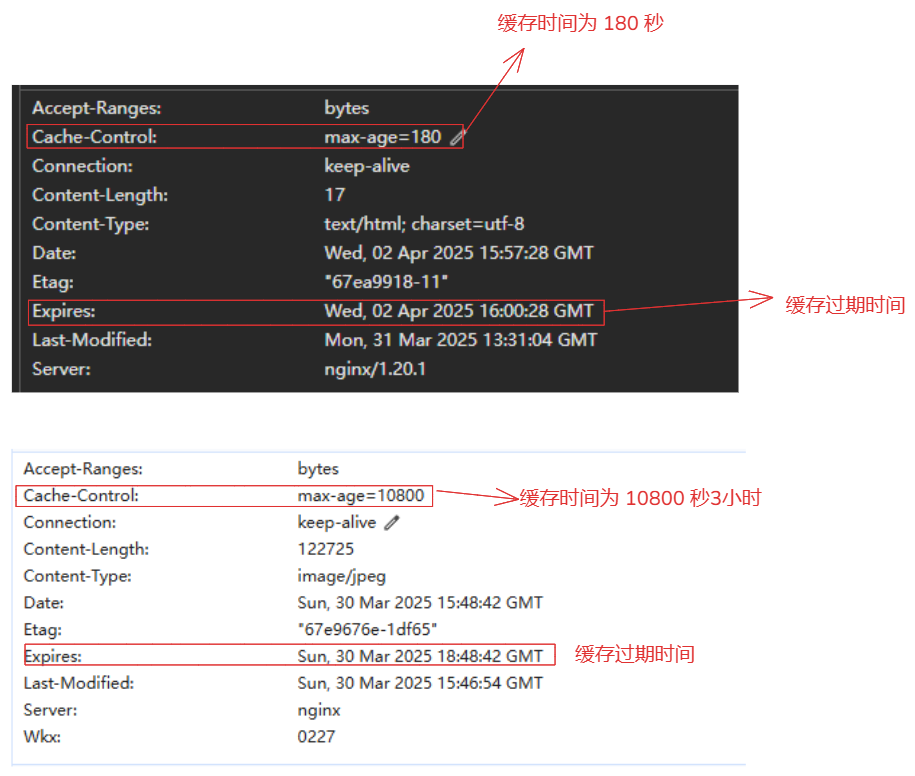
Expires和Cache-Control字段,从而控制页面的缓存。使用方式:
语法: expires [modified] time; expires epoch | max | off; 例如: location ~*\.(js|css|html|png|jpg)$ { expires 3d; # 对js|css|html|png|jpg后缀的文件进行缓存3天 # expires 3m; # 对js|css|html|png|jpg后缀的文件进行缓存3分钟 add_header Cache-Control "public"; } # time的单位 s 秒(默认) m 分钟 h 小时 d 天 w 周 M 月份,30天 y 年份,365天 # 为什么添加 Cache-Control "public" 目的: 指定这个'Cache-Control "public"'请求头的目的就是允许缓存,无论是浏览器还是中间件这类的软件(CDN,代理服务器),都可以允许缓存这个些静态文件。 优势: 1.提高缓存效率:通过允许内容被缓存,可以减少对服务器的请求次数,从而提高加载速度并降低服务器的负载。这对于静态资源(如 JavaScript 文件、CSS 文件、HTML 页面、图片等)尤其有用,因为这些资源不经常变化。 2.当 Cache-Control 设置为 public 时,它指示响应的内容可以被任何缓存(包括共享缓存,如 CDN 和私有缓存,如用户的本地浏览器缓存)。使用场景:
设置相对时间:expires 3d; 表示缓存 3 天。 设置绝对时间:expires @22h30m; 表示在当天的指定时间失效。 无有效期设置:expires -1; 表示永远过期。 expires epoch | max | off; 三个值的说明: 1.max最大值设置:expires max; 表示缓存 10 年。 2.off关闭:expires off; 表示禁用或者添加修改 Expires 和 Cache-Control 的值 3.epoch:expires epoch; 指定 Expires 的值为 1 January, 1970, 00:00:01 GMT,Cache-Control 的值为 no-cache。案例:
1.缓存3分钟 location ~*\.(js|css|html|png|jpg)$ { expires 3m; add_header Cache-Control "public"; } 2.缓存3小时 location ~*\.(js|css|html|png|jpg)$ { expires 3h; add_header Cache-Control "public"; }
4.Nginx内置变量
文档:https://nginx.org/en/docs/varindex.html
说明:
- 这些变量大部分来自于nginx的模块中。
- 这些内置变量可以帮助配置:日志,url跳转时使用。
- 例如:nginx 在接受请求解析到那个虚级主机,就是通过使用 host 进行匹配服务器名称返回页面。
常用变量说明:
变量名 描述 示例值 $request_method请求的方法(如 GET、POST等)GET$request_uri完整的请求 URI,包括查询参数 /index.html?param=value$hostname主机名称 $https如果开启了SSL安全模式,值为"on",否则为空字符串。 $content_lengthContent-Length请求头字段 $content_typeContent_type请求头字段 $uri请求的 URI,不包括查询参数 /index.html$args查询参数部分 param=value$query_string查询参数部分(与 $args相同)param=value$http_host请求头中的 Host字段example.com$host请求的主机名(优先使用 $http_host,否则使用服务器主机名)example.com$remote_addr客户端的 IP 地址 192.168.1.1$remote_port客户端的端口号 56789$server_addr服务器的 IP 地址 10.0.0.1$server_port服务器的端口号 80$scheme请求的协议( http或https)http$statusHTTP 响应状态码 200$body_bytes_sent发送给客户端的响应体字节数 1234$bytes_sent发送给客户端的总字节数(包括响应头和响应体) 1500$time_iso8601当前时间(ISO 8601 格式) 2025-03-30T12:34:56+08:00$time_local当前时间(本地时间格式) 30/Mar/2025:12:34:56 +0800$document_root当前请求的文档根目录 /var/www/html$request_filename请求的文件路径( $document_root+$uri)/var/www/html/index.html$http_referer请求头中的 Referer字段(来源页面)http://referrer.com$http_user_agent请求头中的 User-Agent字段(客户端浏览器信息)Mozilla/5.0$nginx_versionnginx版本 $proxy_hostproxy_pass指令中指定的代理服务器的名称和端口 $proxy_portproxy_pass指令中指定的代理服务器的端口,或协议的默认端口;
4-1.第三方模块echo使用过程
模块网址:
https://github.com/openresty/echo-nginx-module
1.源码编译安装
1.下载模块与源码nginx
yum install git pcre pcre-devel openssl openssl-devel zlib zlib-devel gzip gcc gcc-c++ make wget httpd-tools vim -y
git clone https://github.com/openresty/echo-nginx-module.git
wget http://nginx.org/download/nginx-1.19.0.tar.gz
2.生成makefile文件,使用 --add-module 指定三方的模块
./configure --prefix=/usr/local/nginx \
--add-module=./echo-nginx-module
3.编译安装
make -j$(nproc) # 使用多线程编译
sudo make install
2.动态编译安装(针对已经安装过nginx例如apt安装或者yum安装)【只能 1.9.11版本以上才能支持】
1.下载三方模块
cd opt && git clone https://github.com/openresty/echo-nginx-module.git
2.下载一个nginx源码与当前使用版本一样的
wget http://nginx.org/download/nginx-1.24.0.tar.gz
tar -xzvf nginx-1.22.0.tar.gz
cd nginx-1.24.0
sudo apt-get install libpcre3 libpcre3-dev libssl-dev -y # 安装必要依赖
./configure --prefix=/opt/nginx --add-dynamic-module=/opt/echo-nginx-module # 编译的参数要与你运行nginx相同
make modules
3.就会生成一个 ngx_http_echo_module.so 文件,将文件在nginx中配置即可
objs/ngx_http_echo_module.so # 当前的nginx源码objs文件下
ln -s /opt/nginx-1.24.0/objs/ngx_http_echo_module.so /etc/nginx/modules/
# 配置在nginx文件中
load_module /etc/nginx/modules/ngx_http_echo_module.so;
http {
# 其他配置
}
4.检测配置
sudo nginx -t
# 注意:在 Nginx 中动态加入第三方模块时,需要与当前正在运行的 Nginx(版本也要相同) 的编译参数一模一样
1. 二进制签名机制:Nginx 使用二进制签名机制来确保动态模块与 Nginx 可执行文件的兼容性。这个签名由多个部分组成,每个部分通常用字符 "0" 或 "1" 标识当前环境是否具备某个功能,或是否开启了某个特性。这些特性通常由编译配置选项控制。
2. 编译配置选项如果不同可能会导致影响内部结构和功能,导致函数签名匹配,依赖库不匹配问题。
3.在使用动态加入模块是,一定要使用nginx一模一样的版本与编译参数。
# 注意:--add-module 与 --add-dynamic-module 是两个不同的参数
--add-module:用于编译静态模块。静态模块在 Nginx 编译时直接嵌入到 Nginx 可执行文件中,无法在运行时动态加载。
--add-dynamic-module:用于编译动态模块。动态模块可以在 Nginx 运行时通过配置文件动态加载,而不需要重新编译 Nginx。
如果你的机器没有正在运行实际生产环境的nginx时,想要使用第三方模块,直接下载源码的nginx将这个模块使用 --add-module 加入,编译后的nginx就拥有这个模块功能,
如果你的机器已经有nginx在实际运行,又不想重新的编译安装的情况下可以使用 --add-dynamic-module 动态的方式。
# 其他的第三方模块:
NAXSI Web 应用程序防火墙:
作用:Web 应用程序防火墙(WAF),使用启发式方法和评分系统来识别可疑请求,例如 XSS 和 SQL 注入攻击。
git clone https://github.com/nbs-system/naxsi.git
等等
4-2.编写配置测试
1.配置
server {
location / {
echo "Hello, world!";
}
}
2.重启测试
sudo systemctl restart nginx
curl 192.168.85.135
4-3.通过echo模块打印变量
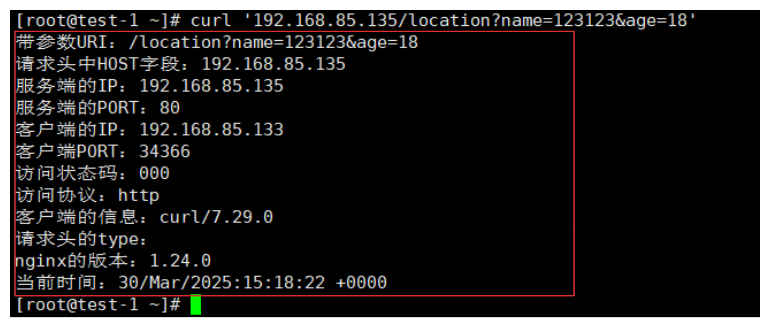
1.修改配置
server {
location / {
echo "带参数URI:$request_uri\n请求头中HOST字段:$http_host\n服务端的IP:$server_addr\n服务端的PORT:$server_port\n客户端的IP:$remote_addr\n客户端PORT:$remote_port\n访问状态码:$status\n访问协议:$scheme\n客户端的信息:$http_user_agent\n请求头的type:$content_type\nnginx的版本:$nginx_version\n当前时间:$time_local";
}
}
2.重启测试
sudo systemctl restart nginx
curl '192.168.85.135/location?name=123123&age=18'
5.Nginx具有功能
5-1.日志功能
模块: ngx_http_log_module
文档: https://nginx.org/en/docs/http/ngx_http_log_module.html
**作用:**设置日志记录。
模块指令:
指令 作用 access_log开启或者关闭日志(日志写入),默认支持区域 http,server,location,if in location,limit_except,设置的区域不同,会覆盖上层区域。禁止日志:access_log off;log_format指定日志格式,格式内的参数就是使用的内置变量(模块提供的)。 log_format 日志名称 日志格式,支持区域:httpopen_log_file_cache定义一个缓存,用于存储名称包含变量的常用日志的文件描述符。支持区域 http,server,location。默认配置:
http { # 其他配置 log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; # 由于在http开启,那么就会作用于整个http }
open_log_file_cache补充说明:
open_log_file_cache 参数说明: 1.默认情况下,对于每一条日志记录,Nginx 都会先打开文件,再写入日志,然后关闭。 2. 可以定义一个缓存,用于存储名称中包含变量的常用日志的文件描述符,这样可以减少打开和关闭文件描述符的次数,从而提高性能。 例如配置: open_log_file_cache max=1000 inactive=20s valid=1m min_uses=2; max=1000:这个参数指定了缓存中最多可以存储1000个文件描述符。 inactive=20s:这个参数指定了文件描述符在多长时间内没有被访问,则会被从缓存中移除,如果1个文件描述符在20秒内没有被使用,就会被认为不活跃,就会关闭。 valid=1m:这个参数指定了 Nginx 多久检查一次缓存中的文件描述符,以确保它们仍然有效。在这个例子中,Nginx 每分钟检查一次。 min_uses=2:这个参数指定了在 inactive 时间段内,文件描述符至少需要被使用多少次才能保持在缓存中。 inactive=20s min_uses=2:文件描述符必须在20秒内至少访问2次才不会被移除缓存。

5-1-1.不同虚拟机配置不同日志
# 为什么需要设置不同虚拟机不是同日志
1.只有单独对单个网站,记录的日志才有提取的和分析的意义。
2.如果你由5个网站都将日志写在同一个文件中,那么提取的意义有什么用户,根本无法分辨那些请求是针对那些网站的。
1.设置日志格式
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# 80
log_format main_80 '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# 81
log_format main_81 '$document_uri $remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main; # 默认开启的,会被覆盖。
}
2.设置虚拟机
server{
listen 80;
server_name _;
access_log /var/log/nginx/80.log main_80; # 80端口开启配置
charset utf-8;
location / {
root /www/80/;
index index.html;
}
}
server{
listen 81;
server_name _;
charset utf-8;
access_log /var/log/nginx/81.log main_81; # 81端口开启配置
location / {
root /www/81/;
index index.html;
}
}
3.测试访问
tail -f /var/log/nginx/*.log # 监控
curl 192.168.85.133:80
curl 192.168.85.133:81
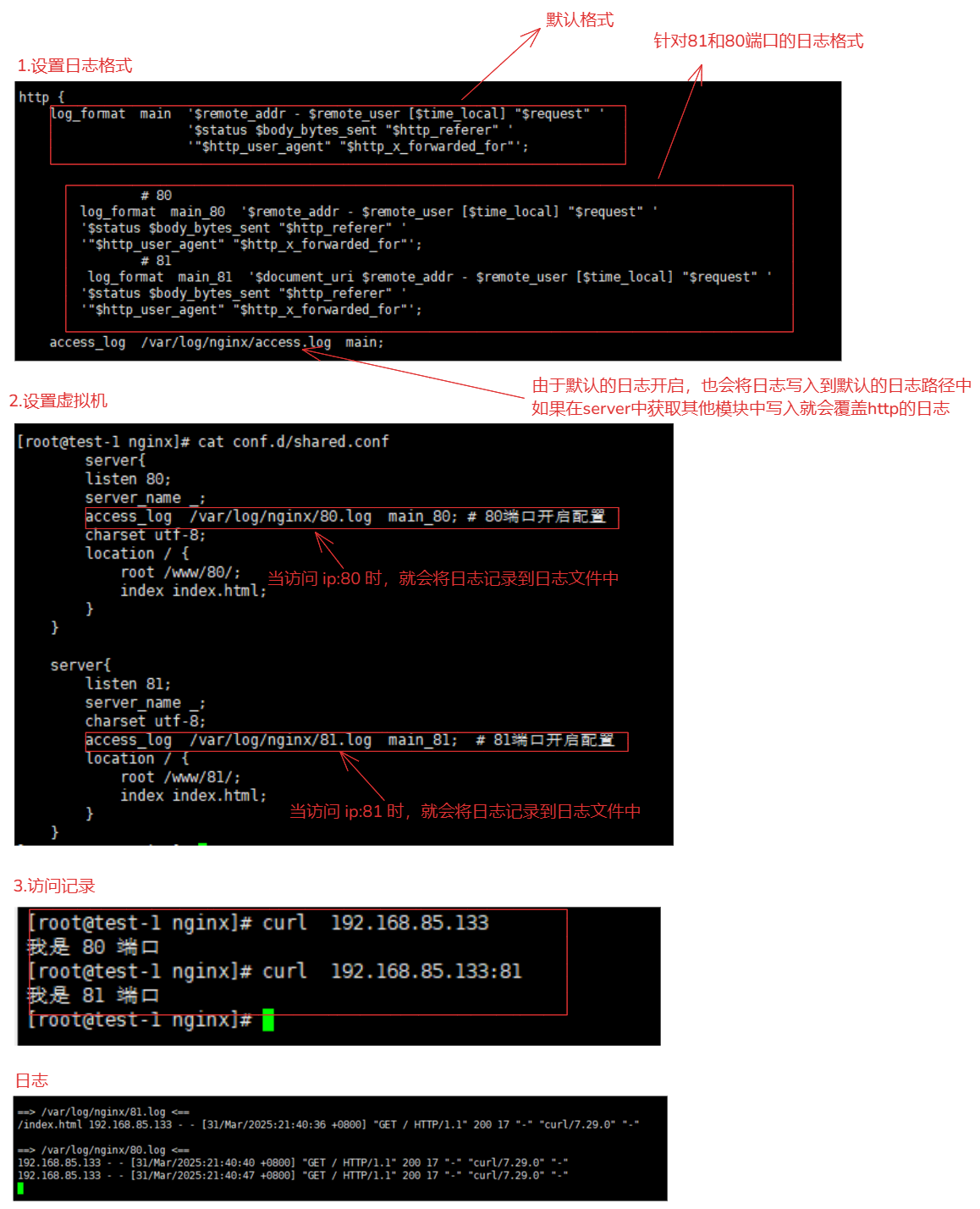
5-1-2.日志覆盖的问题
覆盖机制:
Nginx 配置规则的覆盖机制,即更具体的配置会覆盖更通用的配置。
http{
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access.log /var/log/nginx/access.log main; # http 区域设置的日志
server {
access.log /var/log/nginx/access_server.log main; # server区域 覆盖 http区域
# 其他配置
location / {
access.log /var/log/nginx/access_location.log main; # location区域 覆盖 server区域
}
}
}
5-1-3.错误日志设置
模块:ngx_core_module(nginx的核心模块)
文档:https://nginx.org/en/docs/ngx_core_module.html#error_log
指令:
指令 说明 error_log记录错误日志信息。支持区域: main, http, mail, stream, server, location。错误等级:debug, info, notice, warn, error, crit, alert, emerg。使用方式:error_log 存储文件 错误等级默认设置:
日志等级: debug:调试信息,产生大量的日志输出,用于问题诊断。 info:一般信息,记录操作过程和结果。 notice:普通通知信息,记录正常操作中值得注意的事件。 warn:警告信息,表明有潜在的问题。 error:错误信息,表明请求没有成功处理。 crit:临界错误,表明出现了严重问题。 alert:警告状态,需要立即关注。 emerg:紧急情况,表明系统不稳定或将要崩溃。 error_log /var/log/nginx/error.log; # 如果没有指定日志级别,Nginx 默认会记录所有级别的错误信息。
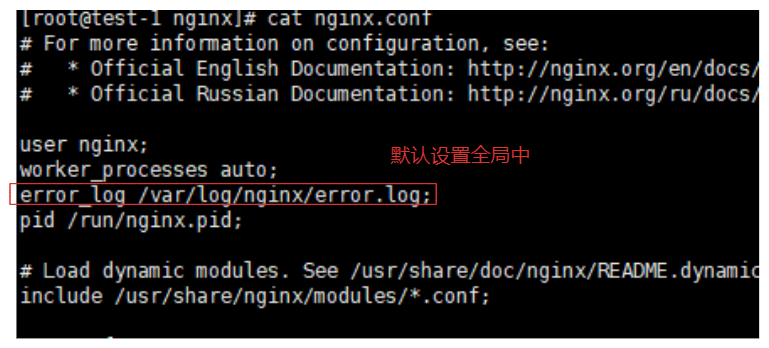
1.设置
server{
listen 80;
server_name _;
error_log /var/log/nginx/error_80.log; # 80开启错误日志
charset utf-8;
location / {
access_log /var/log/nginx/80_80.log main_80;
root /www/80/;
index index.html;
}
}
2.重启机器进行测试
systemctl restart nginx
curl 192.168.85.133/nginx/test/index.html
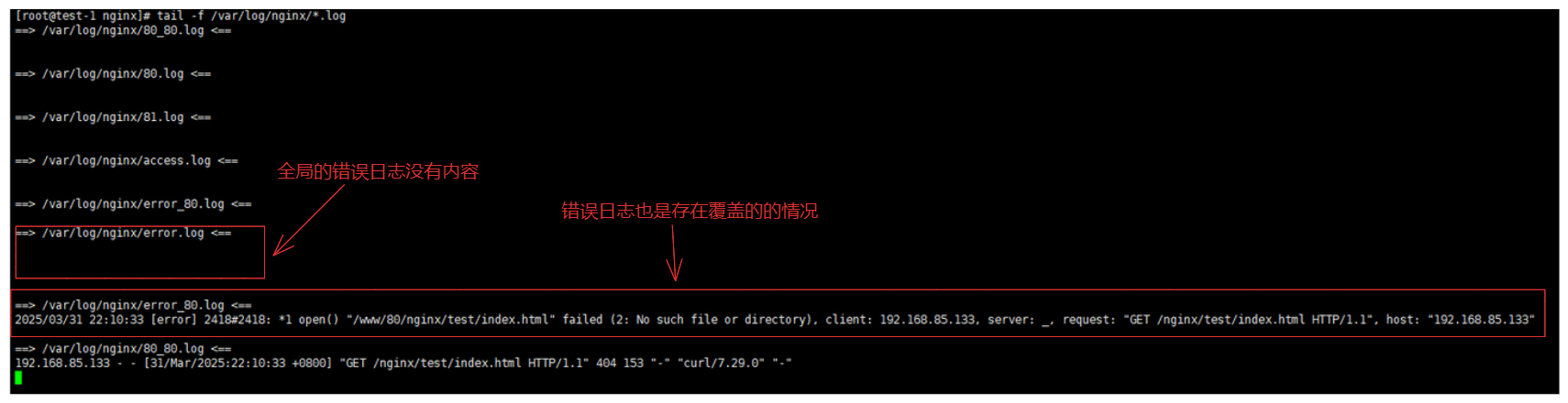
5-1-4.日志分割工具
日志分割:
- nginx日志默认是不切割的,网站运行久了自然生成大量日志,导致单文件的处理,太麻烦,因此工作里一般定期切割,一般按天切割。
为什么需要日志分割:
- 为了业务进行提取方便。
- 防止日志文件过大,切割后容易做备份。
分割操作:
- 给Nginx发送一个信号,让Nginx重新生成一个日志文件。
- shell脚本切割。
- Logrotate工具切割。
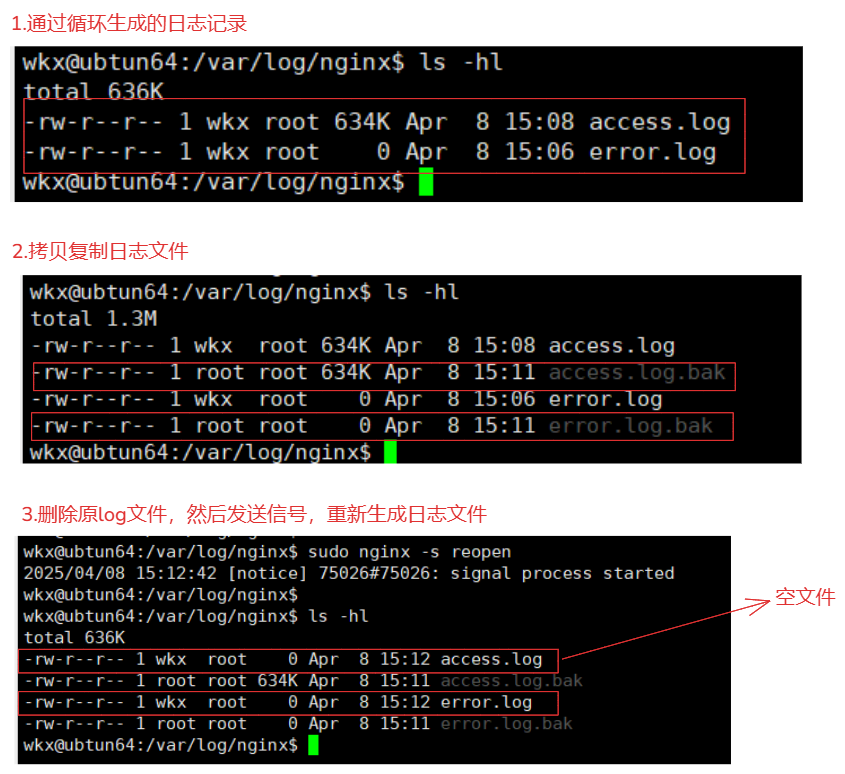
1.发送信号重新载入日志
# 先生成日志 for i in {1..1000};do sudo curl -s 127.0.0.1:1111 > /dev/null; done 1.备份日志文件 sudo cp /var/log/nginx/access.log /var/log/nginx/access.log.bak sudo cp /var/log/nginx/error.log /var/log/nginx/error.log.bak 2.删除原来的日志文件 sudo rm -rf *.log 3.通过指令 reopen 重新打开日志文件。 sudo nginx -s reopen sudo systemctl reload nginx # 这system管理脚本并没有 reopen,需要再脚本中添加 去其他的指令合并到一起 例如: ExecReload=/bin/kill -s HUP $MAINPID ; /usr/sbin/nginx -s reopen
shell脚本:
使用shell脚本 就需要shell脚本与crontab进行结合使用 # 先生成日志 for i in {1..1000};do sudo curl -s 127.0.0.1:1111 > /dev/null; done 1.创建脚本 backup_nginx_log.sh #!/bin/bash dateTime=$(date "+%F") # 获取当前时间 sudo mkdir -p /var/log/nginx/${dateTime} # 创建一个当天日志的文件 # 备份 # 1.简单的解决方式 sudo cp /var/log/nginx/access.log /var/log/nginx/${dateTime}/access.log.${dateTime} # 拷贝 sudo cp /var/log/nginx/error.log /var/log/nginx/${dateTime}/error.log.${dateTime} # 拷贝 # 2.比较合理的解决方式-检测到全部的nginx日志文件包 sudo find /var/log/nginx/ -maxdepth 1 -type f | sudo xargs -i mv {} {}.${dateTime} sudo find /var/log/nginx/ -maxdepth 1 -type f -name "*.${dateTime}" -exec mv {} /var/log/nginx/${dateTime}/ \; # 第一种移动方式 使用 -exec 指令 sudo find /var/log/nginx/ -maxdepth 1 -type f -name "*.${dateTime}" | sudo xargs -i mv {} ${dateTime}/$(basename {}) # 第二种移动方式 使用 管道符 xagrs # 删除原文件 sudo rm -rf /var/log/nginx/*.log 2>&1 # 重新打开日志文件。 sudo nginx -s reopen > /dev/null 2>&1 2.添加定时器 sudo crontab -e 59 23 * * * /usr/bin/sudo /usr/bin/bash ~/backup_nginx_log.sh # 每天夜里23:59分进行日志切割
Logrotate日志切割工具:
# shell脚本切割比较简单方便、nginx其实提供了更好用的工具,logrotate是一款自动切割日志的工具。 1.查看日志切割工具 logrotate(linux默认安装的。) /etc/logrotate.d # 配置文件所在路径 2.查看nginx的配置 /var/log/nginx/*.log { # 针对当前 /var/log/nginx/*.log 目录下的 log结尾的文件 daily # 每天轮转日志文件。每天生成 missingok # 如果日志文件不存在,不会报错。 rotate 14 # 保留 7 个旧的日志文件。 compress # 对轮转后的日志文件进行压缩。 delaycompress # 延迟压缩,即在下一次轮转时才压缩旧的日志文件。 notifempty # 如果日志文件为空,不会进行轮转。 create 0640 www-data adm # 创建新的日志文件,并设置权限为 0640,所有者为 www-data,所属组为 adm。 dateext # 基于当前日期的时间戳作为后缀,如果不是使用dateformat,格式:access.log-20250408 dateformat -%Y-%m-%d # 定义设置的时间格式 如:access.log-2025-04-09 sharedscripts # 在所有日志文件轮转后,只执行一次 postrotate 脚本。 postrotate # 在轮转之后通知服务重新打开日志文件 reopn ,确保新的日志写入到新的文件中。 # 指令脚本,可以指定 shell 脚本(内部可以对备份的文件进行再次处理) invoke-rc.d nginx rotate >/dev/null 2>&1 endscript } 3.手动执行 sudo logrotate -f /etc/logrotate.d/nginx 4.使用定时器进行生成 00 00 * * * /usr/sbin/logrotate -f /etc/logrotate.d/nginx >> /var/log/nginx/logrotate_nginx.log 2>&1 5.补充说明 这个工具与shell日期切割的方式差不多,只不过多了一些功能而已 postrotate # 执行 postrotate 脚本 # 脚本 endscript # postrotate 脚本结束
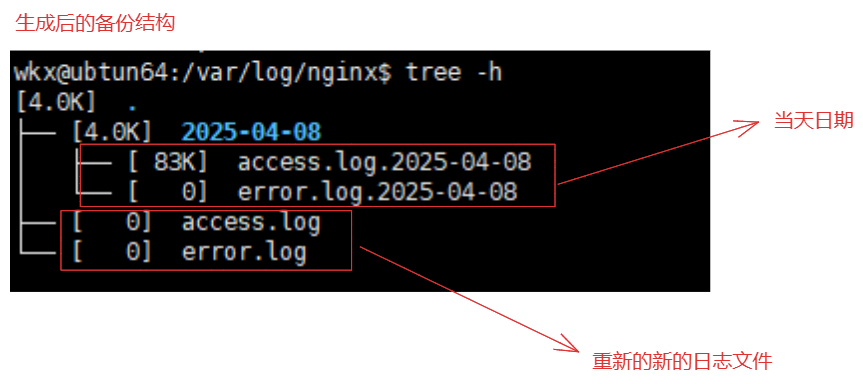
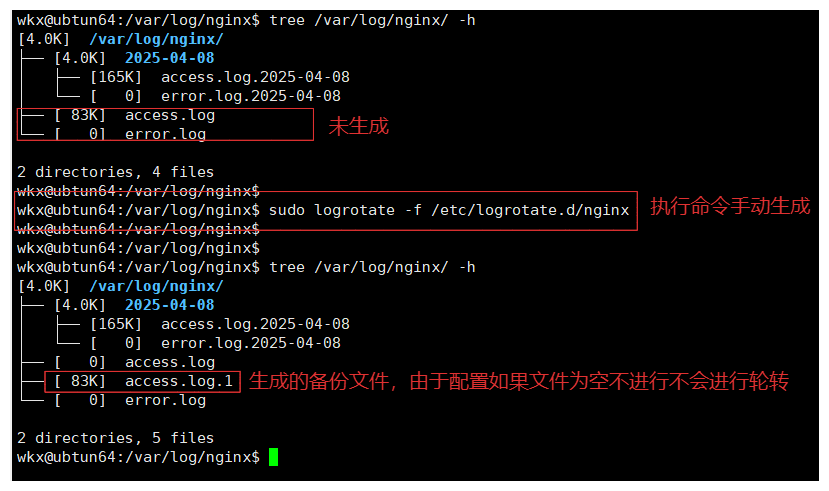
5-2.文件索引功能
**模块:**ngx_http_autoindex_module
**文档:**https://nginx.org/en/docs/http/ngx_http_autoindex_module.html
作用:
- 用于在访问目录时生成目录列表。
指令:
指令 说明 autoindex启用或禁用目录列表输出。使用区域: http,server,location,默认:autoindex off;。on开启,off关闭。autoindex_exact_size展示目录下的文件大小。使用区域: http,server,location。默认:autoindex_exact_size on;。on开启,off关闭。autoindex_localtime展示时间。使用区域: http,server,location。默认:autoindex_localtime off;。on开启,off关闭。autoindex_format展示目录的格式,使用区域: http,server,location。默认:autoindex_format html;。格式:html,xml,json,jsonp使用方式:
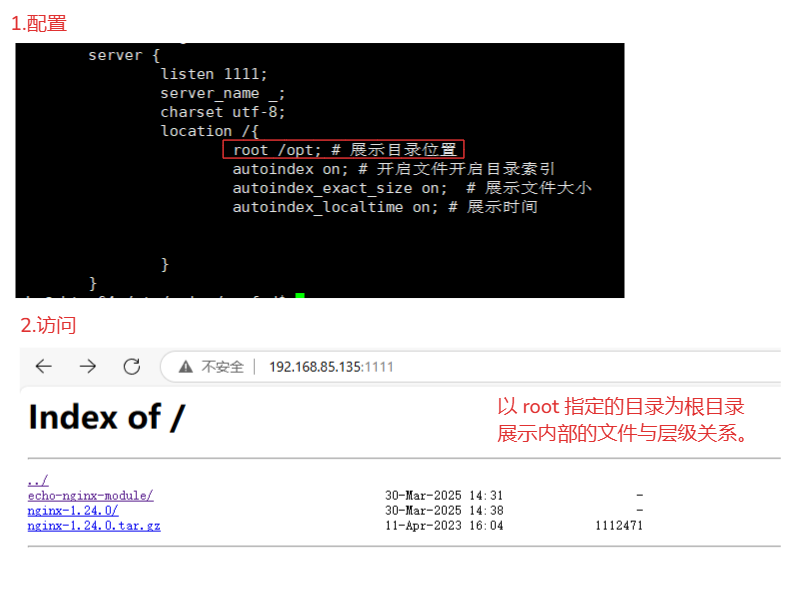
server { listen 1111; server_name _; charset utf-8; location /{ root /www; # 展示目录位置 autoindex on; # 开启文件开启目录索引 autoindex_exact_size on; # 展示文件大小 autoindex_localtime on; # 展示时间 } }
5-3.访问限流功能
模块:ngx_http_limit_req_module
文档:https://nginx.org/en/docs/http/ngx_http_limit_req_module.html
**作用:**用于限制每个定义的键(如客户端 IP 地址)的请求处理速率。它使用“漏桶”算法来实现限流。它使用“漏桶”算法来实现限流。
指令:
指令 说明 limit_req_zone使用区域: http, server, location,定义一个共享内存区域,用于存储请求状态。语法:limit_req_zone key zone=name:size rate=rate [sync];limit_req使用区域: http,在指定的共享内存区域内启用请求频率限制。语法:limit_req zone=name [burst=number] [nodelaylimit_req_log_level使用区域: http, server, location。设置当请求被限制时的日志记录级别。`limit_req_log_level infolimit_req_status使用区域: http, server, location。设置当请求被拒绝时返回的 HTTP 状态码。语法:limit_req_status code;limit_req_dry_run使用区域: http, server, location。启用试运行模式。在这种模式下,请求处理速率不受限制,但过多的请求数量仍会记录在共享内存区域中。语法:`limit_req_dry_run on使用方式:
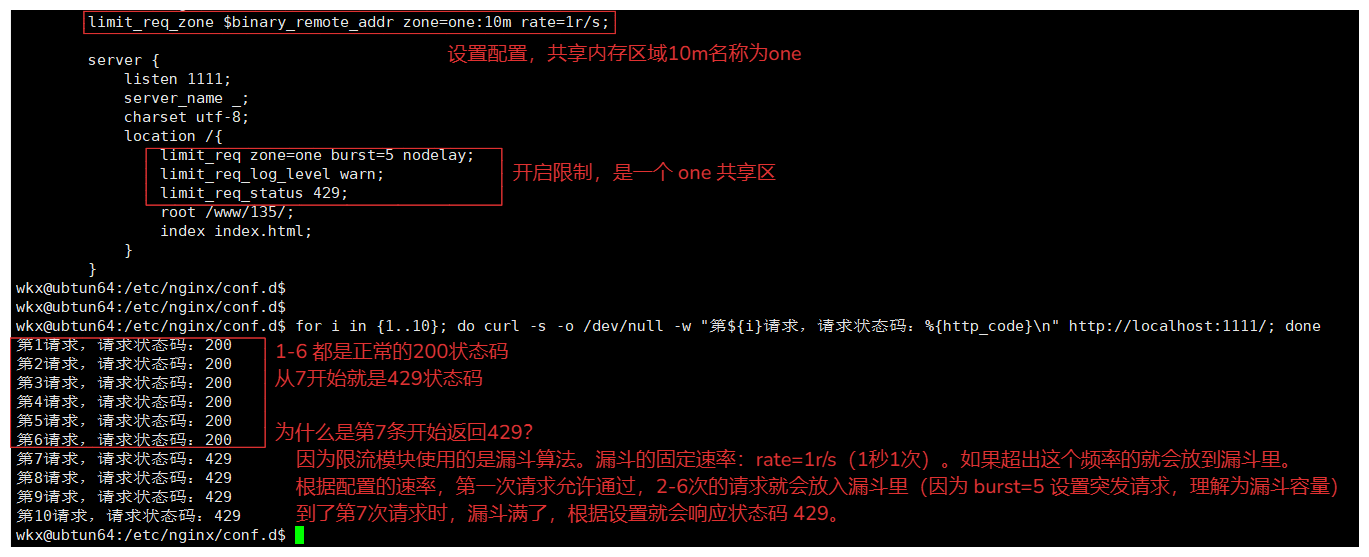
例如: http{ ... limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; server { listen 1111; server_name _; charset utf-8; location /{ limit_req zone=one burst=5 nodelay; limit_req_log_level warn; limit_req_status 429; root /www/135/; index index.html; } } } # 解释 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; 请求的key:$binary_remote_addr(访问的ip地址2进制形式的) zone=one:10m:共享内存的名称:one ,它的大小: 10M rate=1r/s:访问的频率是 1秒1次。 limit_req zone=one burst=5 nodelay; 开启限制。 zone=one:使用后 limit_req_zone 定义的共享区域,one这个区域。 burst=5:允许在短时间内突发请求的数量。5个 nodelay:表示不对突发请求进行延迟处理,而是立即处理。 # delay=number 指定延迟处理的限制。 limit_req_status 429; 当超出限制后,就会被拒绝,返回HTTP状态码时 429; # 测试: for i in {1..10}; do curl -s -o /dev/null -w "第${i}请求,请求状态码:%{http_code}\n" http://localhost:1111/; done # 注意: limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s; # 请求分为: 正常请求数量:根据 rate 指定的速率允许通过的请求数量。 突发请求数量:根据 burst 参数允许的突发请求数量。 延迟请求数量:根据 delay 参数允许的延迟请求数量。 # 限制内请求数量的计算方式: 正常请求数量 + 突发请求数量 + 延迟请求数量 = 当前我可请求的总数量 limit_req zone=one burst=5 nodelay; rate=1r/s 设置的是访问的速率,每秒允许 1 个请求通过。。 burst=5 除了正常速率规则内的请求,还可以允许在短时间内突发 5 个请求。 nodelay:立即处理。 # 可以理解为,在1秒内可以访问6次请求(1次正常请求 + 5次突发请求)。 limit_req zone=one burst=5 delay=5; rate=1r/s 设置的是访问的速率,每秒允许 1 个请求通过。。 burst=5:允许在短时间内突发一定数量的请求是5个。 delay=5:允许延迟处理5个请求数量。 # 可以理解为,在1秒内可以访问11次请求(1次正常请求 + 5次突发请求 + 5延迟处理请求数量)。
5-4.错误页面功能
模块:ngx_http_core_module
文档:https://nginx.org/en/docs/http/ngx_http_core_module.html#error_page
**作用:**定义响应返回的错误页面。
指令:
指令 说明 error_page定义将为指定错误显示的URI。使用的区域 http,server,location,if in location。使用方式error_page code uri;`方式:
1.根据错误代码,服务器的静态页面 error_page 404 /404.html; error_page 500 502 503 504 /50x.html; 2.直接返回访问的错误网络页面 error_page 403 http://abc/error.html; # 访问 403 时直接跳转 http://abc/error.html 页面 error_page 404 =301 http://abc/error.html; # 将 404状态码 转为 30状态码 并且跳转到 http://abc/error.html 页面 3.返回静态内容 error_page 404 =200 /empty.gif; # 当访问的是 404状态码 时,访问当前的 /empty.gif 路由内容 4.重定向导服务器的某个相关location块中 # 内部重定向 error_page 404 = /404.php; location = /404.php { # 指定 PHP 脚本的根目录 root /path/to/your/root; # 指定 PHP 处理器 try_files $uri =404; # 调用 PHP 处理器 include fastcgi_params; fastcgi_pass 127.0.0.1:9000; fastcgi_index index.php; } 5.内部重定向,与第4个相同。# 内部代理 location / { error_page 404 = @fallback; } location @fallback { proxy_pass http://backend; }
5-4-1.命名内部代理
1.配置
server{
listen 80;
server_name _;
charset utf-8;
location / {
root /www/80/;
index index.html;
}
error_page 404 = @fallback; # 如果页面没有找到 (404状态码) 就会跳转到 @fallback 触发代理的 https://baidu.com
location @fallback {
proxy_pass https://baidu.com;
}
}
2.重启测试
systemctl restart nginx
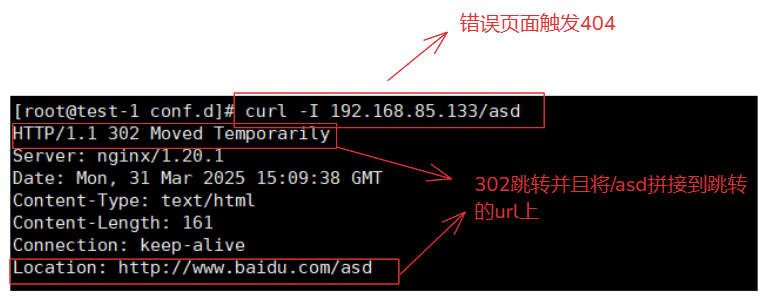
当访问由于这个页面没有触发状态码404:
curl 192.168.85.133/asd
触发error_page跳转,进行反向代理,将/asd 拼接到proxy_pass的地址后面。
https://www.baidu.com/asd
5-4-2.错误重定向修改状态码
1.配置
server{
listen 80;
server_name _;
charset utf-8;
location / {
root /www/80/;
index index.html;
}
# 如果访问的是错误触发404就会将状态码转变为301并且跳转到百度
error_page 404 =301 https://www.baidu.com/;
}
2.重启测试
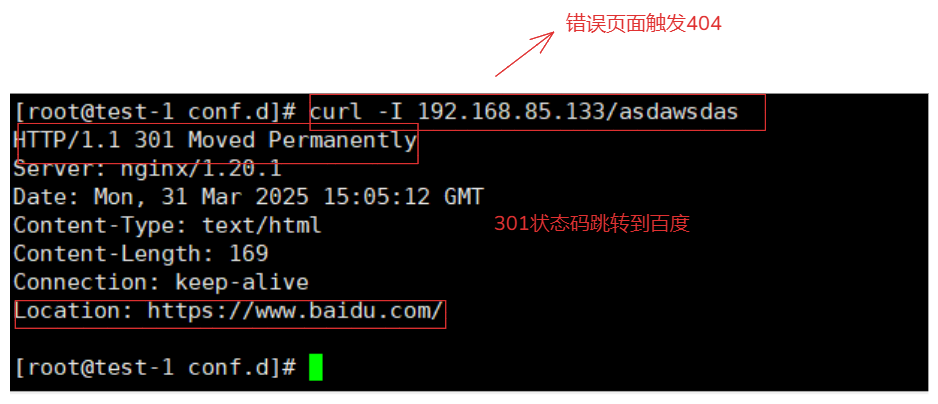
systemctl restart nginx
当访问由于这个页面没有触发状态码 404:
192.168.85.133/asdqweqkmlmzc/asdawsdas
触发error_page跳转百度状态码 301:
https://www.baidu.com/
5-4-3.访问内部的内部路由
1.配置
server{
listen 80;
server_name _;
charset utf-8;
location / {
root /www/80/;
index index.html;
}
# 出现404错误 直接访问当期服务器的 /404.html 文件
error_page 404 /404.html;
}
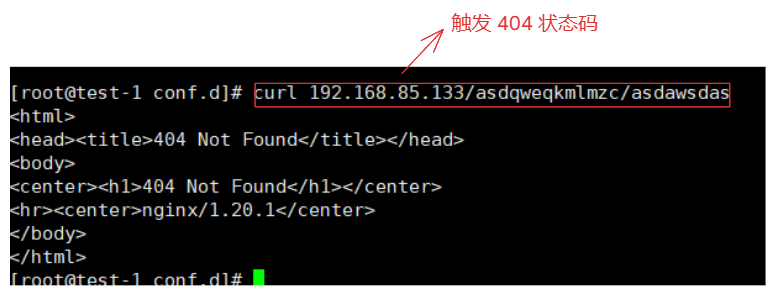
2.重启测试
systemctl restart nginx
当访问由于这个页面没有触发状态码 404:
curl 192.168.85.133/asdqweqkmlmzc/asdawsdas
触发error_page跳转百度状态码 301:
https://192.168.85.133/404.html
5-4-4.示例一
server {
listen 80;
server_name example.com;
root /path/to/your/static/files;
# 自定义 404 错误页面
error_page 404 /404;
# 处理常规请求
location / {
try_files $uri $uri/ =404;
}
# 提供自定义错误页面
location /404 {
# 确保这个路径与你的 404.html 文件的实际路径相匹配
alias /usr/share/nginx/html/;
index 404.html;
}
}
5-4-5.示例二
server {
listen 80;
server_name example.com;
root /path/to/your/frontend/build;
location / {
try_files $uri $uri/ /index.html;
}
error_page 404 /index.html;
error_page 500 502 503 504 /index.html;
}
try_files $uri $uri/ /index.html;:
这个指令尝试找到请求的文件或目录,如果都找不到,则回退到 /index.html。
这对于单页应用(SPA)非常重要,因为它允许前端路由接管所有路由逻辑。
error_page 404 /index.html;:
当发生 404 错误时(即请求的资源不存在),Nginx 会重定向到 /index.html。
这允许前端路由处理错误页面的显示。
error_page 500 502 503 504 /index.html;:
对于服务器错误(500、502、503、504),同样重定向到 /index.html。
这可以提供一个更友好的错误处理方式,在生产环境中进行更为详细的处理。
5-5.链接状态监控功能
**模块:**ngx_http_stub_status_module
**文档:**http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
**作用:**提供对基本状态信息的访问
指令:
指令 作用 stub_status使用后区域: server,location,在1.7.5版本后,指令需要加入一个任意参数。例如:stub_status on;使用方式:
server { listen 1111; server_name _; charset utf-8; location = /basic_status { stub_status on; # 开启status模块 } }
内容说明:
Active connections: 2 server accepts handled requests 3 3 3 Reading: 0 Writing: 1 Waiting: 1 # 数据说明: Active connections:当前活动客户端连接的数量,包括正在等待的连接。 accepts: 已接受的客户端连接总数。 handled:已处理的连接总数。通常,除非达到某些资源限制(例如worker_connections限制),否则参数值与accepts相同。 requests:客户端请求的总数。 Reading:nginx正在读取请求头的当前连接数。 Writing:nginx将响应写回客户端的当前连接数。 Waiting:等待请求的空闲客户端连接的当前数量。

5-6.http身份验证功能
**模块:**ngx_http_auth_basic_module
**文档:**https://nginx.org/en/docs/http/ngx_http_auth_basic_module.html
**作用:**允许通过使用"http"基本身份验证”协议验证用户名和密码来限制对资源的访问。
指令:
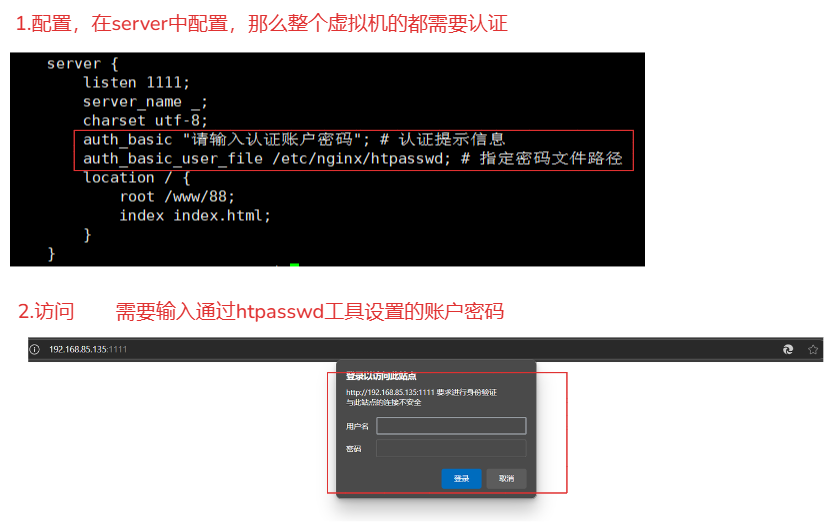
指令 作用 auth_basic使用后区域: http,server, location, limit_except,默认:auth_basic off;。使用:auth_basic "提示信息";auth_basic_user_file指定一个保存用户名和密码的文件,使用区域: http,server,location,limit_except,格式如下:name1:password1使用方式:
语法: http{ # 整个nginx的虚拟主机都会使用 server{ # 只有当前虚拟机使用 location { # 只有当前虚拟机匹配的url才使用 } } } # 需要借助htpasswd工具生成对应的密码文件 1.安装 sudo apt-get install apache2-utils yum -y install httpd-tools 2.创建一个htpasswd的密码文件,并添加账户 admin sudo htpasswd -c /etc/nginx/htpasswd admin 例如: server { listen 1111; server_name _; charset utf-8; auth_basic "请输入认证账户密码"; # 认证提示信息 auth_basic_user_file /etc/nginx/htpasswd; # 指定密码文件路径 location / { root /www/88; index index.html; } }
5-7.路径内部跳转功能
说明:
- 判断与跳转都来自于Nginx模块:ngx_http_rewrite_module
- 文档:https://nginx.org/en/docs/http/ngx_http_rewrite_module.html
1. if判断 # 可以根据内置变量或者设置的变量进行判断 作用于:server, location if ($slow) { # 进行if条件判断 limit_rate 10k; break; } 2. set 设置变量 作用:server, location, if 为指定变量设置值。该值可以包含文本、变量及其组合。 server { set $key var; } 3. rewrite 设置正则替换url进行跳转操作 # 可以使用常规的正则表达式进行操作 作用:server, location, if 跳转参数: last:基于虚拟机内部的实现的url跳转操作。对其所在的server{}标签重新发起修改后的URL请求,再次匹配location{}。 break:基于虚拟机内部的实现的url跳转操作。在本条规则匹配完毕后,终止匹配,不再匹配后面的location{}; redirect:返回带有302代码的临时重定向。 permanent:返回带有301代码的永久重定向。 location /download/ { rewrite ^(/download/.*)/media/(.*)\..*$ $1/mp3/$2.mp3 break; rewrite ^(/download/.*)/audio/(.*)\..*$ $1/mp3/$2.ra break; return 403; } 4. break 终止指令集操作 作用:server, location, if if ($slow) { limit_rate 10k; break; # 设置终止操作,到当前的位置就结束。 } 5. return 路由跳转指令 作用: server, location, if 注意:跳转操作需要使用301或者302状态码,其他的操作可以使用200或者404等状态码。 location { return 301 https://baidu.com; }if条件判断符号:
符号 作用 = 比较变量、字符串是否相等,相等为true、不等则为false != 比较变量、字符串是否不相等,不相等为true、相等为false ~ 区分大小写的正则匹配,匹配上为true,否则为false,支持正则 !~ 区分大小写的正则匹配,不匹配上为true,否则为false,支持正则 ~* 不区分大小写的正则匹配,匹配上为true,否则为false,支持正则 !~* 不区分大小写的正则匹配,不匹配上为true,否则为false,支持正则 return与rewrite对比:
特性 rewritereturn功能 对请求的 URI 进行重写 直接返回指定的状态码和响应内容 执行时机 rewrite阶段(早期)content阶段(后期)处理逻辑 修改请求路径,继续处理请求 终止请求处理,直接返回响应 性能开销 可能较高(正则表达式匹配) 较低 使用场景 URL 重写、隐藏路径、SEO 优化等 简单跳转、错误处理、自定义响应等
5-7-1.set指令
1.配置
server {
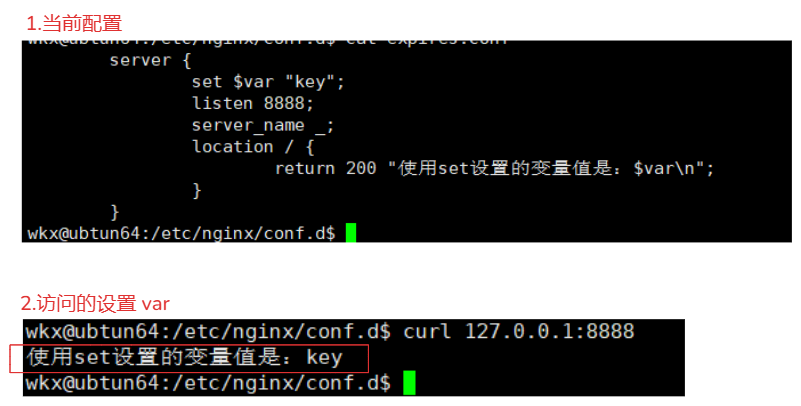
set $var "key"; # 设置变量 $var=变量名 "key"=变量值
listen 8888;
server_name _;
location / {
return 200 "使用set设置的变量值是:$var\n"; # 使用变量
}
}
2.测试查看
curl 127.0.0.1:8888
3.使用场景与注意事项
# 使用场景
1.设置动态的值,根据动态的值进行条件判断设置。
2.可以根据请求的 URI、参数、头部等条件,设置不同的变量值。
3.可以将请求的某些特征存储到变量中,并在日志中记录这些变量的值。
4.在重写规则中,可以通过 set 设置变量,然后根据变量值进行跳转。
5.在限流和限速的场景中,可以通过 set 设置变量来控制请求的速率。
6.可以根据请求的特征设置变量,用于实现安全策略,例如阻止某些请求。
# 注意:
1.在复杂的逻辑中,过度的使用可能会导致配置难以理解和维护。
2.set设置的值只能在固定的上下文下使用,例如:location设置的只能在location中使用,server只能在server下使用。
5-7-2.if指令
1.修改配置,根据不同的客户端进行判断显示不同的内容。
server {
listen 8888;
server_name _;
location / {
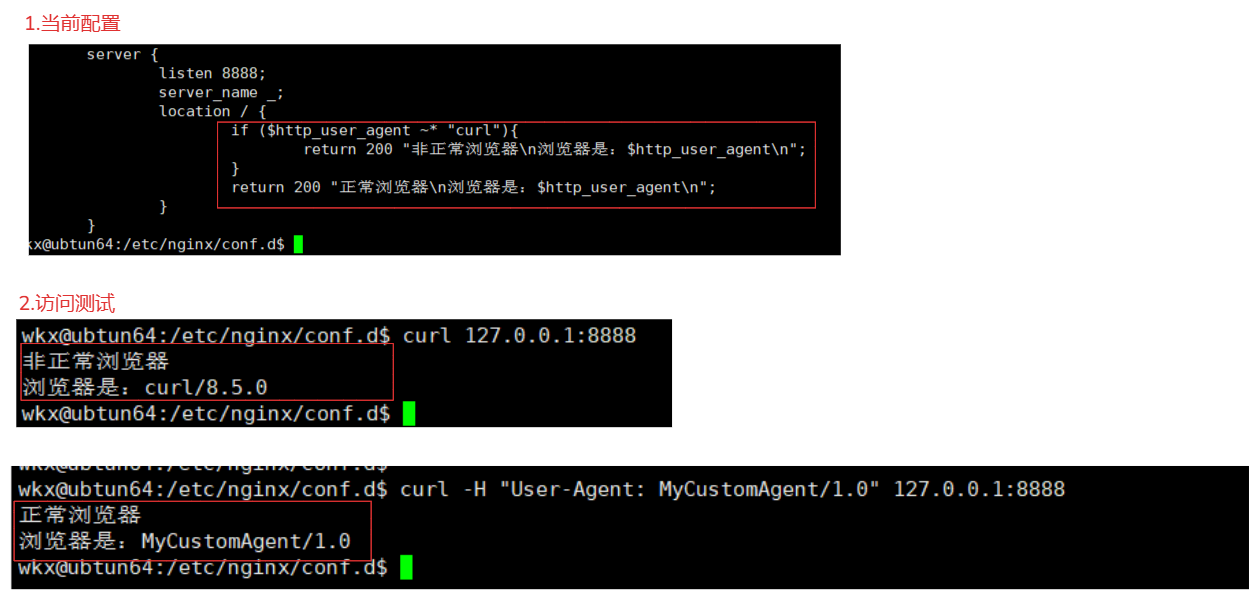
if ($http_user_agent ~* "curl"){
return 200 "非正常浏览器\n浏览器是:$http_user_agent\n";
}
return 200 "正常浏览器\n浏览器是:$http_user_agent\n";
}
}
说明:$http_user_agent ~* "curl"
$http_user_agent 是访问客户端的客户端User-Agent请求头的内容(一般存储当前访问的是什么类型的客户端)
~* 正则表达式,不区分大小写。
"curl" 匹配的值
2.测试
curl -H "User-Agent: MyCustomAgent/1.0" 127.0.0.1:8888 # 设置一个非curl的agent头
curl 127.0.0.1:8888 # 不设置
3.使用场景
1.根据User-Agent请求头判断当前访问的是手机客户端还是电脑客户端返回不同的适配方式。
map $http_user_agent $device_type {
default "desktop";
"~*mobile" "mobile";
"~*android" "mobile";
"~*iphone" "mobile";
"~*ipad" "tablet";
"~*tablet" "tablet";
}
server {
location / {
# 根据设备类型执行不同操作
if ($device_type = "mobile") {
return 200 "手机\n";
}
if ($device_type = "tablet") {
return 200 "平板\n";
}
return 200 "桌面\n";
}
}
}
2.根据Referer来判断是不是当前设置的主机名访问的还是其它网站跳转的,设置防盗链。
server {
listen 80;
server_name example.com;
# 定义允许的 Referer
valid_referers none blocked example.com www.example.com;
# 配置静态资源的 location
location ~* \.(jpg|jpeg|png|gif|css|js|mp4)$ {
# 如果 Referer 不合法,返回 403 Forbidden
if ($invalid_referer) {
return 403;
}
# 如果 Referer 合法,正常提供资源
root /path/to/your/static/files;
}
}
5-7-3.return指令
1.配置
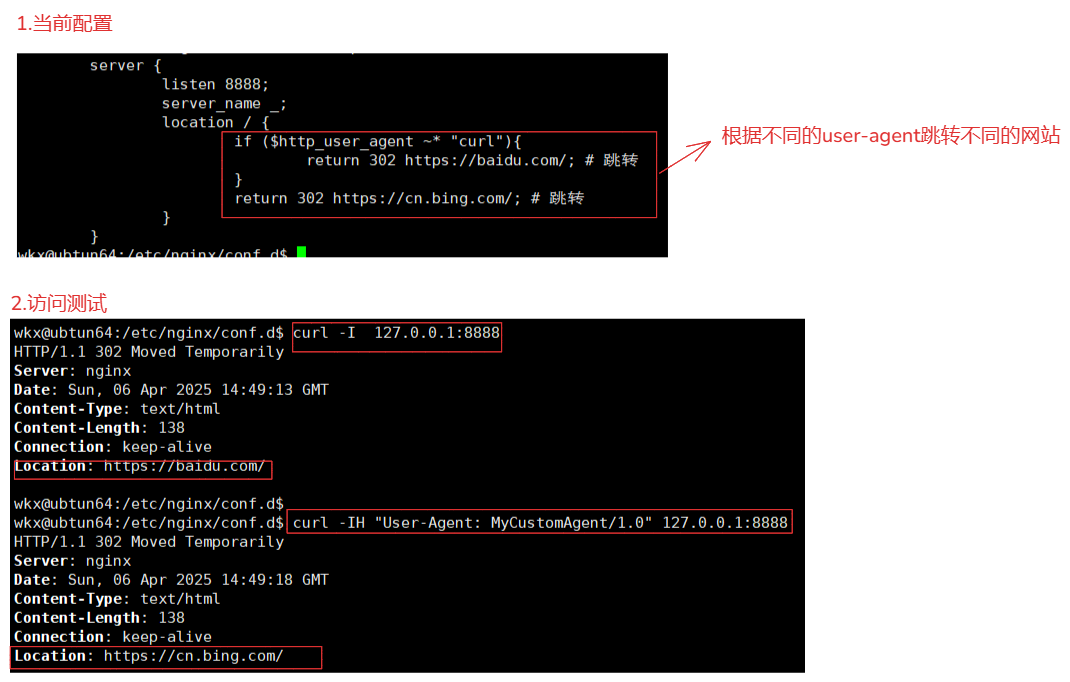
server {
listen 8888;
server_name _;
location / {
if ($http_user_agent ~* "curl"){
return 302 https://baidu.com/; # 跳转
}
return 302 https://cn.bing.com/; # 跳转
}
}
2.测试
curl -H "User-Agent: MyCustomAgent/1.0" 127.0.0.1:8888 # 设置一个非curl的agent头
curl 127.0.0.1:8888 # 不设置
3.注意事项
1.需要谨慎使用,避免出现问题。
2.确保上线文中使用return,避免与if指令或者其他指令出现冲突。
3.使用标准的 HTTP 状态码,并确保响应内容简洁且编码正确。
4.避免重定向循环,并在配置后进行充分的测试
5.注意状态码的使用20x是正常响应状态码,30x属于跳转类的状态码,40x属于错误的状态码。避免使用自定义状态码,使用http状态码。
4.场景
1.指定错误页面
error_page 404 /index.html;
location / {
return 404;
}
2.特殊场景,如果需要返回空响应(例如在某些安全场景中),可以使用 return 204;(无内容)。
location /api {
add_header Content-Type application/json;
return 200 '{"message": "success"}';
}
3.重定向跳转 # 避免创建重定向循环,这可能导致客户端无法访问资源。确保重定向的目标地址是正确的,并且不会导致无限循环。
1.永久重定向(301):如果需要永久重定向。
location / {
return 301 $scheme://example.com$request_uri; # 这会告诉客户端资源已永久移动到新位置。
}
2.临时重定向(302):如果需要临时重定向,
location / {
return 302 $scheme://example.com$request_uri; # 这会告诉客户端资源临时移动到新位置。
}
5.补充:
1.使用 2xx 状态码:
2xx 状态码表示请求成功,客户端可以正常处理响应内容。
当你需要返回文本或者静态资源时,可以使用2xx的状态码。
2.使用 3xx 状态码。
3xx 状态码表示重定向,客户端需要根据响应中的 Location 头信息重新发起请求。
永久重定向:当需要将请求永久重定向到另一个 URL 时,使用 301 状态码。
临时重定向:当需要将请求临时重定向到另一个 URL 时,使用 302 状态码。
3."为什么跳转必须使用 3xx 而不能使用 2xx?因为协议规定,所以需要按照协议进行执行。"
1.根据 HTTP 协议,2xx 状态码表示请求成功,客户端会直接处理响应内容,而不会发起新的请求。
2.3xx 状态码用于指示客户端请求的资源已经移动到新的位置,客户端需要根据 Location 头信息重新发起请求。
3.浏览器会根据 3xx 状态码和 Location 头信息自动跳转到新的 URL,而不会直接显示响应内容。
5-7-4.break指令
注意:
当前break指令单独拎出来使用没有任何意义,只有配件rewrite指令一起使用才有意义。# return与break也有相同的含义,而且比break更为好用。
例如当前情况:
server {
location / {
add_header Content-Type text/plain;
set $show "123456";
if ($show) {
limit_rate 10k; # limit_rate 10k; 生效,响应的传输速率被限制为每秒 10 KB。
break; # 终止,不会向下执行。
}
return 200 "Hello, World!";
}
}
修改后
server {
location / {
add_header Content-Type text/plain;
set $show "123456";
if ($show) {
return 200 "1231321231321!"; # 这样会更好。
}
return 200 "Hello, World!";
}
}
5-7-5.rewrite指令说明
使用:
rewrite 正则表达式 替换的内容(url) 指令;
指令:
pemanent 302 跳转
redirect 301 跳转
last 内部跳转一直匹配到没有location内 last为止。
break 终止匹配替换操作,只在这个location执行。
5-7-5-1.pemanent
rewrite 正则表达式 替换的内容 pemanent; # pemanent 是 301 永久重定向。
# 场景:
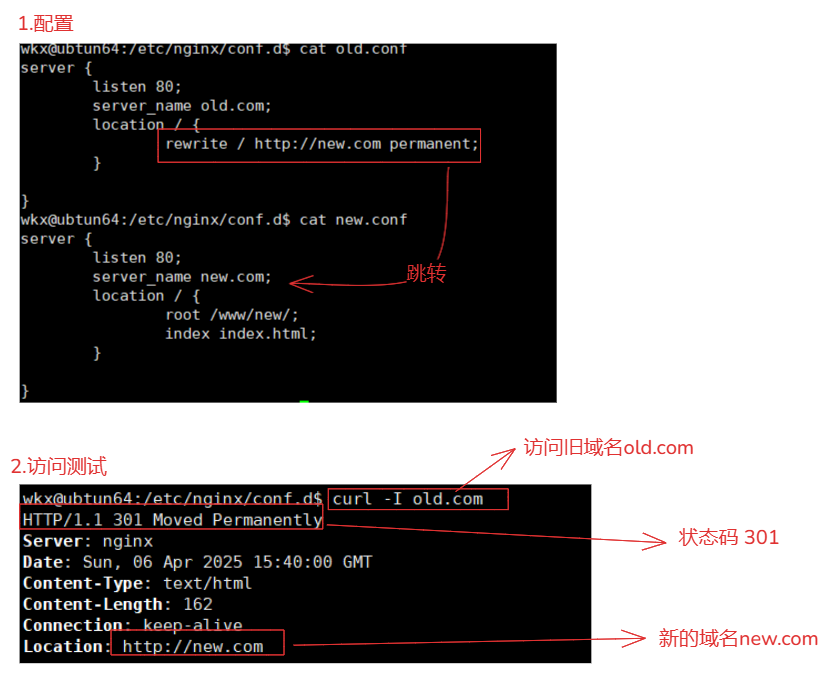
将一个旧的域名跳转到新域名,在公司换了一个新域名,但是客户端依然记录者旧的域名,为了解决旧域名跳转到域名。
1.配置-旧域名配置
server {
listen 80;
server_name old.com;
location / {
rewrite / http://new.com permanent; # 使用rewrite跳转
}
}
2.配置-新域名配置
server {
listen 80;
server_name new.com;
location / {
root /www/new;
index index.html;
}
}
3.测试
curl -I old.com
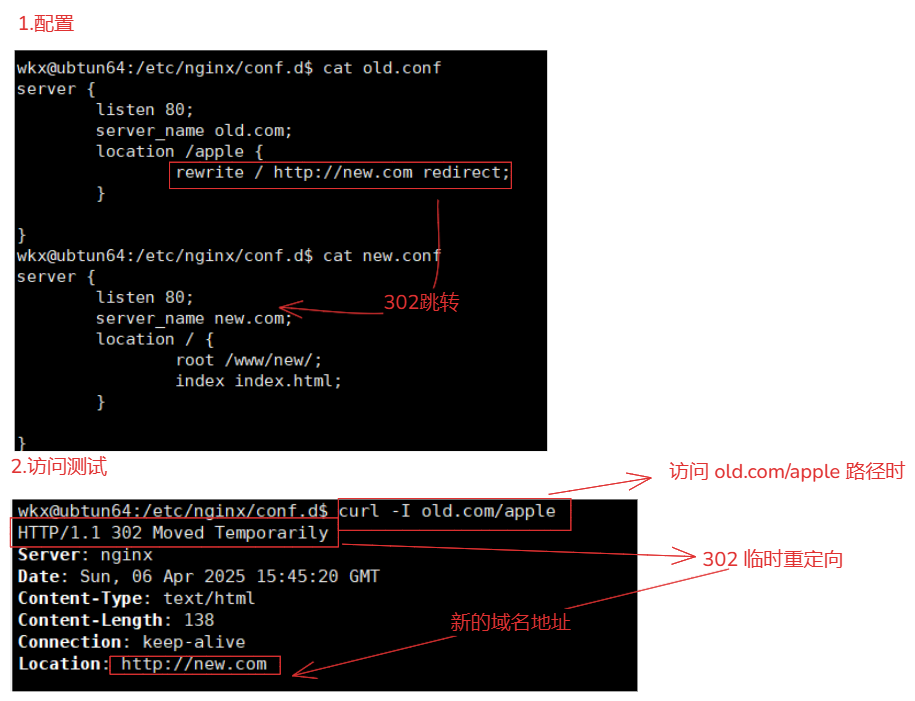
5-7-5-2.redirect
rewrite 正则表达式 替换的内容 redirect; # pemanent 是 301 永久重定向。
场景:
redirect 是 302 临时重定向,公司有了临时的活动,准备临时域名使用的
1.配置-旧域名配置
server {
listen 80;
server_name old.com;
location /apple {
rewrite / http://new.com redirect; # 使用rewrite跳转
}
}
2.配置-新域名配置
server {
listen 80;
server_name new.com;
location / {
root /www/new;
index index.html;
}
}
3.测试
curl -I old.com/apple
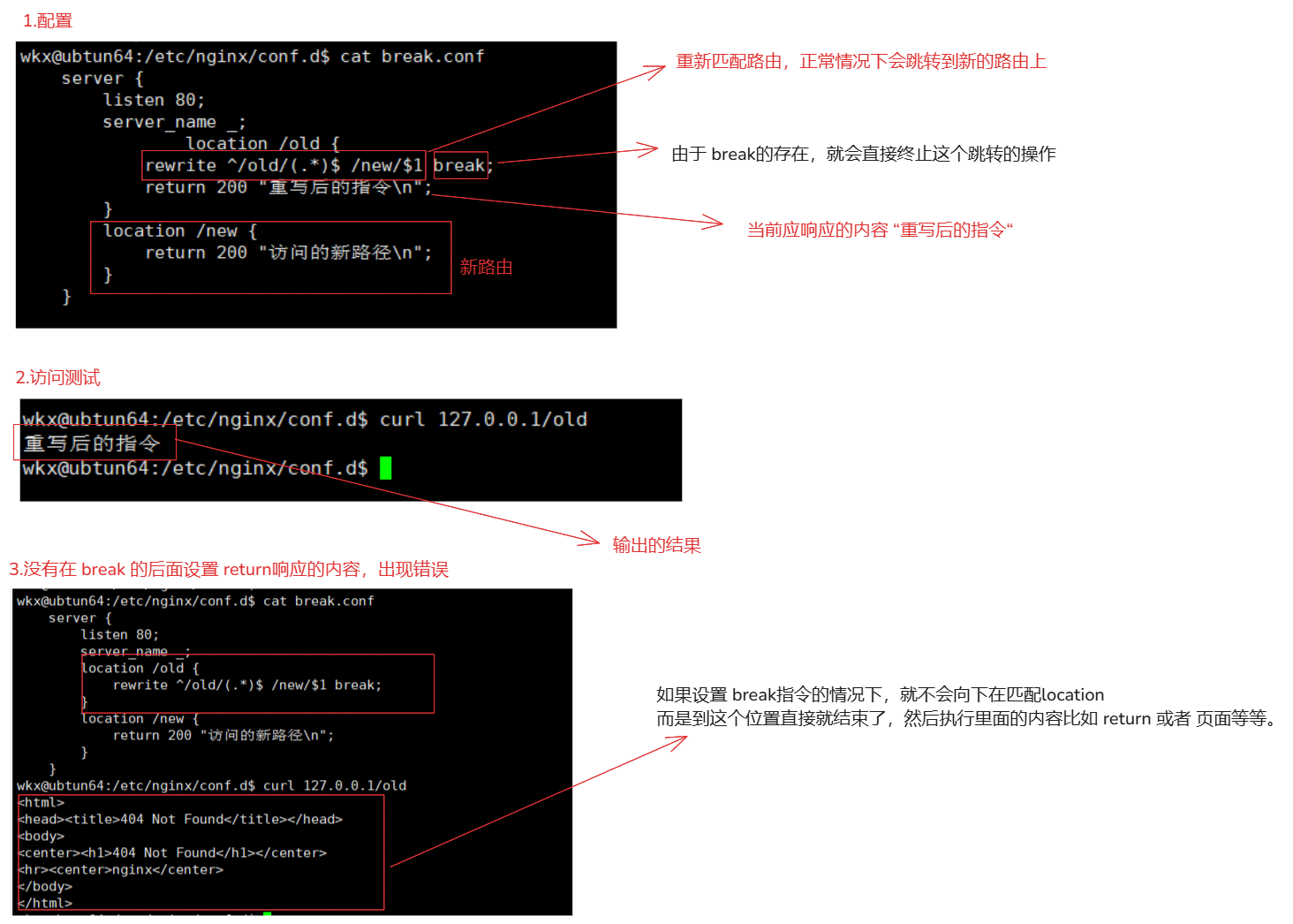
5-7-5-3.break
rewrite 正则表达式 替换的内容 break; # 终止
场景:
break 是终止到这里直接结束了。根本不会跳转或者匹配到新的路由上。
1.配置
server {
listen 80;
server_name _;
location /old {
rewrite ^/old/(.*)$ /new/$1 break;
return 200 "重写后的指令\n";
}
location /new {
return 200 "访问的新路径\n";
}
}
2.访问
curl 127.0.0.1/old
3.注意:
break 的作用就是终止操作,只要rewrite的这个指令参数是 break 就不会根据"rewrite的正则匹配向下匹配location"。
break 会终止当前 location 块中的进一步处理,但不会重新匹配 location 块。因此,虽然 URI 被重写为 /new,但请求仍然在当前 location /old 块中处理(在内部执行),不会跳转到 location /new 块。
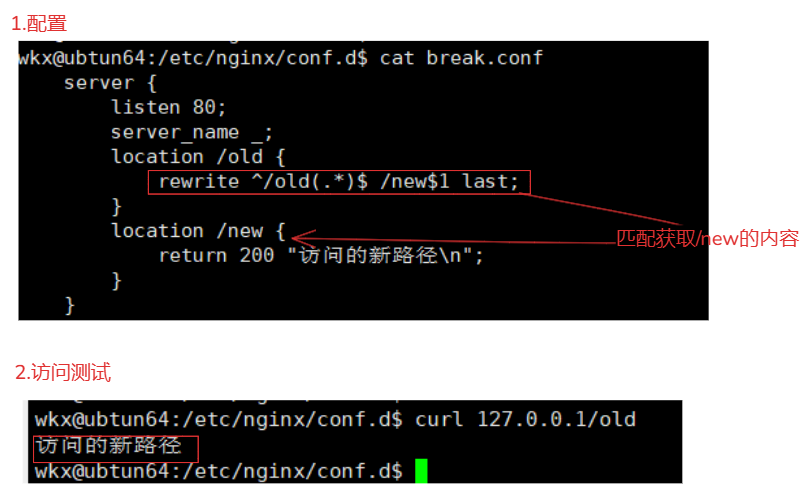
5-7-5-4.last
rewrite 正则表达式 替换的内容 last ; # 向下匹配,location的内部匹配,访问的url不会发生任何变化,内部变化。
场景:
last 就是向下匹配,只要匹配的location中的rewrite的指令是last就一直匹配。
1.配置
server {
listen 80;
server_name _;
location /old {
rewrite ^/old(.*)$ /new$1 last;
}
location /new {
return 200 "访问的新路径\n";
}
}
2.访问
curl 127.0.0.1/old
5-7-6.总结
1.关于last与break说明:
都是基于寻你急server内部的location进行url更新的,客户端访问的url不会发生任何变化。
last:如果rewrite 标记了 last那么就会向下执行再次匹配location{}。
break:如果rewrite标记了 那么就会不会在匹配,到这个loaction就会结束。
2.rewrite与return的区别:
rewrite:用于对请求的 URI 进行重写(修改)。常用于实现 URL 重写、跳转、隐藏真实路径等场景。根据正则表达式匹配请求的 URI,并将匹配到的部分替换为指定的内容,从而改变请求的路径。# 可以多次重写,直到不在匹配rewrite为止。
return:直接返回指定的状态码和响应内容。常用于直接返回错误页面、跳转到其他页面、返回特定的响应内容等场景。用于直接终止当前请求的处理,并返回指定的状态码和响应内容。# 一旦执行到return就会结束执行。
3.rewrite的使用
将 /old-uri 重写为 /new-uri。
rewrite ^/old-uri$ /new-uri last;
重定向:将所有请求重定向到另一个域名。
rewrite ^/(.*)$ http://new-domain.com/$1 permanent;
添加或删除路径:在请求 URI 前面添加或删除路径。
rewrite ^/(.*)$ /path/$1 last; # 添加/path/前缀
条件重写:根据请求参数进行重写。
if ($args ~* "^lang=(en|fr)$") {
rewrite ^/(.*)$ /$1?lang=$1 last;
}
隐藏 URL 中的文件扩展名。
rewrite ^/(.*)\.html$ /$1 last;
拒绝访问:拒绝访问某些特定的 URI。
rewrite ^/restricted-uri$ - last;
return 403;
URL 重写到 PHP 文件:将请求重写到 PHP 文件。
rewrite ^/(.*)$ /index.php?q=$1 last;
多个规则顺序:按照指定顺序应用多个重写规则。
rewrite ^/old-uri$ /new-uri1 last;
rewrite ^/another-old-uri$ /new-uri2 last;
5-8.IP限制模块
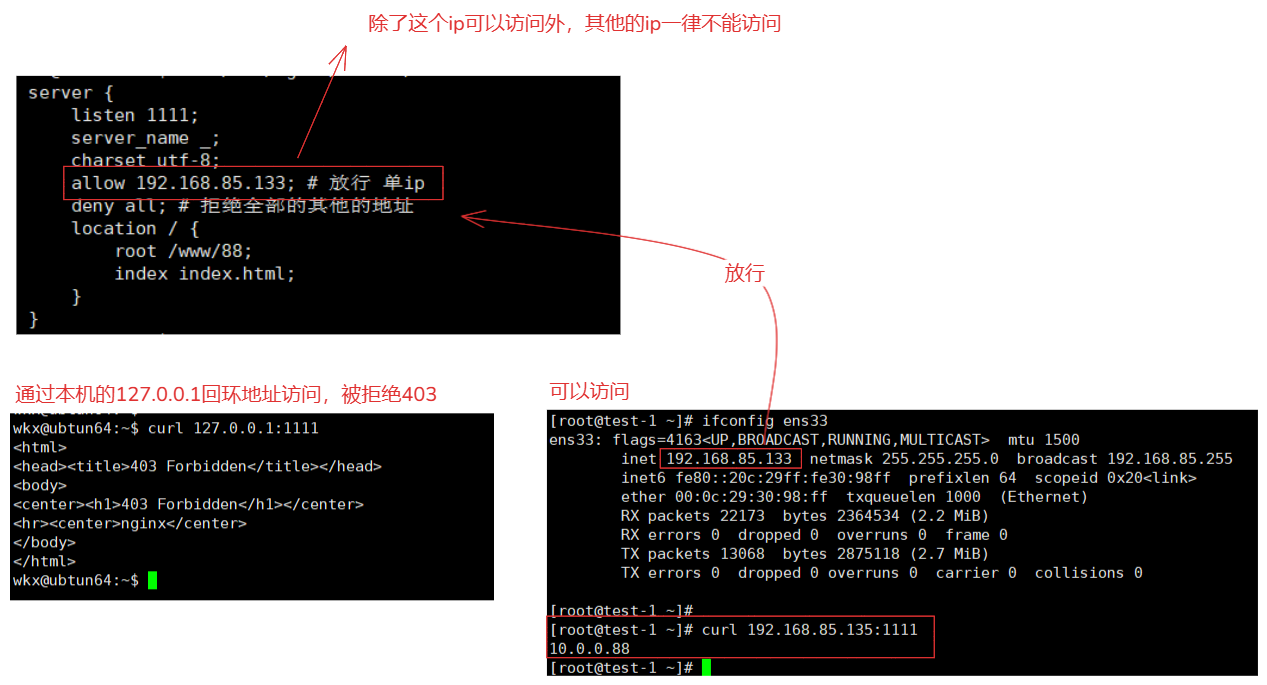
模块:ngx_http_access_module
文档:http://nginx.org/en/docs/http/ngx_http_access_module.html
作用:用于基于客户端 IP 地址进行访问控制。这个模块允许你限制或允许特定 IP 地址或 IP 地址段的访问
指令:
指令 作用 allow允许访问指定的网络或地址,作用区域: http,server,location,limit_except。all 允许全部deny拒绝访问指定的网络或地址,作用区域: http,server,location,limit_except。all 拒绝全部说明:
location / { deny 192.168.1.1; # 拒绝单ip allow 192.168.1.0/24; # 允许整个子网 allow 10.1.1.0/16; # 允许整个子网 allow 2001:0db8::/32; # 允许ipv6子网 allow unix:; # 允许来自 Unix 域套接字的请求 deny all; # 拒绝全部 } # 注意: 1.顺序很重要,allow 和 deny 指令的顺序很重要。Nginx 会按顺序检查这些指令,直到找到第一个匹配项 location / { deny all; # 拒绝全部 allow 192.168.85.135; # 允许单ip访问 } # 这样不正确,因为首先直接拒绝了全部,在放行单ip,这是不正确了,因为第一步直接就就拒绝了。 location / { allow all; # 允许全部 deny 192.168.85.135; # 拒绝单ip访问 } 2.使用时,需要充分进行测试,确保配置正确。使用:
server { listen 1111; server_name _; charset utf-8; allow 192.168.85.133; # 放行 单ip deny all; # 拒绝全部的其他的地址 location / { root /www/88; index index.html; } }
5-8.referer_module防盗链
模块:ngx_http_referer_module
文档:https://nginx.org/en/docs/http/ngx_http_referer_module.html
作用:用于组着referer请求头中无效值的访问站点。用途:1.设置防盗链(没有授权的情况下,不能引用你网站的资源,图片或者视频),2.防止未授权的访问(限制只有特定的来源才能访问某些资源),3.提高网站的安全性(通过限制请求来源,可以提高网站的安全性,减少恶意请求和攻击)。
指令:
指令 作用 valid_referers过设置 valid_referers,可以控制哪些Referer可以访问当前 Nginx 服务器上的资源,从而防止未经授权的访问和资源盗用。区域:server,location。说明:
语法: valid_referers none | blocked | server_names | string ...; 参数说明: none:表示请求头中缺少 Referer 字段,即空 Referer,空值。 blocked:表示请求头中的 Referer 字段不为空,但值被代理或防火墙删除了,这些值不以“http://”或“https://”开头。 server_names:表示使用配置中的 server_name 作为 Referer 的白名单。# 允许哪些访问资源 string:可以是具体的域名、通配符或正则表达式,用于定义允许的 Referer。 例如: # 只有来自 example.com 和 www.example.com 的请求才会被允许访问,其他来源的请求将返回 403 错误。 location / { valid_referers none blocked example.com www.example.com; if ($invalid_referer) { return 403; } }
6.知识点总结
6-1.关于实际环境中选择编译安装或者包管理工具
例如:需要搭建一个linux + nginx + php + mysql 这种lnmp的架构。
在工作中这些问题是根据部门(开发部)决定的,它们使用哪个版本开发,比如使用 php8,那么就需要使用他们指定的版本进行安装搭建。
| 特性 | 编译安装 | 包管理器安装 (如 yum 或 apt) |
|---|---|---|
安装复杂性 |
较高,需要手动下载源码、配置编译选项并安装。 | 较低,通常只需要几条命令即可完成安装。 |
最新版本 |
可以获取最新的 Nginx 版本,包括最新的功能和修复。 | 提供的版本可能不是最新的,而是经过稳定测试的版本。 |
自定义模块 |
可以根据需要编译特定的模块,优化 Nginx 的功能。 | 通常不支持自定义模块,除非使用额外的步骤。 |
性能优化 |
可以根据服务器的硬件配置进行优化,提高性能。 | 通常使用默认配置,性能优化有限。 |
依赖管理 |
需要手动处理依赖关系,确保所有必要的库和工具都已安装。 | 自动处理依赖关系,确保所有必要的库和工具都已安装。 |
更新管理 |
需要手动更新 Nginx,没有自动更新功能。 | 自动更新功能,确保 Nginx 始终保持最新版本。 |
稳定性 |
最新版本可能包含未经过广泛测试的特性或修复,可能存在稳定性问题。 | 经过社区测试,稳定性较高。 |
安装路径 |
可以自定义安装路径和配置参数。 | 安装路径通常固定,配置文件在 /etc/ 下,部署文件在 /var/www,路径结构相对复杂。 |
权限要求 |
通常需要 root 权限来安装和管理服务。 |
通常需要 root 权限来安装和管理服务。 |
社区支持 |
社区支持相对较少,需要自己解决遇到的问题。 | 社区支持较多,遇到问题时更容易找到解决方案。 |
适用场景 |
需要最新版本、特定模块或优化性能的用户。 | 适合大多数用户,特别是需要 |
编译安装:
适合需要最新版本、特定模块或优化性能的用户。
包安装:
适合大多数用户,特别是需要快速安装和管理 Nginx 的用户。
# 在实际生产环境中:
需要根据需求而定,包管理方式安装相对比较常见,适合大多数场景,如果需要特定模块或者特定功能优化场景,多数会选择编译安装。
6-1.301与302
301 属于永久重定向
302 属于临时重定向
业务角度:
301 当公司更新二级域名,要永久更新。 比如 京东的 360buy.com -> jd.cm
302 用于三级域名 临时添加。比如 京东的:jd.com -> pro123.jd.com
理论角度:
302重定向属于临时的,搜索引擎抓取最新的内容而保存旧的网址,搜索引擎会根据302,认为这个网址属于暂时的,优先级低
301属于永久重定向,搜索引擎会记录最新的地址,优先级设置高
7.Nginx代理
概念:
- 代理(Proxy)是一种网络技术,用于在客户端和服务器之间充当“中间人”,转发请求和响应。代理服务器可以是一个软件或硬件设备,它接收客户端的请求,然后将请求转发到目标服务器,并将服务器的响应返回给客户端。代理技术在网络中应用广泛,具有多种类型和功能。
代理分区:
- 正向代理
- 反向代理
正向代理(代理客户端):
- 正向代理是一种代理服务器,客户端通过它访问外部网络资源。客户端将请求发送到代理服务器,代理服务器再将请求转发到目标服务器,并将目标服务器的响应返回给客户端。
反向代理(代理服务器):
- 反向代理是一种代理服务器,客户端直接与它交互,而不知道后端服务器的存在。反向代理服务器接收客户端的请求,将请求转发到后端服务器,并将后端服务器的响应返回给客户端。
代理的应用场景:
- 在企业网络中,代理服务器可以用于访问控制、内容过滤和日志记录。
- 在Web应用中,反向代理服务器可以用于负载均衡、缓存和SSL/TLS终止。
- 在多租户环境中,代理服务器可以为每个租户提供独立的域名和访问控制。
- 在CDN中,代理服务器可以作为边缘节点,将内容缓存在离用户更近的位置,提高内容的访问速度。
总结:
- 代理技术是网络中应用广泛,通过客户端与服务器之间充当中间人的角色,将请求或者响应发送给服务端或者客户端。代理可以实现多种的功能,请求转发,缓存,负载均衡,安全增强,内容过滤,正向代理与反向代理可以在不同的场景中发挥不同的作用。是否是正向代理还是反向代理是区别于他们的代理角色是谁来区分的。
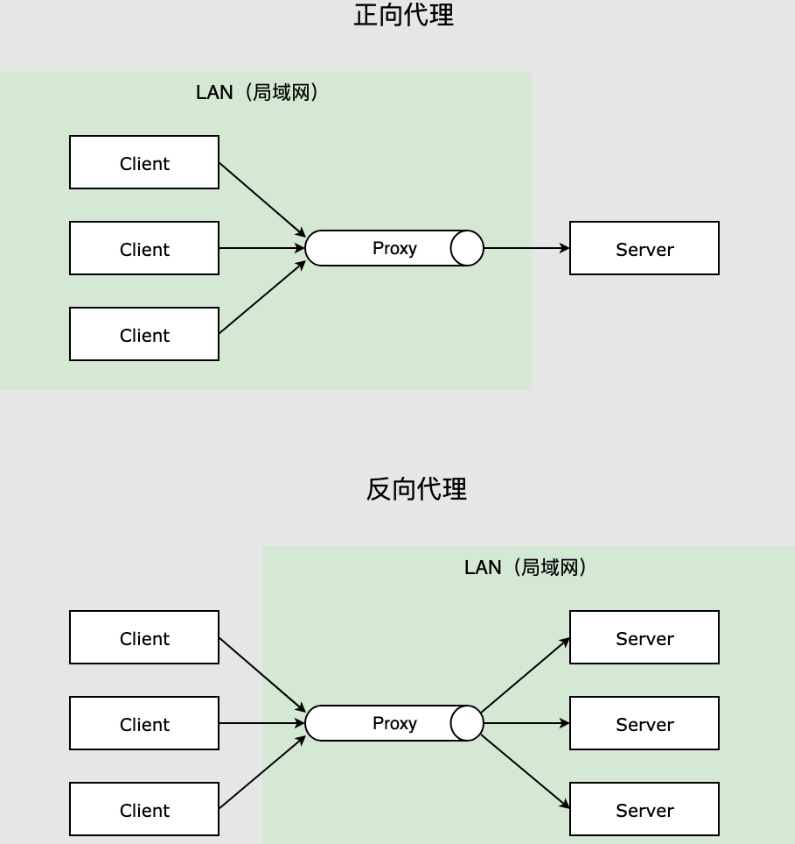
7-1.正向代理
概念:
- 代理客户端,当客户端通过代理服务器访问服务器获取需要的资源,客户端会向代理服务端发送请求并指定目标,然后代理服务器就会通过指定目标发送请求,目标服务器返回资源再由代理服务器将资源给到客户端。
说明:
- 正向代理最常见的就是我们使用的vpn技术,当我们访问国外的资源时,需要通过vpn将我们的请求转发给国外的服务器,这就是正向代理。
- 核心:客户端需要通过代理服务器访问到资源服务器。隐藏可客户端的一切。
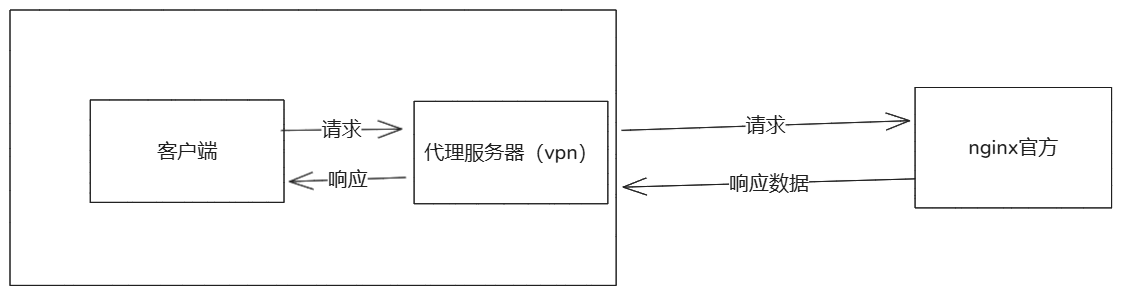
7-1-1.正向代理实现
| 服务器ip | 作用 |
|---|---|
| 192.168.85.133 | 作为一个外网网站(客户端无法进行访问,只有借助VPN角色才可以) |
| 192.168.85.135 | 作为一个VPN的角色 |
| 宿主机(192.168.85.1) | 作为一个客户端角色 |
使用了 nginx的 ngx_http_proxy_module 模块实现当前效果。
1.192.168.85.133 服务器配置 # 外网配置(真实服务器)
server{
listen 80;
server_name _;
charset utf-8;
location / {
root /www/80/;
index index.html;
}
}
2.192.168.85.135 服务器配置 # vpn配置(代理服务器)
server {
listen 80;
server_name _; # 设置域名
location / {
proxy_pass http://192.168.85.133; # 代理转发到server服务器
proxy_set_header Host $http_host; # 将cliten请求的请求头信息进行携带
proxy_set_header X-Real-IP $remote_addr; # 用于传递客户端的真实 IP 地址。
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; # 携带的真实地址
proxy_connect_timeout 60s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
}
}
# 涉及到的参数:
proxy_pass http://192.168.85.133; # 代理转发到server服务器
proxy_set_header X-Real-IP $remote_addr; # 用于传递客户端的真实 IP 地址。
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; # 携带的真实客户端请求地址
# 注意:
X-Forwarded-For 与 X-Real-IP都是获取真实的客户端ip,由于不同的后端程序识别的方式不同,一些应用程序可能只识别 X-Real-IP,而另一些可能只识别 X-Forwarded-For。同时设置提高兼容性,在某些复杂的网络架构中,可能需要同时使用这两个头部来满足不同的需求。例如,一个头部用于简单的日志记录,另一个头部用于更复杂的访问控制。
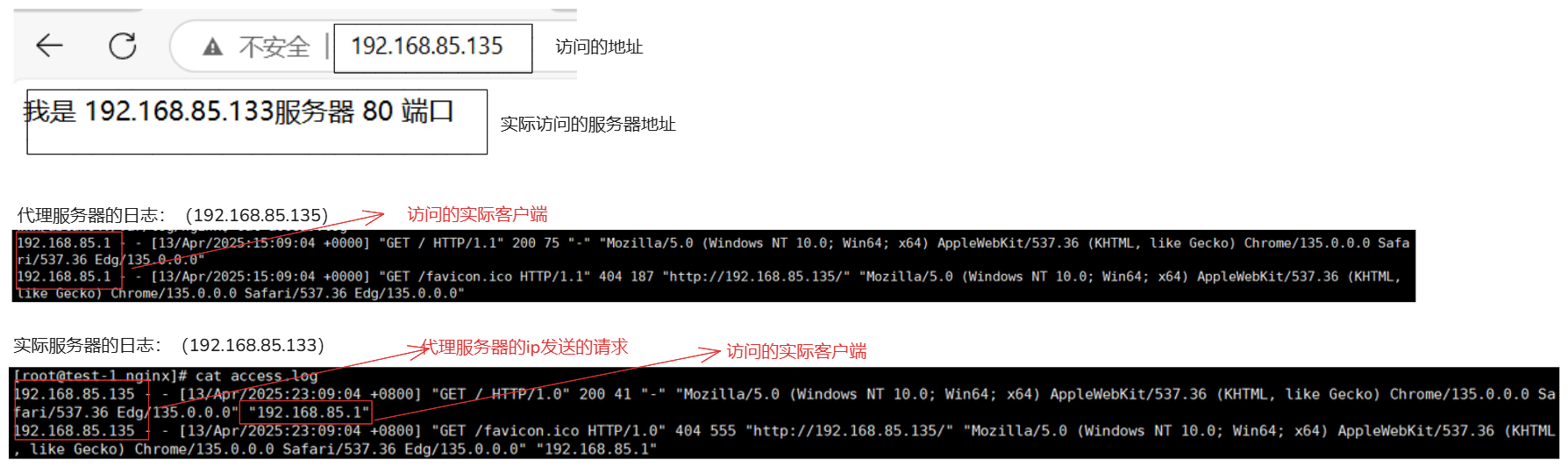
3.客户端访问,查看日志
4.访问流程
1.客户端访问 192.168.85.135
2.代理服务器接受到当前的访问请求,转发给了 proxy_pass http://192.168.85.133;
3.'192.168.85.133' 接受到了 '192.168.85.135'代理服务器的请求,并返回了响应(给了192.168.85.135代理服务器)。
4.在由 '192.168.85.135'代理服务器发送给客户端。
7-2.反向代理
概念:
- 代理服务端,当客户端发送请求时,其实请求是发送到代理服务器上,在有代理服务器发送到真是的服务器上,然后在将响应的数据发送到代理服务器,在由代理服务器发送到用户的客户端中。
说明:
- 是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
- 核心:客户端访问请求不是直接访问服务器而是由代理服务器转发给服务器。隐藏服务器的一切。
- 反向代理确实可以实现对服务端(即真实服务器)的隐藏包含了很多的好处。
- 安全性:通过隐藏后端服务器的IP地址,可以减少直接暴露给外部网络的风险,从而降低被攻击的可能性。攻击者无法直接访问后端服务器,只能通过代理服务器进行访问。
- 负载均衡:反向代理可以将请求分发到多个后端服务器,从而实现负载均衡。这不仅可以提高系统的可用性和性能,还可以在某个后端服务器出现故障时,将流量转移到其他健康的服务器上。
- 缓存:反向代理可以缓存静态内容,减少对后端服务器的请求,从而提高响应速度和减轻后端服务器的负担。
- SSL/TLS终止:可以直接在反向代理服务器上处理SSL/TLS加密和解密,减轻后端服务器的负担。
- 内容分发:反向代理可以将内容分发到多个地理位置的服务器,提高内容的访问速度(CDN)。
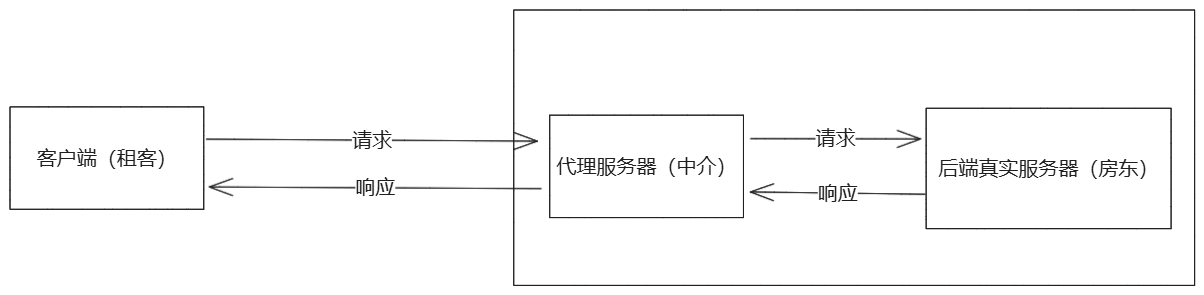
7-2-1.反向代理实现
| 服务器ip | 作用 |
|---|---|
| 127.0.0.1(192.168.85.133服务器内的回环地址) | 实际的真实服务器 |
| 192.168.85.135 | 代理服务器 |
| 宿主机(192.168.85.1) | 作为一个客户端角色 |
# 使用了 nginx的 ngx_http_proxy_module 模块实现当前效果。
1.真实服务器配置 # 127.0.0.1配置,只能在本地访问,外部无法访问回环地址
server {
listen 127.0.0.1:8110;
server_name _;
location / {
root /www/8110/;
index index.html;
}
}
2.代理服务器配置
server {
listen 80;
server_name _; # 设置域名
location / {
proxy_pass http://127.0.0.1:8110; # 代理转发到server服务器的内网
proxy_set_header Host $http_host; # 将cliten请求的请求头信息进行携带
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; # 携带的真实地址
proxy_set_header X-Real-IP $remote_addr;
proxy_connect_timeout 60s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffering on;
proxy_buffer_size 32k;
proxy_buffers 4 128k;
}
}
3.客户端访问
4.访问流程
1.客户端访问 192.168.85.135
2.代理服务器接受到当前的访问请求,转发给了 proxy_pass http://127.0.0.1:8110;
3.'127.0.0.1:8110' 接受请求,将响应发送给 '192.168.85.135'。
4.在由 '192.168.85.135'代理服务器发送给客户端。
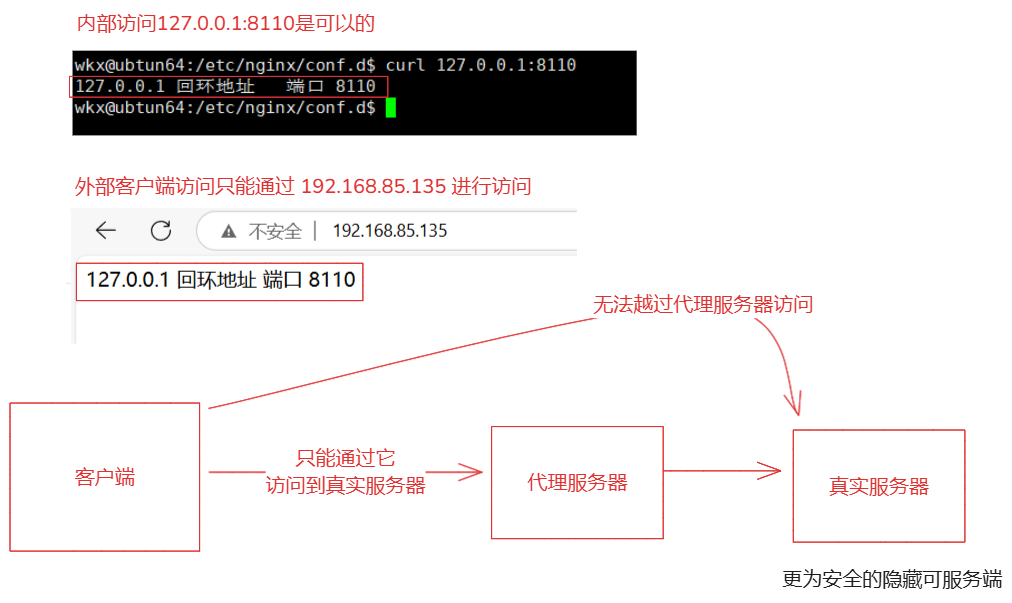
7-3.Nginx代理模块
7-3-1. HTTP 协议的代理
模块:ngx_http_proxy_module
文档:https://nginx.org/en/docs/http/ngx_http_proxy_module.html
作用:
- 可以将请求转发给其他的服务器上的应用程序或者本机的某个应用程序,将请求转发到后端服务器(如反向代理到另一个 Web 服务器或应用服务器),它处理的是 HTTP 请求和响应。
- 客户端的 HTTP 请求转发到后端服务器,并将后端服务器的 HTTP 响应返回给客户端。
- 主要支持的协议:HTTP/1.0,HTTP/1.1,HTTP/2
- 属于应用层的转发模块
常用指令:
指令 作用 proxy_pass转发的服务器的地址,可以是 HTTP/HTTPS 地址,也可以是 Unix 套接字。使用区域: location,if in location,limit_exceptproxy_set_header设置转发到后端服务器的请求头。使用区域: http,server,locationproxy_connect_timeout设置代理服务器与后端服务器建立连接的超时时间。默认60秒,注意不能超过75秒。区域: http,server,locationproxy_read_timeout设置代理服务器从后端服务器读取响应的超时时间。默认60秒,仅在两个连续的读取操作中设置,不适用于整个响应,如果代理服务器在此时间内没有传输任何内容,则连接关闭。区域: http,server,locationproxy_send_timeout设置代理服务器发送请求到服务器的超时时间,默认60秒,区域: http,server,locationproxy_ignore_client_abort确定当客户端关闭连接而不等待响应时,是否应关闭与代理服务器的连接。默认off,区域: http,server,location。当客户端在请求过程中突然断开连接时,代理服务器会立即终止与后端服务器的连接,尤其是处理一些长时间的请求,通过设置proxy_ignore_client_abort on;,代理服务器将忽略客户端的断开行为,继续将请求发送到后端服务器,直到后端服务器处理完成。proxy_buffering决定是否对后端服务器的 响应正文和第一部分正文进行缓冲。默认on。当缓冲被禁用时,响应会在收到后立即同步传递给客户端。nginx不会尝试从代理服务器读取整个响应。区域:http,server,locationproxy_buffers设置 响应正文缓冲区的数量和大小。默认8 4k或者8 8k,此参数与proxy_buffering关联关系。区域:http,server,locationproxy_busy_buffers_size用于限制 正在发送响应到客户端的缓冲区的总大小。当 Nginx 开始向客户端发送响应数据时,会占用一部分缓冲区用于发送数据,这部分缓冲区被称为“繁忙缓冲区”(busy buffers)。proxy_busy_buffers_size就是用于设置这部分繁忙缓冲区的最大大小。区域:http,server,location。注意:``proxy_busy_buffers_size的值必须大于或等于 proxy_buffer_size和 proxy_buffers中单个缓冲区大小的最大值。计算方式:proxy_buffer_size < proxy_busy_buffers_size < proxy_buffers 值之间`proxy_buffer_size从后端服务器读取 响应头时的缓冲区大小,如果响应头的大小超过了这个缓冲区的大小,那么就会出错。默认情况下大小等于一个内存页大小通常是4K 或 8K,区域:http,server,location。proxy_cache是决定是否对后端服务器的响应进行缓存,以及缓存的存储位置。启用缓存可以显著提高响应速度,减轻后端服务器的负载,尤其适用于静态内容或不经常变化的动态内容。区域: http,server,location。zone:指定缓存区域的名称,该名称在 http块中通过 proxy_cache_path 指令定义。,off禁用缓存。默认是off。proxy_cache_path设置缓存的路径和其他参数。默认区域: httpproxy_cache_valid为不同的响应代码设置缓存时间。默认区域: http,server,locationproxy_no_cache定义不将响应保存到缓存的条件。默认区域: http,server,locationproxy_cache_methods列出的客户端请求方法进行缓存。默认: GET HEAD;默认区域:http,server,location``proxy_redirect设置代理服务器响应的“Location”和“Refresh”标头字段中内容。默认:default,默认区域: http,server,locationproxy_cache_key定义缓存的key,默认 proxy_cache_key $scheme$proxy_host$request_uri;,默认区域:http,server,location示例:
http{ proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m use_temp_path=off; 解释: /data/nginx/cache:缓存文件存储路径。 levels=1:2:缓存目录的层级结构。 keys_zone=my_cache:10m:缓存区域的名称和大小(10MB) max_size=10g:缓存的最大大小(10GB)。 inactive=60m:缓存条目在没有被访问的情况下保留的时间(60分钟)。 use_temp_path=off:直接将缓存数据写入最终位置,而不是先写入临时文件。 server { listen 80; server_name example.com; location / { proxy_pass http://backend.example.com; # 将请求转发到后端服务器 proxy_set_header Host $host; # 设置 Host 请求头 proxy_set_header X-Real-IP $remote_addr; # 设置客户端的真实 IP proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; # 添加 X-Forwarded-For 请求头 真实IP proxy_set_header X-Forwarded-Proto $scheme; # 设置请求的协议 proxy_redirect http://backend.example.com/ http://example.com/; # 如果后端服务器返回的 Location 或 Refresh 头中包含 http://backend.example.com/,Nginx 会将其替换为 http://example.com/。 proxy_connect_timeout 60s; # 设置 代理服务器与后端服务器的连接超时时间 proxy_read_timeout 90s; # 设置 代理服务器与后端服务器的响应超时时间 proxy_send_timeout 60s; # 设置 代理服务器与后端服务器的请求超时时间 proxy_buffer_size 16k; # 对请求头的缓存区 proxy_buffering on; # 开启缓冲区 proxy_buffers 4 16k; # 对正文的缓存区 proxy_busy_buffers_size 32k; # 对影响头缓冲区 proxy_cache my_cache; # 定义用于缓存的共享内存区域 proxy_cache_valid 200 302 10m; # 200 与 302 状态吗响应缓存10分钟 proxy_cache_valid 404 1m; # 404响应状态码缓存1分钟 proxy_cache_methods GET HEAD POST; # 指定哪些 HTTP 方法的响应可以被缓存,GET POST HEAD。 proxy_no_cache $http_pragma $http_authorization; # 设置不进行缓存。 proxy_no_cache $cookie_nocache $arg_nocache$arg_comment; # 设置不进行缓存。 proxy_no_cache $http_pragma $http_authorization; # 设置不进行缓存。 } } }
7-3-2.FastCGI代理
模块:ngx_http_fastcgi_module
文档:https://nginx.org/en/docs/http/ngx_http_fastcgi_module.html
作用:
- 允许将请求传递给fastcgi服务器, 用于处理动态内容。
- 是快速通用网关接口是一种让交互程序与Web服务器通信的协议。是 CGI(Common Gateway Interface)的增强版本。它主要用于在 Web 服务器(如 Nginx 或 Apache)和应用程序服务器(如 PHP-FPM)之间进行高效的数据交换。
- FastCGI属于应用层的协议,用于web服务器与应用服务器之间的通信,通过可靠流式传输来传输数据(如 Unix Domain Socket 或 TCP)。
与http协议的区别:
特性 HTTP 协议 FastCGI 协议 工作方式 每次请求都需要建立新的连接,请求结束后关闭连接 使用持久连接,可以处理多个请求,减少了连接和断开的开销 协议格式 使用文本和标头来定义请求和响应的格式 使用二进制格式,提高数据传输效率 性能 每次请求都需要重新建立连接,性能较低 通过复用预先创建的进程和持久连接,性能更高 使用场景 客户端与服务器之间的通信 Web 服务器与应用程序服务器之间的通信 使用场景:
- 动态网页生成,如博客系统,电子商务平台等等。
- web应用程序开发,基于脚本语言(python,php,perl)构建的应用程序。
- 高并发访问,大量的并发请求的网站,可以提供更好的性能。
常用于项目语言:
- 通过 PHP-FPM(FastCGI Process Manager)来处理 PHP 脚本。
- 某些 Python Web 框架(如 Django)可以通过 FastCGI 提供服务。
- Perl 也支持 FastCGI,用于构建高性能的 Web 应用。
常用指令:
指令 说明 fastcgi_pass指定 FastCGI 服务器的地址,用于将请求转发到后端的 FastCGI 服务(如 PHP-FPM)。可以是 IP 地址和端口,或者是 Unix 域套接字路径。使用区域: location,if in locationfastcgi_index设置默认的索引文件名。当请求的 URI 以斜杠结尾时,Nginx 会自动追加这个文件名作为默认的索引文件。例如,当请求 /时,会尝试加载/index.php。使用区域:http,server,locationfastcgi_param用于向 FastCGI 服务器传递参数。这些参数可以是环境变量、请求头或其他自定义变量。例如, SCRIPT_FILENAME参数用于指定要执行的脚本文件路径。使用区域:http,server,locationfastcgi_buffering启用或禁用来自FastCGI服务器的响应缓冲。默认:on,使用区域: http,server,locationfastcgi_buffers配置 Nginx 用于读取 FastCGI 服务器响应内容的缓冲区数量和大小。通过调整这些缓冲区,可以优化响应的读取效率,特别是在处理大响应时。默认:`8 4k fastcgi_buffer_size设置读取 FastCGI 服务器响应首部内容的缓冲区大小。较大的缓冲区可以减少读取次数,提高性能,但会占用更多内存。默认:`4k fastcgi_read_timeout设置Nginx从 FastCGI 服务器读取响应的超时时间。如果 FastCGI 服务器响应时间过长,Nginx 会关闭连接。默认60s。区域: http,server,locationfastcgi_connect_timeout设置Nginx 与 FastCGI 服务器建立连接的超时时间。如果连接时间过长,Nginx 会放弃连接尝试。默认是60s,最大不能超过75s。区域: http,server,locationfastcgi_send_timeout设置Nginx将请求传输到FastCGI 超时时间。默认60s。区域: http,server,locationfastcgi_cache启用或禁用 FastCGI 缓存功能。通过缓存可以减少对后端 FastCGI 服务器的请求,提高响应速度,减轻服务器负载。 fastcgi_cache_key定义缓存键的格式,用于标识缓存中的响应。通过合理的缓存键,可以确保缓存的准确性和高效性。 fastcgi_cache_valid设置不同 HTTP 状态码的缓存时间。可以根据响应的状态码来决定缓存的时长,例如,将 200 状态码的响应缓存 10 分钟,而将 404 状态码的响应缓存 1 分钟。 fastcgi_cache_methods指定哪些 HTTP 请求方法的响应可以被缓存。通常,GET 和 HEAD 请求的响应会被缓存,而 POST 请求的响应通常不会被缓存。 fastcgi_cache_min_uses设置请求次数,在达到此次数后,响应才会被缓存。这可以防止不常访问的资源占用缓存空间。 fastcgi_cache_path配置缓存存储路径及相关参数,包括缓存的存储位置、大小、过期时间等。此指令用于定义缓存的整体行为和存储策略。区域: httpfastcgi_cache_bypass用于控制是否绕过 FastCGI 缓存的指令。它允许你根据特定条件决定是否直接从后端 FastCGI 服务器获取响应,而不是使用缓存中的数据。当 fastcgi_cache_bypass条件为真,直接从后端FastCGI 响应。适用于实时更新或者动态内容。fastcgi_no_cache当条件为真时,Nginx 不会将响应存储到缓存中。适用于动态内容或需要实时更新的场景。 示例:
http { # 配置 FastCGI 缓存路径 fastcgi_cache_path /var/cache/nginx levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m; server { listen 80; server_name example.com; root /var/www/example.com; # 配置缓存相关参数 fastcgi_cache_key "$scheme$request_method$host$request_uri"; # 定义缓存的key名 fastcgi_cache_methods GET HEAD; # 哪些方法进行缓存 fastcgi_cache_min_uses 2; # 设置请求的次数,超过或者等于2次才会被缓存 fastcgi_cache_valid 200 301 302 1h; # 哪些状态码进行缓存,缓存多久 fastcgi_cache_valid 404 1m; # 哪些状态码进行缓存,缓存多久 location / { try_files $uri $uri/ /index.php?$args; } location ~ \.php$ { # 指定 FastCGI 服务器地址 fastcgi_pass unix:/var/run/php/php7.4-fpm.sock; # fastcgi_pass localhost:9000; # 或者使用ip地址 # 设置默认索引文件 fastcgi_index index.php; # 首页文件 # 传递参数给 FastCGI 服务器,设置默认的环境变量,需要设置FastCGI协议认识的这些环境变量名称。 fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; fastcgi_param QUERY_STRING $query_string; fastcgi_param REQUEST_METHOD $request_method; fastcgi_param CONTENT_TYPE $content_type; fastcgi_param CONTENT_LENGTH $content_length; include fastcgi_params; # 引用默认fastcgi使用参数 # 配置 FastCGI 缓存 fastcgi_cache my_cache; # 使用名为my_cache缓存空间 # 设置绕过缓存 fastcgi_cache_bypass $cookie_nocache $arg_nocache$arg_comment; fastcgi_cache_bypass $http_pragma $http_authorization; # 设置不缓存的条件 fastcgi_no_cache $cookie_nocache $arg_nocache$arg_comment; fastcgi_no_cache $http_pragma $http_authorization; # 设置超时时间 fastcgi_connect_timeout 10s; fastcgi_read_timeout 300s; fastcgi_send_timeout 300s; # 设置缓冲区大小 fastcgi_buffer_size 32k; fastcgi_buffers 4 16k; } # 配置静态文件缓存 location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ { expires 30d; # 缓存30天 access_log off; # 不记录日志 } # 配置错误页面 error_page 404 /404.html; error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } } } # 关于绕过缓存的参数说明 $cookie_nocache: 如果请求中包含特定的 Cookie(如 nocache),则绕过缓存。 例如,用户可以通过设置 nocache=1 的 Cookie 来强制获取实时内容。 $arg_nocache: 如果请求的查询参数中包含 nocache,则绕过缓存。 例如,URL 中包含 ?nocache=1 时,Nginx 将直接从后端获取响应。 $arg_comment: 如果请求的查询参数中包含 comment,则绕过缓存。 例如,URL 中包含 ?comment=1 时,Nginx 将直接从后端获取响应。 $http_pragma: 如果请求头中包含 Pragma: no-cache,则绕过缓存。 通常用于浏览器请求中,表示请求不应使用缓存。 $http_authorization: 如果请求头中包含 Authorization,则绕过缓存。 通常用于需要身份验证的请求,这些请求通常需要实时处理。 或者设置 location ~* \.php& { fastcgi_pass unix:/var/run/php/php7.4-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; # 启用 FastCGI 缓存 fastcgi_cache my_cache; fastcgi_cache_valid 200 301 302 1h; fastcgi_cache_valid 404 1m; # 定义缓存键 fastcgi_cache_key "$scheme$request_method$host$request_uri"; # 设置缓存方法 fastcgi_cache_methods GET HEAD; # 设置绕过缓存的条件,使用变量强制绕过缓存 set $no_cache 0; if ($request_method = POST) { set $no_cache 1; } fastcgi_cache_bypass $no_cache; fastcgi_no_cache $no_cache; }
7-3-3.uWSGI代理
模块:ngx_http_uwsgi_module
文档:https://nginx.org/en/docs/http/ngx_http_uwsgi_module.html
作用:
- 用于与 uWSGI 应用服务器进行通信,从而实现 Nginx 作为前端服务器,将请求转发给后端的 uWSGI 应用程序。
- 它支持 uWSGI 协议,使得 Nginx 能够高效地处理动态内容请求。
- 属于应用层的协议,主要用于Python 应用程序设计的通信协议,主要用于 Web 应用程序服务器(如 uWSGI 服务器)和 Web 服务器(如 Nginx)之间的通信。
与HTTP的区别:
特性 uWSGI 协议 HTTP 协议 目标 轻量级的协议,专属于搞笑的传输请求和响应数据,减少了不必要的开销。专门为Python应用程序设计,能够支持Python的特性如wsgi规范。 属于通用的无状态协议,广泛用于 Web 浏览器和服务器之间的通信。HTTP 协议支持多种请求方法(如 GET、POST、PUT、DELETE 等),并提供了丰富的头部字段和状态码。 性能 比HTTP协议更高效,因为舍弃了不必要的请求头部,和复杂的解析过程。处理请求和响应时延迟较低,适合高性能的 Web 应用。 虽然强大,但是相对来说比较复杂,会产生额外的开销。HTTP 协议是 Web 通信的标准协议,广泛支持,但不一定是最优的内部通信协议。 头部信息 头部信息简单,只有必要的请求信息,如请求方法,uri查询字符串等。允许通过环境变量传入额外的信息,这些信息会被uwsgi应用程序直接使用。 http它的请求头就比较复杂,如请求头( Host、User-Agent、Content-Type等),响应头(Content-Length、Cache-Control等)。它的请求头是标准化的,适用于各种类型的web通信应用场景 uWSGI 协议主要用于 Web 服务器(如 Nginx)和应用服务器(如 uWSGI)之间的内部通信。 uWSGI 协议特别适合 Python 应用程序,因为它能够更好地支持 WSGI 规范。 HTTP 协议广泛用于浏览器和服务器之间的通信,也适用于不同类型的 Web 服务之间的通信。HTTP 协议是 Web 应用的通用协议,适用于外部客户端(如浏览器)与服务器之间的通信。 实现方式 它是一种二进制的协议,通过特定的响应格式传输请求或者响应。通过环境变量传递请求信息,这些环境变量可以直接被python使用。 HTTP 协议是一种文本协议,请求和响应数据以文本形式传输。HTTP 协议的格式和字段是标准化的,适用于各种类型的 Web 应用。 uWSGI 协议和 HTTP 协议各有优势,适用于不同的场景。uWSGI 协议更适合高性能的 Python Web 应用,而 HTTP 协议则是一种通用的、功能强大的 Web 通信协议。在实际应用中,Nginx 通常作为前端服务器,通过 uWSGI 协议将请求转发给后端的 uWSGI 应用服务器,从而实现高效的动态内容处理。 # 本质: uWSGI 协议的核心作用确实是将 HTTP 请求和响应进行转换和处理,使其能够被 uWSGI 应用服务器理解和处理。 python的框架可以使用uwsgi的软件进行管理结合nginx进行配合可以更高效。常用指令:
指令 作用说明 uwsgi_pass指定 uWSGI 服务器的地址,可以是 IP 地址、域名或 Unix 套接字。例如: uwsgi_pass localhost:9000; 或者 uwsgi_pass uwsgi://localhost:9000; 或者 uwsgi_pass suwsgi://[2001:db8::1]:9090;指定ip需要加上uwsgi://前缀需要知道使用的uwsgi协议而不是普通的http协议。uwsgi_pass_request_body控制是否将原始请求正文传递给 uWSGI 服务器。默认: uwsgi_pass_request_body on;区域:http,server,locationuwsgi_pass_request_headers控制是否将原始请求头传递给 uWSGI 服务器。默认: uwsgi_pass_request_headers on;区域:http,server,locationuwsgi_buffer_size设置用于读取从uwsgi服务器接收到的响应的第一部分的缓冲区大小(读取 uwsgi的请求头大小和 一部分响应数据)。默认:`uwsgi_buffer_size 4k uwsgi_buffers用于设置 Nginx 从 uWSGI 服务器接收响应时使用的缓冲区数量和大小。区域: http,server,location。默认:`uwsgi_buffers 8 4kuwsgi_busy_buffers_size当启用响应缓冲且响应尚未完全读取时,限制用于向客户端发送响应的缓冲区总大小。默认:`uwsgi_busy_buffers_size 8k uwsgi_max_temp_file_size设置当响应无法完全放入内存时,保存到磁盘临时文件的最大大小。区域: http,server,location。默认:uwsgi_max_temp_file_size 1024m;uwsgi_temp_file_write_size设置写入临时文件时每次写入的大小。区域: http,server,location。默认:`uwsgi_temp_file_write_size 8kuwsgi_ignore_headers忽略来自 uWSGI 服务器的指定响应头字段。当 uWSGI 服务器返回响应时,Nginx 会忽略这些指定的头字段,不会对它们进行任何处理。为了避免冲突(自定义的与HTTP默认的冲突)。区域: http,server,location。例如:uwsgi_ignore_headers X-Accel-Redirect X-Accel-Expires;uwsgi_intercept_errors决定是否拦截来自 uWSGI 服务器大于或等于300状态码是否应该传递给客户端响应,并由 Nginx 使用 error_page指令处理。区域:http,server,location。默认:uwsgi_intercept_errors off;uwsgi_limit_rate限制从 uWSGI 服务器读取响应的速度,单位为每秒字节数。区域: http,server,location。默认:uwsgi_limit_rate 0; 0不做限制。限制设置要求,如果nginx开启2个uwsgi服务器的链接,速率应该乘2,只有启用了对来自uwsgi服务器的响应的缓冲,该限制才有效。uwsgi_cache定义用于缓存响应的共享内存区域。 uwsgi_cache_bypass设置在哪些条件下不缓存响应。 uwsgi_cache_valid设置不同状态码的缓存有效期。 uwsgi_connect_timeout设置Nginx与 uWSGI 服务器建立连接的超时时间。默认: uwsgi_connect_timeout 60s;不能大于75s。uwsgi_read_timeout定义Nginx从 uWSGI 服务器读取响应的超时时间。默认: uwsgi_read_timeout 60s;uwsgi_send_timeout设置Nginx将请求发送到 uWSGI 服务器的超时时间。默认: uwsgi_send_timeout 60s;uwsgi_param设置应传递给uwsgi服务器的参数。可能包含,变量,文本或者其他。例如: uwsgi_param UWSGI_SCRIPT MyBlog.wsgi;传递项目的启动文件 或者 uwsgi_param UWSGI_CHDIR /usr/local/python3/myblog; 项目的文件目录# 定义一个 HTTP 服务器 server { # 监听 80 端口 listen 80; # 服务器名称(域名或 IP 地址) server_name example.com; # 静态文件的根目录 root /path/to/your/app/static; # 静态文件的处理 location /static { # 直接提供静态文件 try_files $uri =404; } # 媒体文件的处理(例如 Django 的 media 文件) location /media { alias /path/to/your/app/media; } # 动态请求的处理 location / { # 指定 uWSGI 服务器的地址,这里使用 Unix 套接字 uwsgi_pass unix:/path/to/your/app/myapp.sock; uwsgi_param UWSGI_SCRIPT MyBlog.wsgi; # 指定 uWSGI 使用的 Python WSGI 入口文件 uwsgi_param UWSGI_CHDIR /usr/local/python3/myblog; # 设置 uWSGI 运行时的工作目录,也就是django根目录 # 包含 uWSGI 参数文件 include uwsgi_params; # 设置 uWSGI 缓冲区大小 uwsgi_buffer_size 16k; # 设置 uWSGI 缓冲区数量和大小 uwsgi_buffers 4 16k; # 设置忙缓冲区大小 uwsgi_busy_buffers_size 32k; # 设置连接超时时间 uwsgi_connect_timeout 30s; # 设置读取响应的超时时间 uwsgi_read_timeout 120s; # 设置发送请求的超时时间 uwsgi_send_timeout 120s; # 启用错误拦截 uwsgi_intercept_errors on; # 设置缓存区域 uwsgi_cache my_cache; # 设置缓存有效期 uwsgi_cache_valid 200 302 10m; uwsgi_cache_valid 404 1m; # 设置缓存绕过条件 uwsgi_cache_bypass $http_pragma $http_authorization; # 忽略特定的响应头 uwsgi_ignore_headers X-Accel-Expires; } }参数补充:
# 补充一下参数关系: uwsgi_buffer_size 与 uwsgi_buffers 与 uwsgi_busy_buffers_size uwsgi_buffers: 存储响应数据的大小一共是多少 uwsgi_buffer_size: 响应头大小,初时数据的大小。 uwsgi_busy_buffers_size: 在数据比较大的时候,在响应尚未完全读取时,会限制当前的传输响应的缓冲区大小,设置的值后才会一起发送给前端(比如 32k,nginx已经缓存了32k数据,但 uWSGI 服务器的响应尚未完全接收完成,Nginx 会暂停发送更多数据,直到更多的响应数据被接收并准备好发送。) 计算方式:uwsgi_busy_buffers_size值要在uwsgi_buffers与uwsgi_buffer_size之间。 location / { uwsgi_pass uwsgi://127.0.0.1:8080; include uwsgi_params; # 设置缓冲区数量和大小 uwsgi_buffers 4 16k; # 4 个缓冲区,每个 16KB # 读取请求头的缓冲区大小。 uwsgi_buffer_size 16k; # 16k大小 # 设置忙缓冲区大小 uwsgi_busy_buffers_size 32k; # 总大小限制为 32KB }
7-3-4.TCP/UDP代理(4层负载)
模块:ngx_stream_core_module
文档:https://nginx.org/en/docs/stream/ngx_stream_core_module.html
作用:
- 是 Nginx 的一个核心模块,用于处理 TCP 和 UDP 数据流的代理和负载均衡。
- 它提供了高性能和高可靠性的流处理能力,支持 SSL/TLS 终端、负载均衡等。
特点:
- TCP/UDP 流处理:支持 TCP 和 UDP 数据流的代理。
- 负载均衡:可以对多个后端服务器进行负载均衡。
- SSL/TLS 终端:支持 SSL/TLS 加密通信。
- 访问控制:可以限制特定 IP 地址或网络的访问。
- 健康检查:支持对后端服务器的健康检查。
- 嵌入式变量:提供了多种嵌入式变量,用于获取连接和服务器的信息。
常用指令:
指令 作用 listen设置服务器监听的地址和端口。 proxy_pass指定后端服务器的地址。 resolver配置 DNS 解析器。 resolver_timeout设置 DNS 解析的超时时间。 preread_buffer_size设置预读缓冲区的大小。 preread_timeout设置预读阶段的超时时间。 proxy_protocol_timeout设置 PROXY 协议头的读取超时时间 stream { upstream backend { server backend1.example.com:12345; server backend2.example.com:12345; } # 4层代理不需要定义location server { listen 12345; proxy_pass backend; # 也不需要协议头 } } 注意: ngx_stream_core_module 自 Nginx 1.9.0 版本起可用,但默认情况下不构建。需要在编译时使用 --with-stream 参数启用。
8.Nginx负载均衡
是什么:
- 用于将网络流量分配到多个服务器或服务实例上,以优化资源使用、提高吞吐量、减少响应时间,并增加系统的可靠性。
- 负载均衡器(Load Balancer,简称LB)是实现负载均衡功能的设备或软件,它位于客户端和服务器之间,根据预定义的策略将请求分发到后端服务器。
主要功能:
- 资源优化:负载均衡可以将请求按照策略将请求分发到1个或者多个服务器上,避免其他的某个服务器过载,某个服务器闲置。
- 吞吐量:可以提高吞吐量,将请求分发到多个服务器上,负载均衡器可以提高系统的整体处理能力,从而提高吞吐量。
- 减少响应时间:负载均衡器可以将请求分配到响应最快的服务器上,从而减少客户端的等待时间,提高用户体验。
- 可靠性:负载均衡可以监控服务器的状态,自动跳过故障的服务器,将请求分发到健康的服务器上,提升系统的可用性。
实现方式:
- 硬件附件均衡器:如 F5 BIG-IP、Citrix ADC 等,这些设备专门设计用于高性能的负载均衡。
- 软件负载:如 Nginx、HAProxy 等,这些软件可以运行在普通的服务器上,提供灵活的负载均衡功能。
- 云负载:云厂商提供的负载均衡服务。阿里云,腾讯云,谷歌云等等都有类似产品。
Nginx负载均衡策略:
策略名 说明 轮训 按顺序依次将请求分配到后端服务器,适用于服务器性能相近的场景。 最少连接 将请求分配到当前连接数最少的服务器,适用于服务器性能差异较大的场景。 加权轮训 根据服务器的权重分配请求,权重高的服务器会优先接收更多请求。 ip哈希 根据客户端的 IP 地址进行哈希计算,将请求分配到特定的服务器,确保同一个客户端的请求总是被分配到同一个服务器。 示例:
http { upstream backend { server backend1.example.com:8080; server backend2.example.com:8080; server backend3.example.com:8080; } server { listen 80; location / { proxy_pass http://backend; } } }Nginx的负载均衡模块:
- ngx_http_upstream_module,负载均衡的核心模块。
- 文档:http://nginx.org/en/docs/http/ngx_http_upstream_module.html
- 作用:用于定义一组服务器(后端服务器组),这些服务器组可以通过
proxy_pass、fastcgi_pass、uwsgi_pass、scgi_pass、memcached_pass和grpc_pass等指令进行引用。将数据请求分发到这组服务器中。- ngx_http_upstream_conf_module模块(商业)
- 文档:http://nginx.org/en/docs/http/ngx_http_upstream_conf_module.html
- 作用:开启上游的http接口api,可以通过api进行调用增加或者减少或者修改负载均衡的配置。
- ngx_http_upstream_hc_module模块(商业)
- 文档:http://nginx.org/en/docs/http/ngx_http_upstream_hc_module.html
- 作用:提供定义的服务器组内的服务器的健康检查。
负载均衡的方式:
- 7层负载:
- 由 ngx_http_upstream_module + ngx_http_core_module 模块组层。
- ngx_http_upstream_module 是负载均衡模块。
- ngx_http_core_module HTTP核心模块。
- 4层负载均:
- 由 ngx_http_upstream_module + ngx_stream_core_module模块组层配合才能实现。
- ngx_http_upstream_module 是负载均衡模块。
- ngx_stream_core_module 用于处理TCP与UDP流量的,需要编译安装。
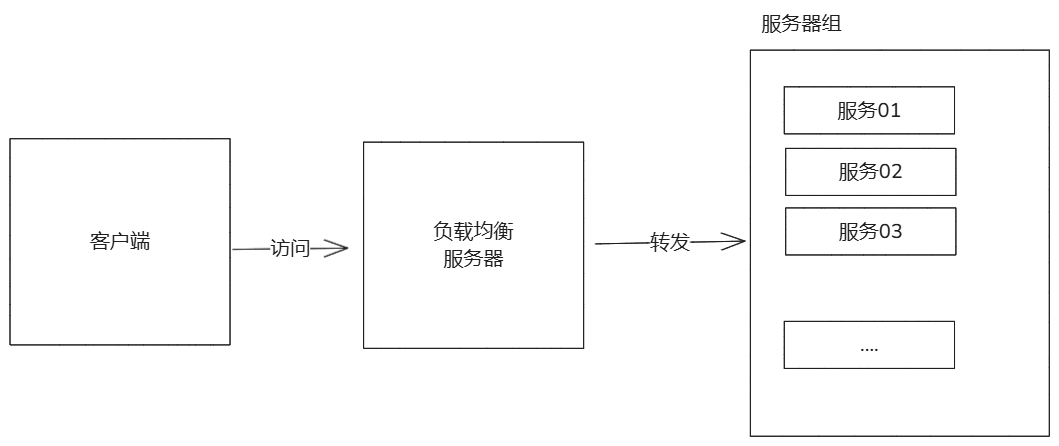

8-1.四层与七层负载的区别作用
4层代理(L4):
- 工作在OSI模型中的第四层(传输层)。
- 主要基于ip端口进行流量转发操作,不解析应用协议。
- 优势:速度快,开销少,适用于高性能,低延迟的场景。
7层代理(L7):
- 工作在OSI模型中的第七层(应用层)。
- 主要基于应用层的协议进行流量转发(HTTP/HTTPS 如url,cookie,http请求头等内容)。
- 优势:可以根据HTTP请求头的内容,更为精准的将流量进行转发,流量控制灵活,因为需要解析协议,处理速度方面会稍慢,开销比较大。
应用场景:
- 4层模型:
- 适用于需要高性能和低延迟的场景,如数据库连接、实时通信、游戏服务器等。
- 适用于处理 TCP/UDP 流量,不依赖于应用层协议。
- 7层模型:
- 适用于需要根据应用层内容进行流量分发的场景,如 Web 应用、API 网关等。
- 适用于处理 HTTP/HTTPS 流量,能够根据请求内容进行更精细的控制。
特点:
4层模型:
- 处理速度快,开销小。
- 通常能够处理更高的并发量。
- 产品:nginx的stream模块可以实现,HAProxy,LVS,云产品。
stream { upstream backend { server 192.168.1.1:3306; server 192.168.1.2:3306; } server { listen 3307; proxy_pass backend; } }7层模型:
- 处理速度相对较慢,开销较大。
- 提供更灵活的流量控制和更丰富的功能。
- 产品:nginx的http模块可以实现,HAProxy,云产品。
http { upstream web_backend { server 192.168.1.1:8080; server 192.168.1.2:8080; } server { listen 80; location /api { proxy_pass http://web_backend; } location /static { proxy_pass http://static_backend; } } }图:
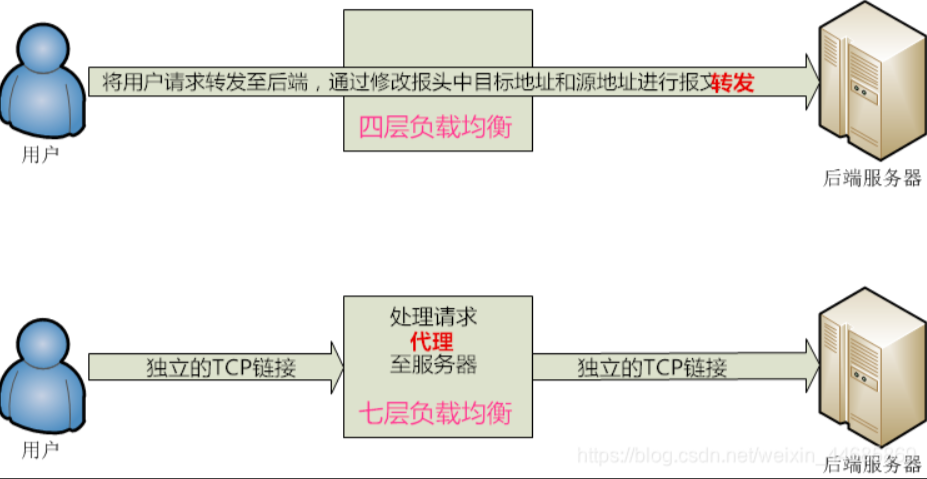
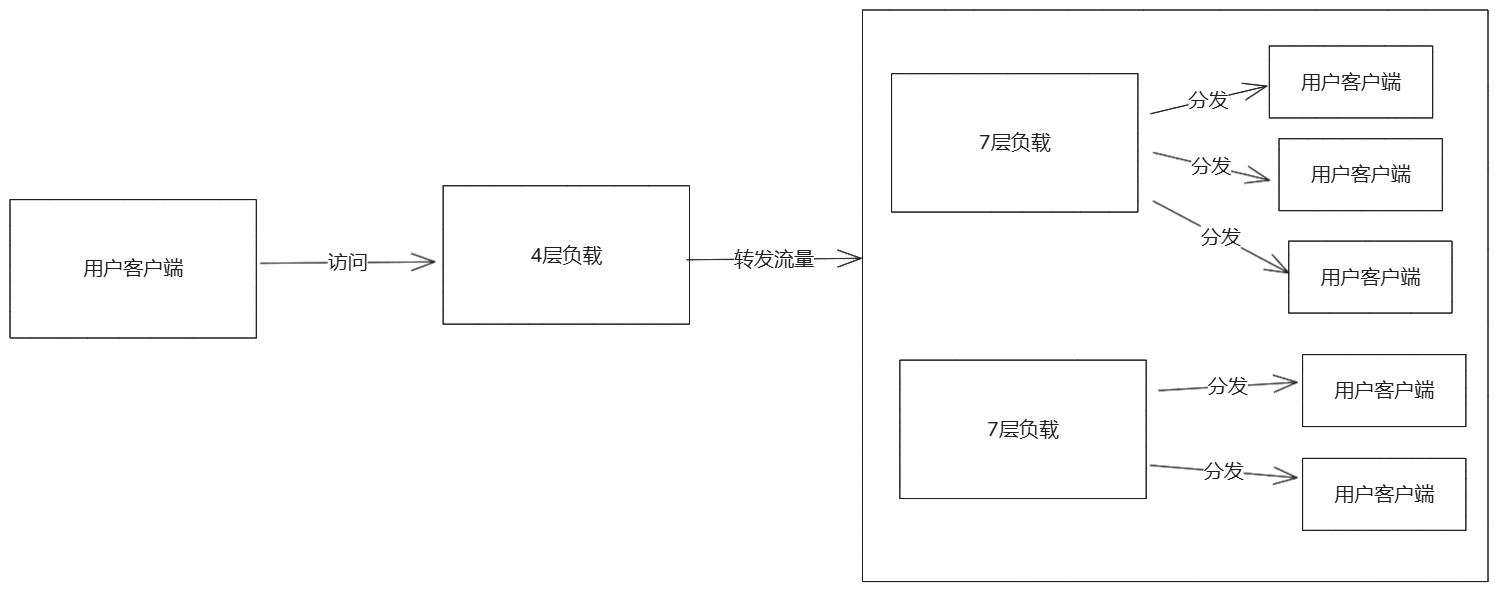
8-2.Nginx负载均衡相关模块
- 模块:ngx_http_upstream_module
- 说明:它是 Nginx 的一个核心模块,用于定义和管理后端服务器组(upstream)。
- 文档:http://nginx.org/en/docs/http/ngx_http_upstream_module.html
| 指令 | 作用 |
|---|---|
upstream |
定义一个服务器组,可以包含多个后端服务器(当配置upstream服务器组,在访问时,会有一个COOKIE的请求参数。)。使用区域:http |
server |
定义服务器的ip端口或者域名或者unix套接字和其他参数。使用区域:upstream |
zone |
定义共享内存区域,保存组的配置和运行时状态(包含:当前服务器连接数,每个服务器失败尝试次数,服务器的状态,使用了DNS动态解析resolver指令也会存储到这个内存区域中。)。使用区域:upstream |
# server 指令其他参数说明:
weight:设置服务器的权重,默认值为 1。
max_conns:设置每个服务器的最大连接数,默认值为 0(无限制)。
max_fails:设置失败尝试次数,默认值为 1。
fail_timeout:设置失败超时时间,默认值为 10 秒。
slow_start:设置慢启动时间,默认值为 0。
backup:标记为备用服务器。
down:标记为永久不可用。
# 配置:
upstream backup {
zone backend 64k;
server backend1.example.com ;
server backend2.example.com ;
}
# zone指令解释:
upstream backup {
zone backup 64k;
server 192.168.85.133:80 weight=3 max_conns=100 max_fails=3 fail_timeout=30s;
server 192.168.85.144:80 weight=1 max_conns=50 max_fails=2 fail_timeout=10s;
}
8-3.负载均衡服务器组Cookie
- 当使用 upstream 服务器组时,在请求头中会出现一个cookie字段。原因通常与会话保持(Session Persistence)有关。

8-4.负载均衡算法
| 算法 | 说明 |
|---|---|
ip_hash |
根据客户端的 IP 地址进行哈希计算,确保同一客户端的请求总是被分配到同一服务器。这可以实现会话保持。 |
least_conn |
将请求分配给当前活跃连接数最少的服务器。这有助于更高效地分配负载,特别是当服务器的处理能力不同时。 |
加权轮询 |
为每个后端服务器分配一个权重,权重高的服务器会接收更多的请求。 |
轮询 |
这是 Nginx 默认的负载均衡算法。它按顺序将请求依次分配给后端服务器。 |
通用哈希 |
基于指定的变量(如客户端 IP 地址、请求 URI 等)进行哈希计算,将请求分配到特定的服务器。 |
8-4-1.ip_hash
# 场景:
适用于需要会话保持的应用,例如用户会话需要保持在同一个服务器上。
例如配置:
upstream backup {
ip_hash; # IP 哈希
server 192.168.85.133:80;
server 192.168.85.144:80;
zone backend 64k;
}
server {
server_name _;
listen 80;
charset utf-8;
location / {
proxy_pass http://backup;
}
}
# 最大的特点就是会话保持:
ip_hash 算法实现了会话保持,即同一客户端的请求会被分配到同一服务器,这在需要会话保持的应用中非常有用(如用户登录状态)。
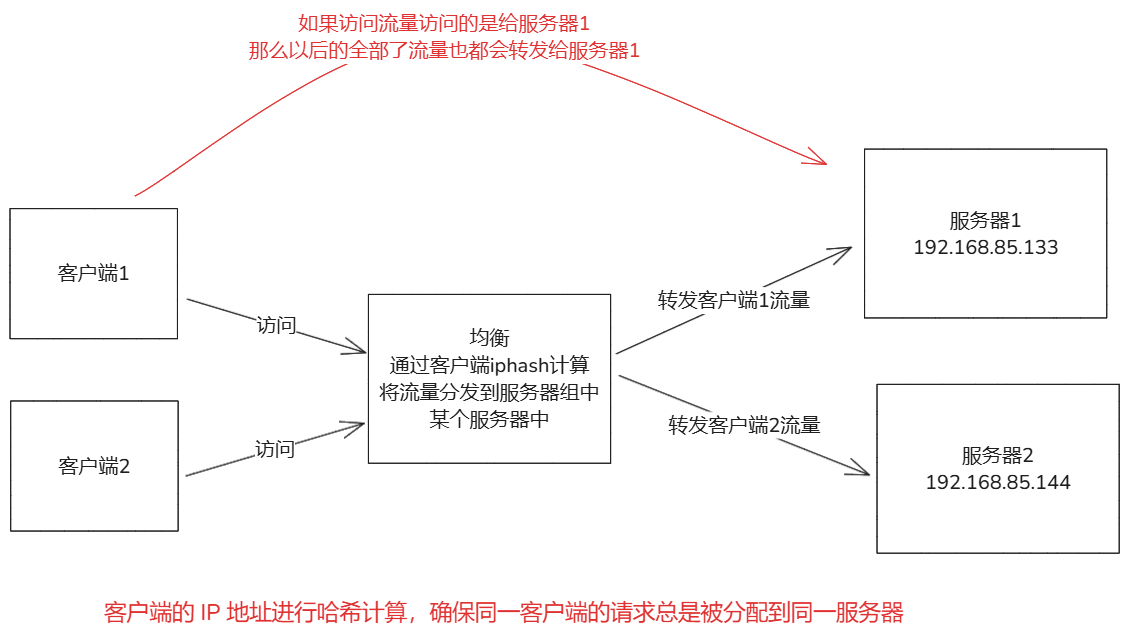
8-4-2.least_conn
# 场景:
适用于后端服务器处理能力不同或请求处理时间不均匀的情况。
该算法根据后端节点的链接数决定分配请求,哪个机器链接数少,就发给谁。
例如配置:
upstream backup {
least_conn; # 最少链接算法
server 192.168.85.133:80;
server 192.168.85.144:80;
zone backend 64k;
}
server {
server_name _;
listen 80;
charset utf-8;
location / {
proxy_pass http://backup;
}
}
# 注意:
如果所有后端服务器的连接数始终接近,最少连接算法可能会表现得类似于轮询算法。这是因为 Nginx 会将请求分配给当前连接数最少的服务器,如果所有服务器的连接数都差不多,那么分配方式就会类似于轮询。
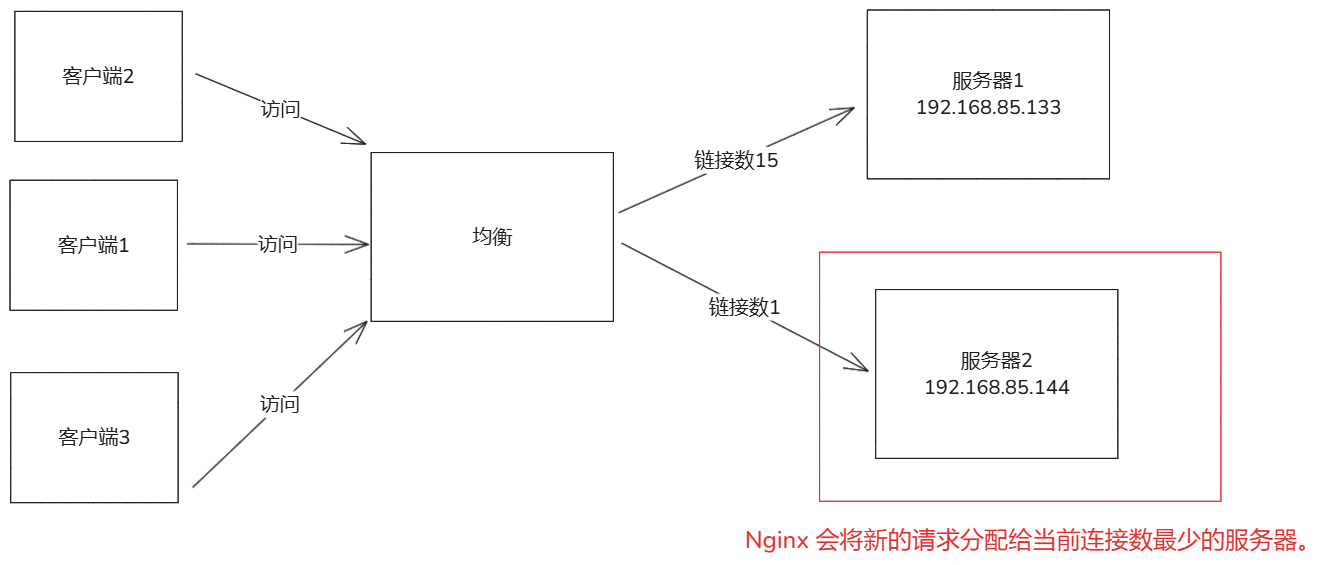
8-4-4.加权轮询
# 场景:
适用于后端服务器性能不同,需要根据服务器的处理能力分配更多或更少的请求
例如配置:
# 默认就是使用轮询
upstream backup {
server 192.168.85.133:80 weight=3;
server 192.168.85.144:80 weight=1;
zone backend 64k;
}
server {
server_name _;
listen 80;
charset utf-8;
location / {
proxy_pass http://backup;
}
}
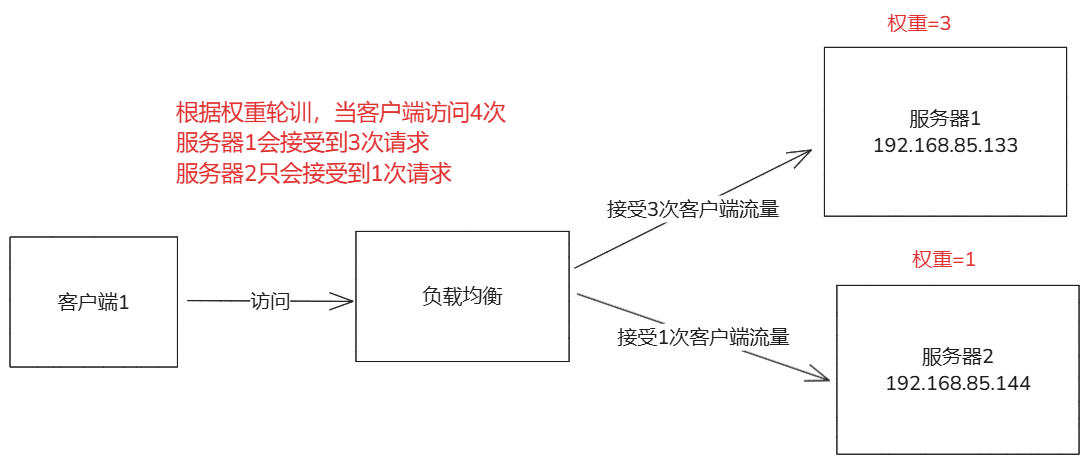
8-4-5.轮询
# 场景:适用于所有后端服务器性能相似且请求处理时间相近的情况。
例如配置:
# 默认就是使用轮询
upstream backup {
server 192.168.85.133:80;
server 192.168.85.144:80;
zone backend 64k;
}
server {
server_name _;
listen 80;
charset utf-8;
location / {
proxy_pass http://backup;
}
}
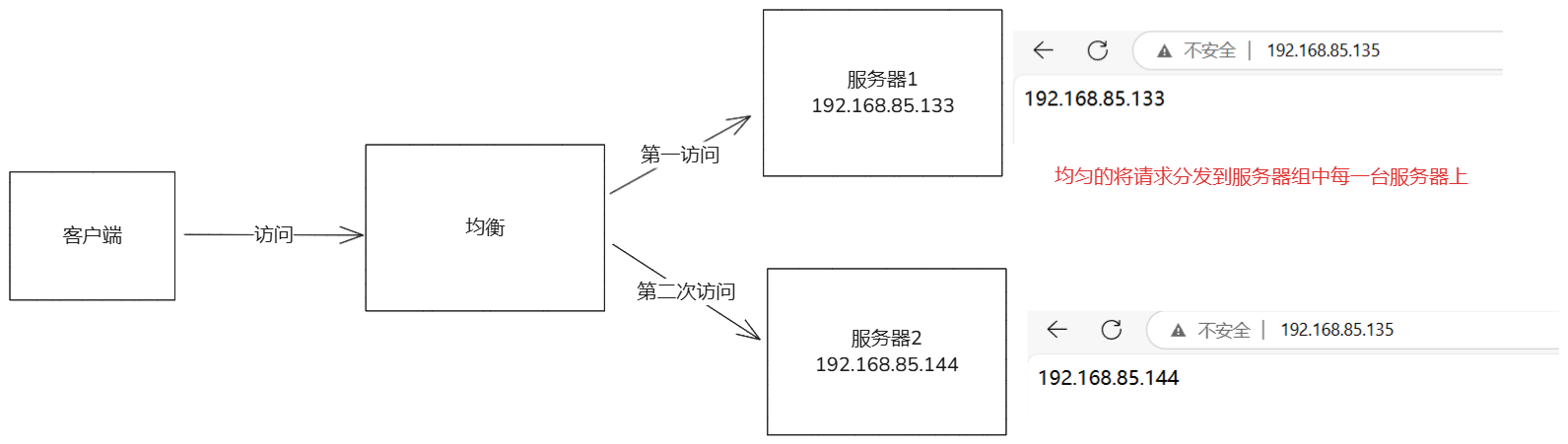
8-4-6.通用哈希
# 场景:
适用于需要根据特定变量进行哈希计算以实现会话保持的情况,与ip哈希一样,只不过计算哈希的值不同。
ip哈希是计算客户端的ip,然后分发流量到某个服务器中。
通用哈希是计算设置的变量(如客户端 IP 地址、请求 URI 等),然后分发到某台服务器中。
例如配置:
upstream backup {
# consistent 作用:关键确保了哈希算法的一致性,即在上游服务器组发生变化(如添加或移除服务器)时,重新分配的请求数量最小化。
hash $remote_addr consistent; # 采用通用哈希,哈希的值是$remote_addr 客户端的ip地址
server 192.168.85.133:80;
server 192.168.85.144:80;
zone backend 64k;
}
server {
server_name _;
listen 80;
charset utf-8;
location / {
proxy_pass http://backup;
}
}
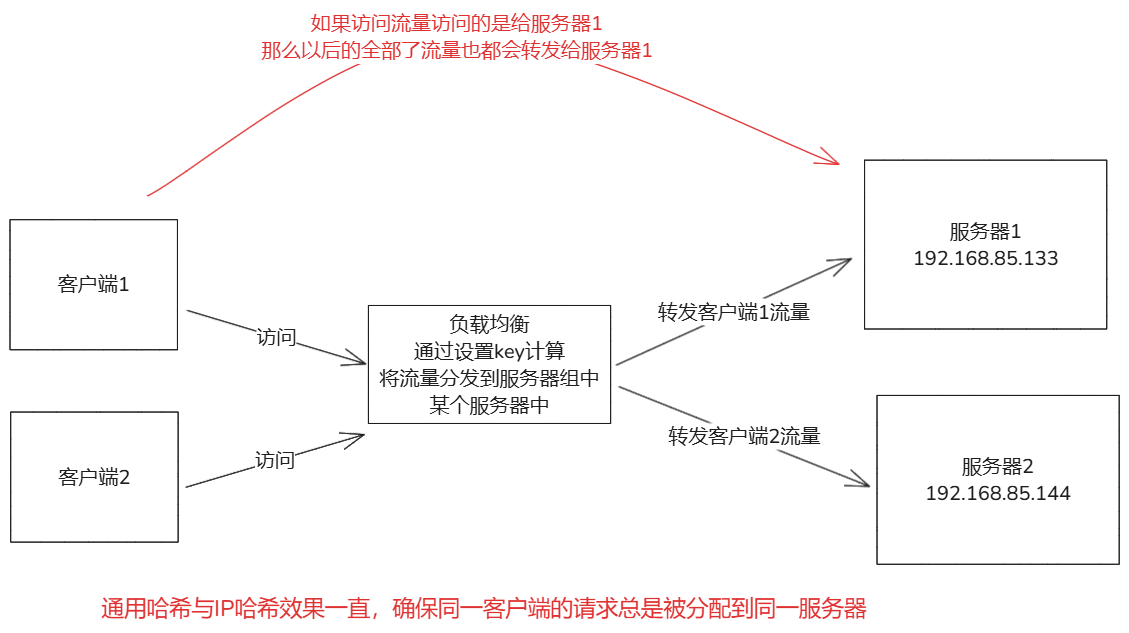
8-5.server 指令其他参数说明
1.down:标记为永久不可用。
upstream backup {
server 192.168.85.133:80;
server 192.168.85.144:80 down; # 当前服务器就不可被使用,分发的流量不会放到状态服务器中。
zone backend 64k;
}
2.backup:标记为备用服务器。
upstream backup {
server 192.168.85.133:80;
server 192.168.85.144:80 backup; # 作为备用服务器,当主服务器不可用时,才会启动
zone backend 64k;
}
2. max_conns:设置每个服务器的最大连接数,默认值为 0(无限制)。
作用:
1.限制并发连接数:这个限制可以帮助防止单个服务器因为过多的并发连接而崩溃。
2.防止过载:通过限制每个服务器的最大连接数,可以防止服务器过载,确保系统的整体稳定性。当达到最链接数时,nginx就会拒绝新的连接,直到有连接关闭。
upstream backup {
server 192.168.85.133:80 max_conns=1500;
server 192.168.85.144:80 max_conns=1000;
zone backend 64k;
}
4. max_fails与fail_timeout
max_fails:设置失败尝试次数,默认值为 1。
fail_timeout:设置失败超时时间,默认值为 10 秒。
# max_fails=2 fail_timeout=10 也就是在10秒内失败连接2次,当前服务器一段时间内(时间也是指 fail_timeout,也就是10秒)被视为不可用。
upstream backup {
server 192.168.85.133:80 max_fails=2 fail_timeout=10;
server 192.168.85.144:80 max_fails=2 fail_timeout=10;
zone backend 64k;
}
5.slow_start:设置慢启动时间,默认值为 0。
slow_start 10s:表示 Nginx 会在连接建立后等待最多 10 秒钟才开始发送数据到后端服务器。
作用:
1.防止时延冲击:在连接建立后,如果立即发送大量数据,可能会对下游服务器造成时延冲击。设置这个值可以减少冲击。
2.提高稳定性:通过控制数据发送的开始时间,可以提高系统的稳定性,特别是在处理大量并发连接时。
3.优化性能:通过调整 slow_start 参数,可以优化系统的性能,确保数据平滑地发送到下游服务器。
upstream backup {
server 192.168.85.133:80;
server 192.168.85.144:80;
slow_start 10s;
}
# 注意:
不能和 hash, ip_hash, and random 负载均衡算法一起使用。
8-6.四层负载实现
- 针对mysql进行4层代理。Mysql连接使用的是TCP连接(它的应用层协议属于2进制些,负责客户端与服务端通信。这个协议建立在传输层之上,对传输层4层代理操作。),使用的协议层是传输层,所以可以使用。
机器:
机器地址 机器作用 主机名 192.168.85.133 Mysql数据节点1 test-1 192.168.85.144 Mysql数据节点2 test-2 192.168.85.135 4层负载均衡,需要编译安装stream模块(ubuntu系统) wkx
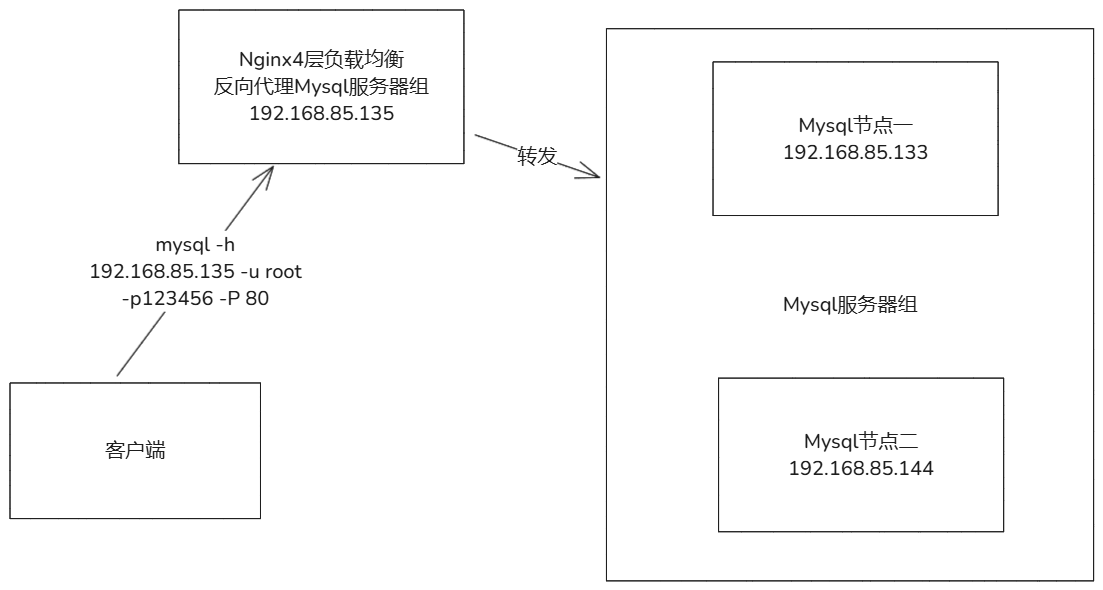
8-6-2.配置mysql服务器
# 192.168.85.133、192.168.85.144 安装
1.安装mariadb
yum install mariadb mariadb-server -y
2.启动并设置密码,并且登录测试
systemctl start mariadb && mysqladmin password 123456 && mysql -uroot -p123456
3.验证当前主机
SHOW VARIABLES LIKE 'hostname';
4.配置授权账户
mysql -uroot -p123456 -e "grant all privileges on *.* to 'test'@'%' identified by '123456';"
5.使用其他机器测试是否可以通过授权账户链接
mysql -utest -p123456 -h192.168.85.133 -e "show databases;"
mysql -utest -p123456 -h192.168.85.144 -e "show databases;"
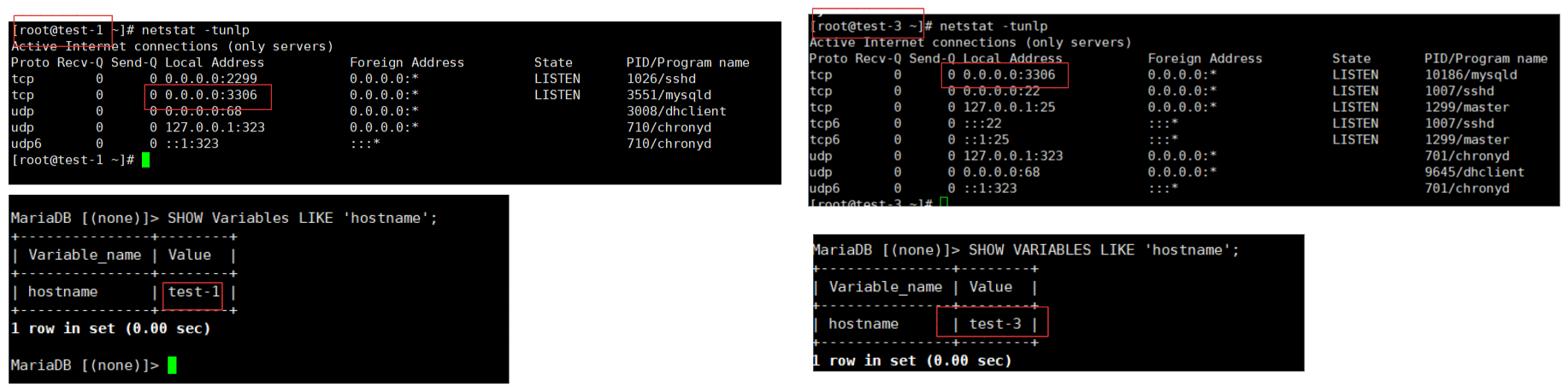
8-6-2.负载均衡服务器配置
# 192.168.85.135
1.4层负载配置:
stream {
upstream mysql {
server 192.168.85.133:3306;
server 192.168.85.144:3306;
}
server { # 定义虚级主机,4层代理不需要定义location
listen 80;
proxy_connect_timeout 1s;
proxy_timeout 3s;
proxy_pass mysql; # 不需要协议头
}
}
2.安装mysql客户端
sudo apt update && sudo apt install mysql-client
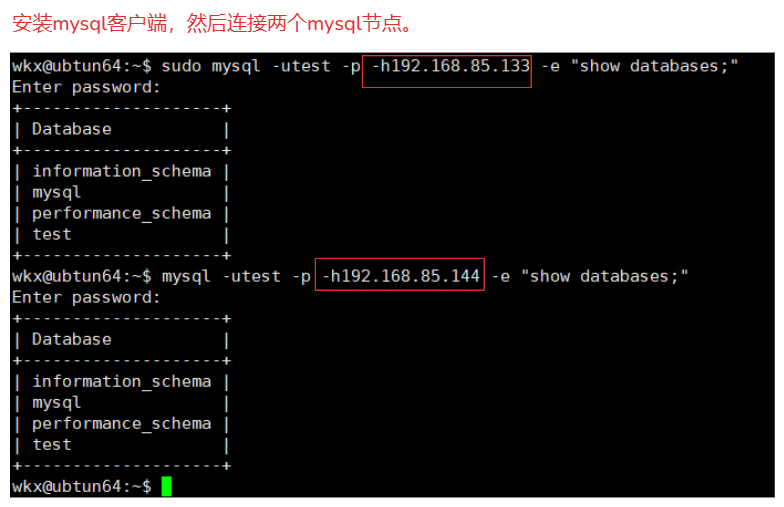
8-6-3.负载均衡编译安装Nginx验证
# 原因:
因为nginx安装不会安装stream模块,需要单独进行编译安装,才能使用4层代理。
1.安装环境
sudo apt update
sudo apt install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev
wget http://nginx.org/download/nginx-1.24.0.tar.gz && tar -zxvf nginx-1.24.0.tar.gz
2.进行编译
cd nginx-1.24.0 && sudo ./configure --prefix=/opt/nginx --with-stream --with-http_ssl_module --with-http_v2_module && sudo make && sudo make install
3.写入配置
stream {
upstream mysql_pool {
server 192.168.85.133:3306 ;
server 192.168.85.144:3306 ;
}
server {
listen 0.0.0.0:3306;
proxy_pass mysql_pool;
}
}
4.启动验证
sudo /opt/nginx/sbin/nginx -t
sudo /opt/nginx/sbin/nginx
5.查看端口
sudo netstat -tunlp
6.连接验证 - 负载均衡本地验证
sudo mysql -utest -p123456 -h127.0.0.1 -P3306 -e "show variables like 'hostname';"
7.连接验证 - 远程验证
ifconfig ens33 | echo "当前主机IP地址:$(awk 'NR==2 { print $2}')"
sudo mysql -utest -p123456 -h192.168.85.135 -P3306 -e "show variables like 'hostname';"
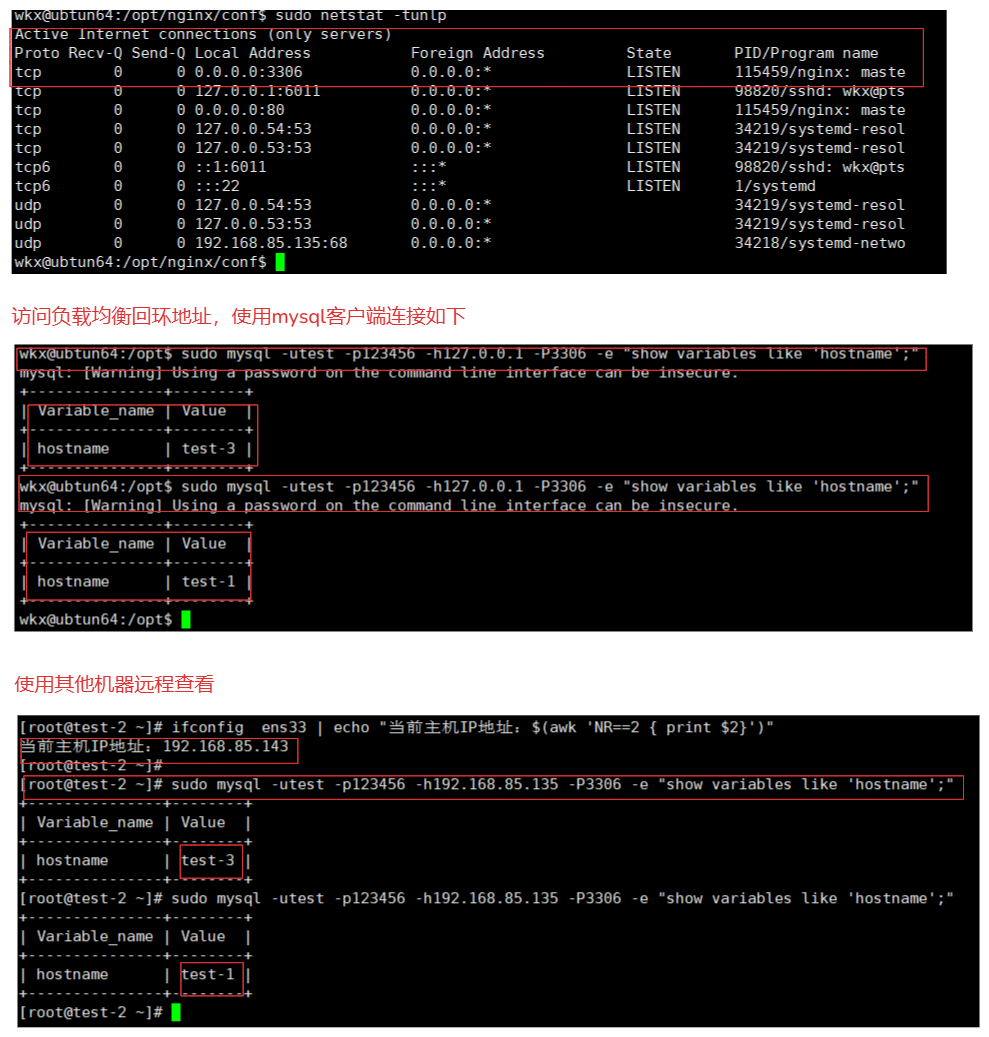
8-7.七层负载实现
- 针对7层代理,应用层。
- 7层代理的最大优势:可以根据应用层协议的请求头信息,进行调整,可以实现很多功能需求。
# 通过 $http_user_agent 变量可以实现不同类型识别。 server { location / { # 根据设备类型执行不同操作 if ($http_user_agent ~* "iphone") { return 200 "苹果\n"; } if ($http_user_agent ~* "android") { return 200 "安卓\n"; } return 200 "桌面\n"; } } }
机器地址 机器作用 主机名 192.168.85.133 Nginx-01后端服务器 test-1 192.168.85.144 Nginx-02后端服务器 test-2 192.168.85.135 7层负载均衡,使用的是HTTP模块(ubuntu系统) wkx
8-7-1.配置负载均衡配置
1.配置信息
upstream backup {
server 192.168.85.133:81 ;
server 192.168.85.144:81 ;
}
server {
listen 80;
server_name _;
location / {
proxy_pass http://backup;
}
}
2.写入到配置文件中即可
8-7-2.后端服务器配置
1.配置信息
server {
listen 81;
server_name _;
location / {
root /www/;
index index.html;
}
}
2.写入对应的ip到index.html中
mkdir -p /www && echo "192.168.85.144" > /www/index.html
mkdir -p /www && echo "192.168.85.133" > /www/index.html
8-7-3.访问测试
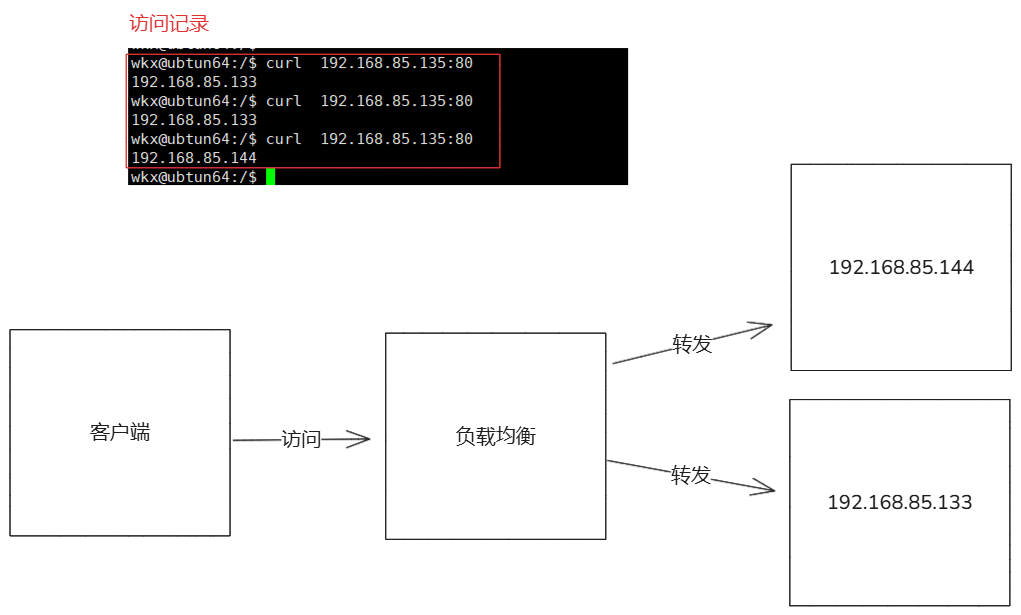
8-8.负载均衡总结
可能出现的问题:
- 负载均衡服务挂了:
- 如果是单机架构负载均衡,会出现网站无法访问的情况,所以需要高可用负载均衡架构模式。
- 服务器组中的节点挂了:
- upstream地址池中的某个节点出现问题,会使用其他正常节点进行转发,当这个坏掉的节点修复了,就会重新接受负载均衡的转发(基于nginx的中设置的负载均衡健康检测机制),检查挂了点节点,通过日志分析,修改坏的节点。
- 应用服务器挂了:
- 例如:php-fpm挂了,报错的就是50x的错误,说明后端挂了,需要查看后端的程序是否运行或者到底为什么挂了,进行修复。
关于7层负载与4层负载说明:
- 无论是4层还是7层,Nginx或者其他的代理软件只是在这层中做了转发操作。并不会对本身的协议进行修改(7层会修改,增加请求头或者修改请求字段等等,只是修改了特定功能【缓存优化...】,但并不改变协议的底层结构。)。
# 四层负载: Nginx 在传输层(第四层)进行代理,主要功能是透明地转发 TCP 数据包,不解析应用层协议。 # 七层负载: Nginx 在应用层(第七层)进行代理,主要功能是解析和处理 HTTP 请求,并将请求转发到后端服务器,同时提供负载均衡、缓存、SSL 终止等高级功能。在什么条件下使用4层与7层:
- 并不是所有的服务都可以通过Nginx的4层代理进行代理操作,Nginx 的四层代理主要用于转发 TCP 和 UDP 流量,它工作在 OSI 模型的传输层(第四层)。
- 非HTTP/HTTPS协议:
- 当后端服务使用的不是 HTTP 或 HTTPS 协议时,例如 MySQL、Redis、Memcached 等,可以使用 Nginx 的四层代理进行转发。这些服务通常在应用层使用自定义协议,而这些协议不能被七层代理(如 HTTP 代理)解析。
- Nginx 的四层代理可以转发任何 TCP 或 UDP 流量,而不管应用层使用的是什么协议。
- HTTP/HTTPS协议:
- 当后端服务使用 HTTP 或 HTTPS 协议时,应使用 Nginx 的七层代理。七层代理可以解析 HTTP 请求和响应,提供内容缓存、负载均衡、SSL 终止等功能。
- 如果需要对 HTTP 请求进行处理,如重写 URL、添加头信息、进行身份验证等,应使用七层代理。
- 取决于后端服务使用的协议类型以及是否需要在应用层进行处理。
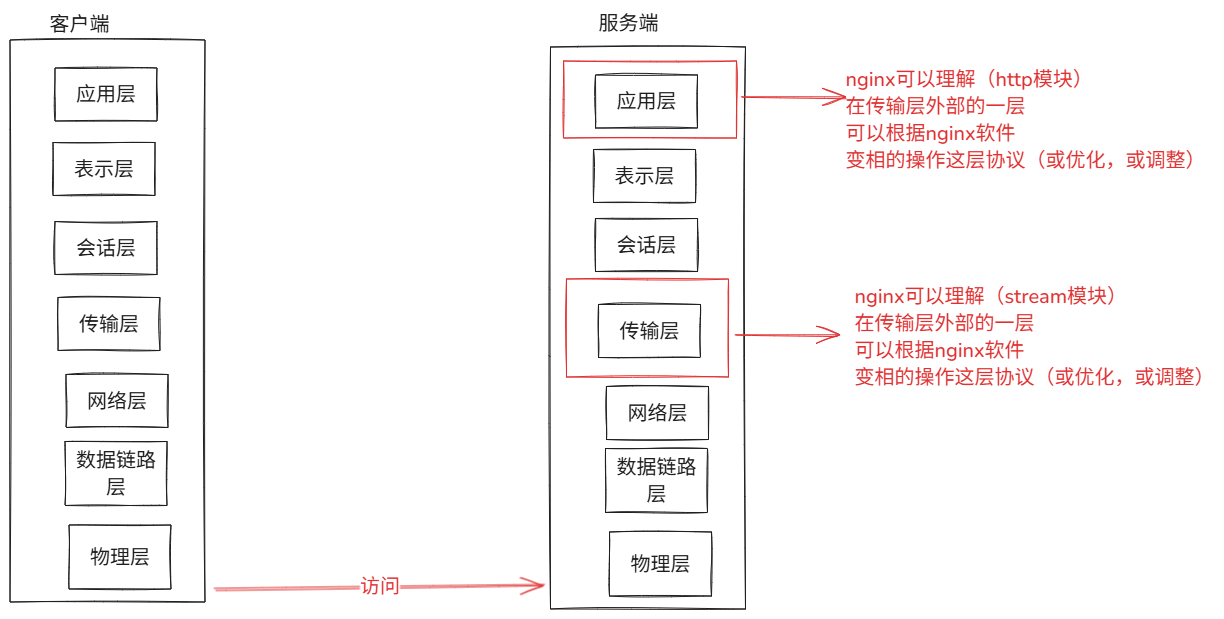
9.Keepalived高可用
官方文档:http://www.keepalived.org/
阿里云厂商文档:https://help.aliyun.com/zh/slb/classic-load-balancer/product-overview/high-availability
是什么:
- 提供高可用性(HA)和负载均衡。它通过 VRRP(虚拟路由冗余协议)实现高可用性,通过健康检查实现故障转移,并支持多种负载均衡算法。
功能:核心在于主从切换功能。
- 提供vrrp实现主备切换。
- 健康检查,监控后端,并且在服务器不可用时,进行切换。
- 支持多种负载均衡算法,如轮询、最少连接等,可以将流量分发到多个后端服务器。
- 当主服务器发生故障时,Keepalived 可以自动将流量切换到备用服务器。
为什么使用:
- 故障转移,也就是主从切换。
- 检查健康状态,确保路由到健康的服务器中。
- nginx可以作为负载均衡反向代理服务器,但是这个负载均衡是单一存在的,如果挂了,那么服务的入口就没有了,所以需要对于负载均衡反向代理服务器进行高可用冗余操作防止单一节点挂掉。
- 不单单可以对nginx进行高可用,对其他的服务器也可以这样使用,Apache HTTPd、Tomcat等。
在架构中的位置:
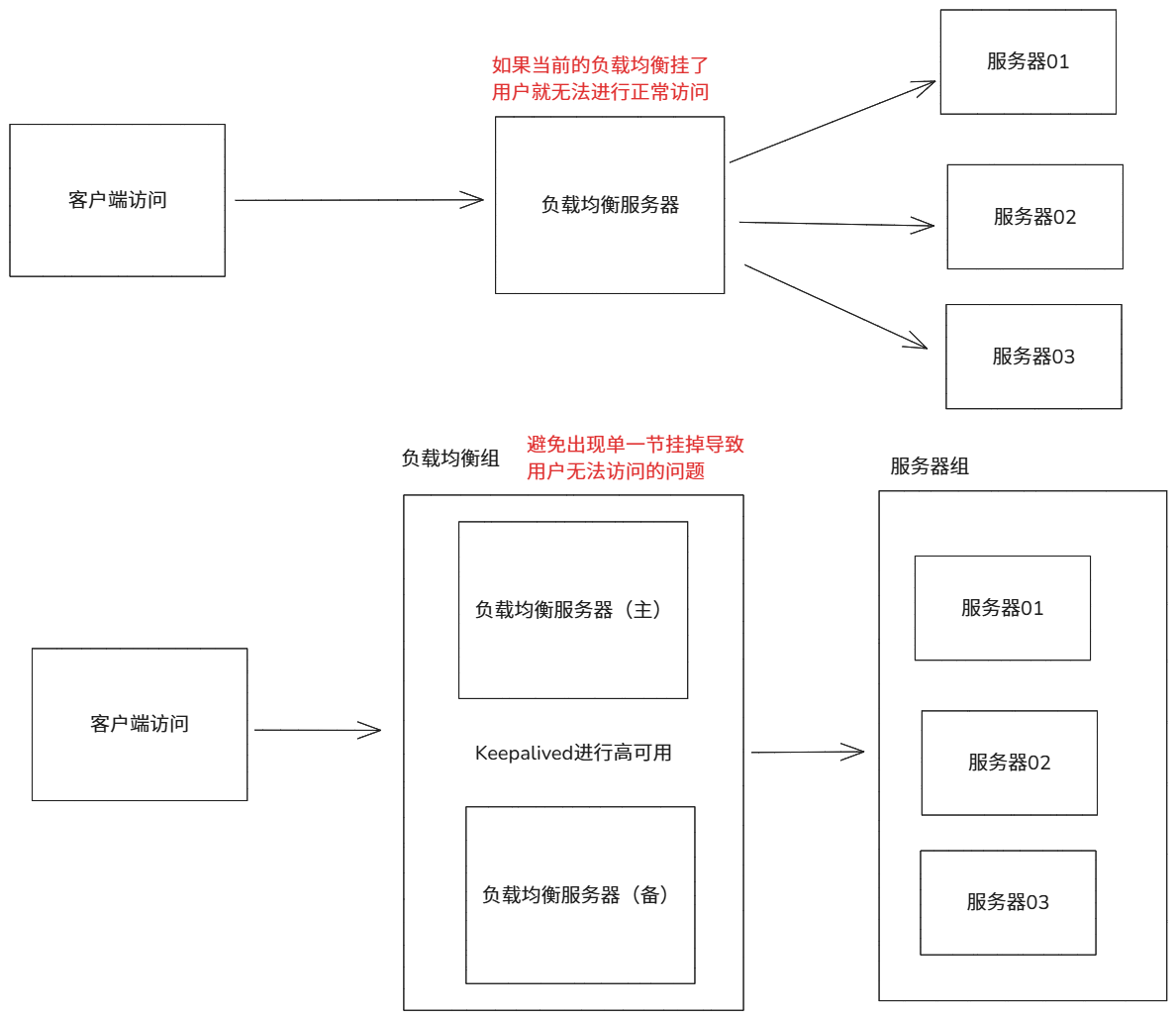
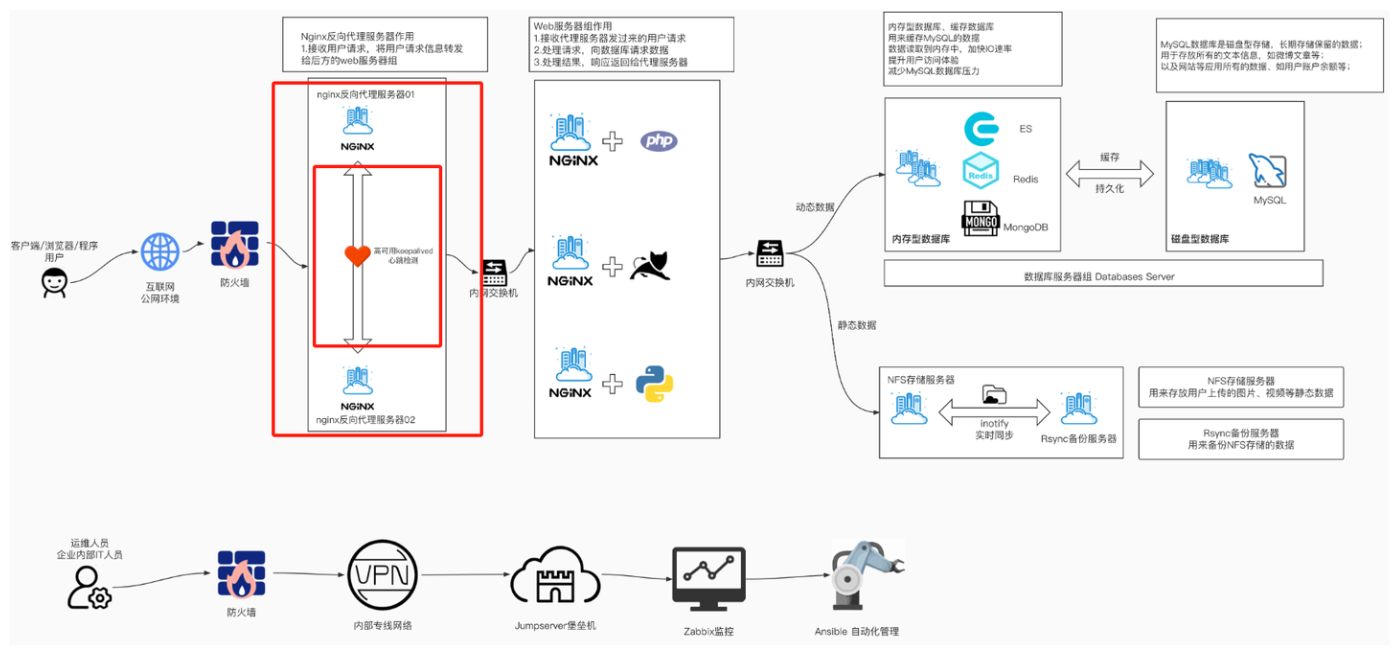
9-1.Keepalived基础知识
9-1-1.单播
- 主机之间的一对一通信模式,网络中的设备根据报文的src和dest自动选择传输路径(则是有路由器决定的你的数据怎么的一个走向,server怎么将响应数据的一个走向),将单播报文传输到目的地。(现在的网站访问就是单播)。
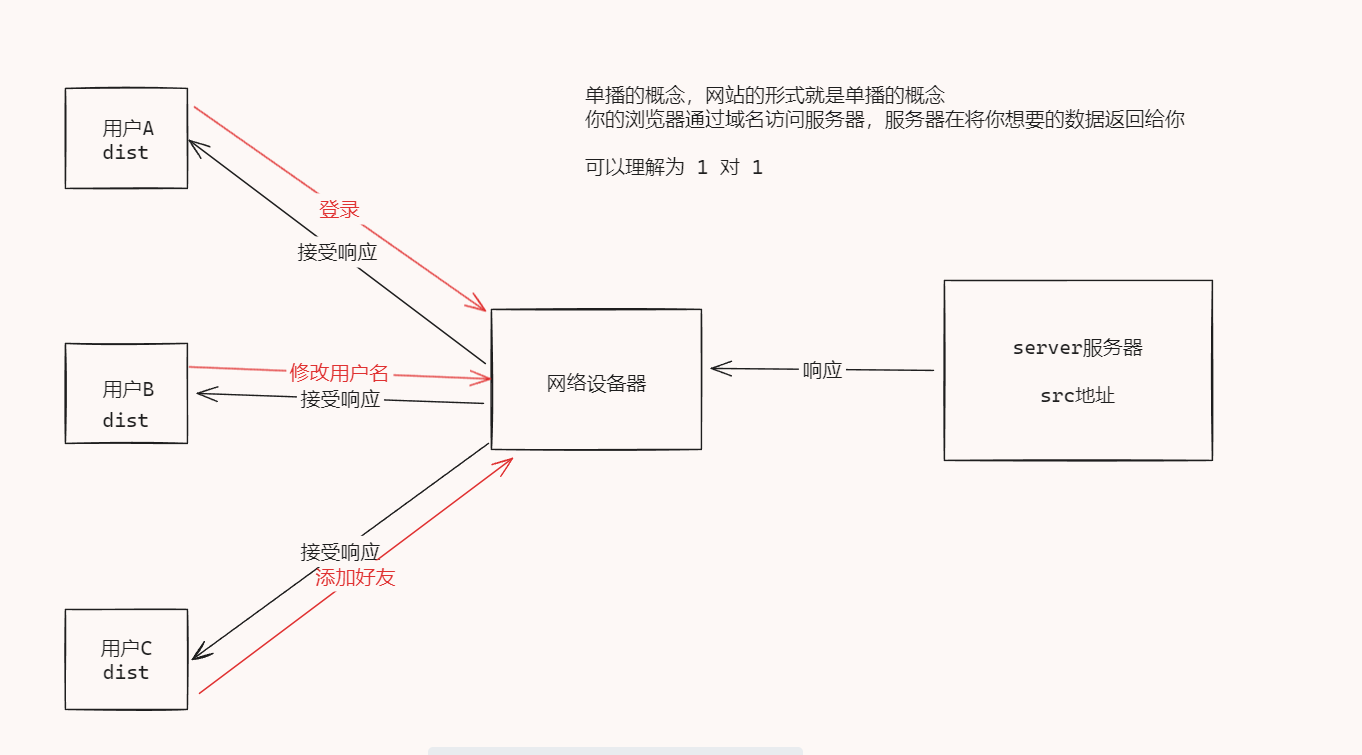
9-1-2.广播
- 主机之间一对所有、的通讯模式,设备将报文发送到网络中所有可能收到的设备。发送一份数据包,所有的设备都会接受这个流量,造成流量冗余。
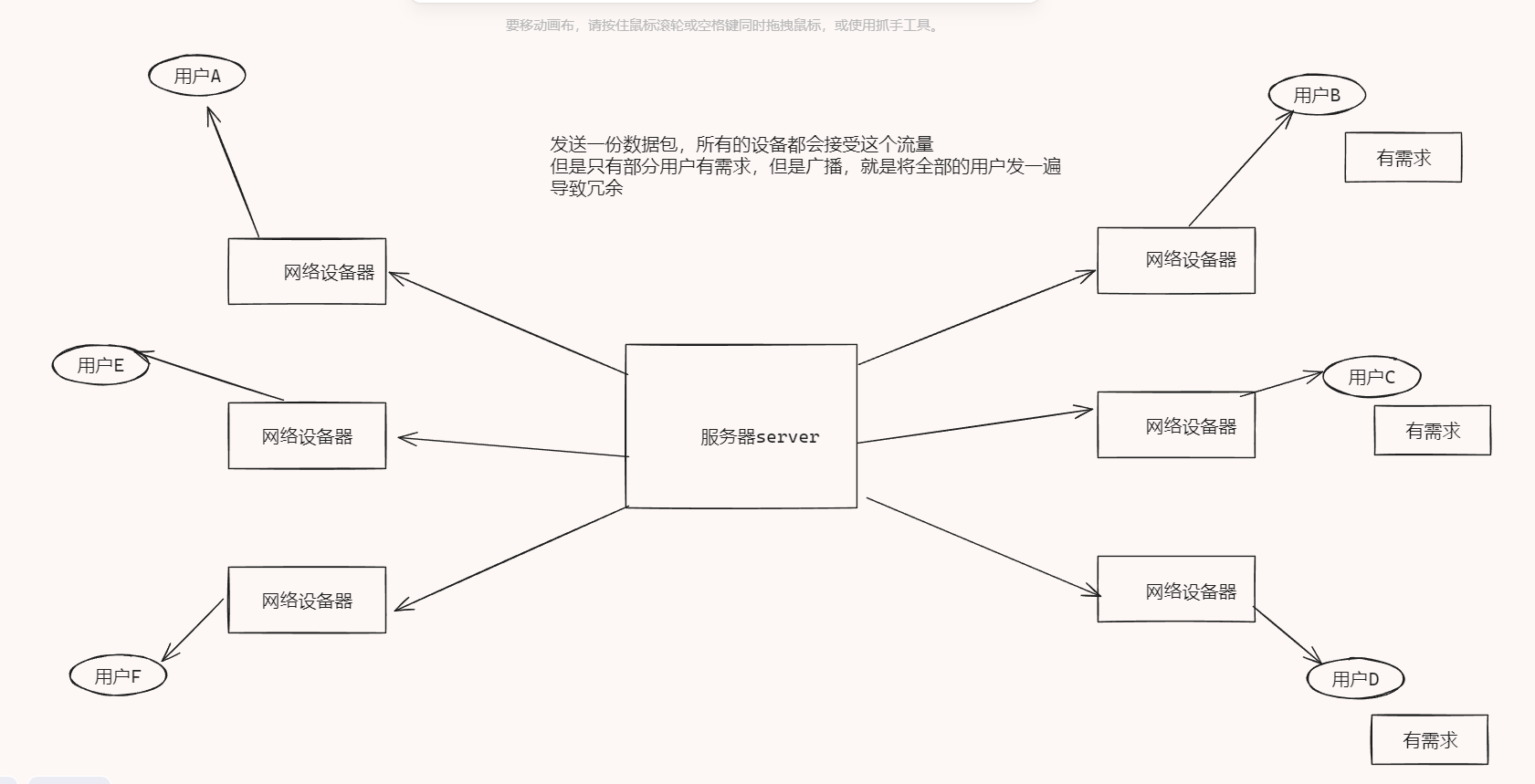
9-1-3.组播
- 主机之间一对多的通讯模式,将数据源发送到一组内的多个接受者;组播将报文发到特定的组播地址,它不属于一个单个的主机,而是一组主机:一个组播地址属于一个群组,在这个组里的接受者都可以收到报文。
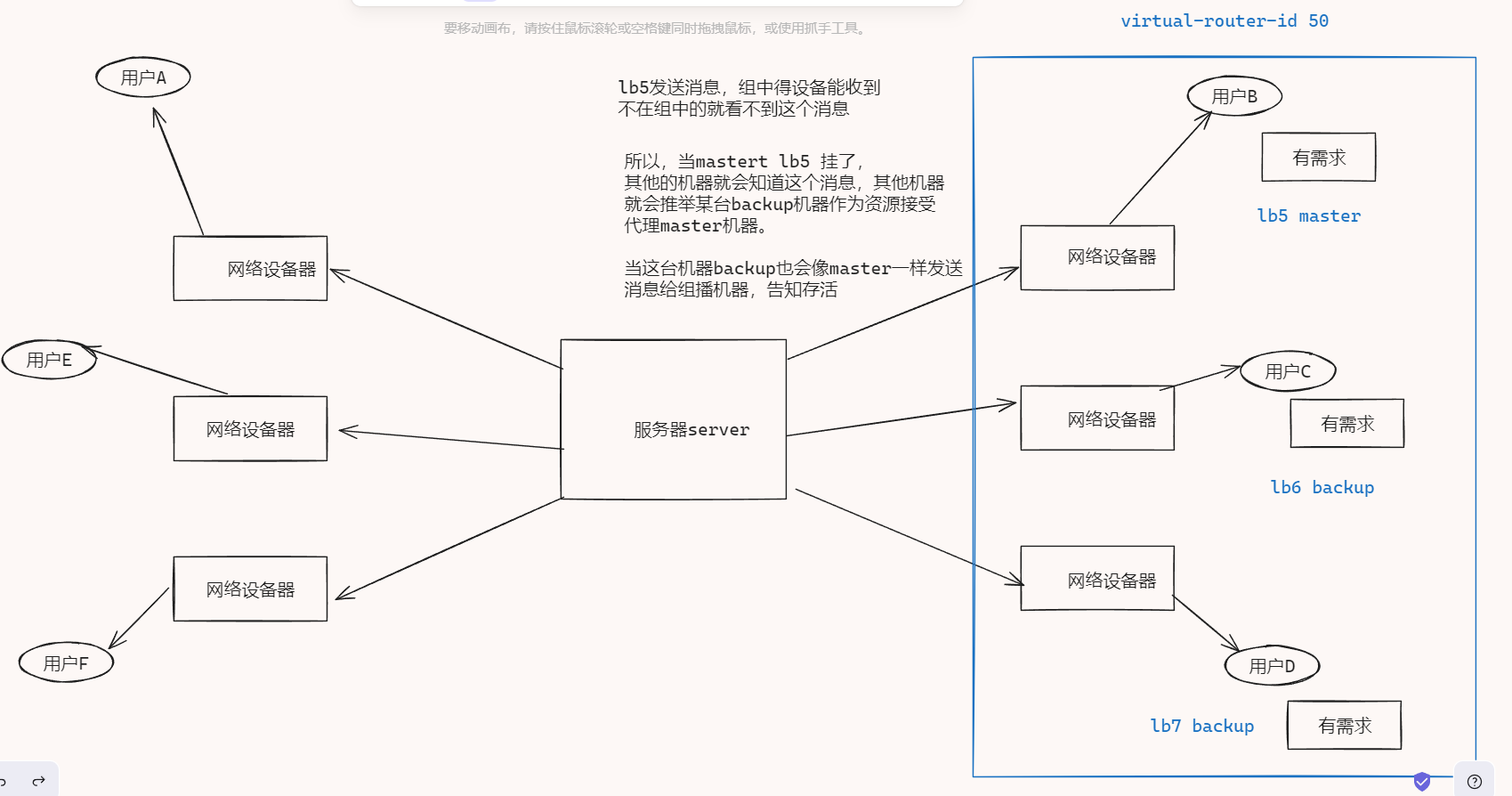
9-1-4.组播/单播/广播总结
单播:
谁发给与我,我就响应给谁,一对一通信,一个发送者一个接受者。
广播:
全部的都会发送一份,无论需要不需要,一对多通信,一个发送者多个接受者。
组播:
只有在一个组中的才会收到,就是群概念,一对多通信,但仅限于组成员。。
9-1-4.VRRP协议
是什么:
- VRRP(Virtual Router Redundancy Protocol,虚拟路由冗余协议)是一种网络协议,用于实现路由器的高可用性。它允许一组路由器(通常称为一个“虚拟路由器”或“VRRP组”)在没有单一物理路由器的情况下,共同提供一个虚拟的、单一的默认网关(通常是IP地址)给局域网(LAN)中的主机。
特点:
- 虚拟路由:vrrp协议允许一组路由共享一个虚拟ip地址,这个地址被配置为局域网内主机的默认网关。这个虚拟IP地址不会实际分配给任何一台物理路由器,而是在VRRP组内的所有路由器之间共享。
- 主备模式故障转移:在组中,会有一台路由器被选为主路由器,负责处理ip地址所有的流量。其他的路由器作为主路由的备用路由,如果主故障,切换为备用。
- 优先级:使用优先来选取那个路由器升为主路由(优先级高),如果优先级相同,会根居ip地址来自动选择。
- 发送报文:会通过
组播方式像组内的路由器发送报文来为组的状态,报文中包含了路由器的优先级,虚拟ip,组内同步状态和选举主路由器。VRRP协议中定义了三种状态机:
状态 说明 Initialize 该状态为VRRP不可用状态,在此状态时设备不会对VRRP通告报文做任何处理。通常设备启动时或设备检测到故障时会进入Initialize状态。 Master 当VRRP设备处于Master状态时,它将会承担虚拟路由设备的所有转发工作,并定期向整个虚拟内发送VRRP通告报文。 Backup 当VRRP设备处于Backup状态时,它不会承担虚拟路由设备的转发工作,并定期接受Master设备的VRRP通告报文,判断Master的工作状态是否正常。 为什么选用组播方式:
- 效率:只需要发送组内的设备,组内的设接受到广告报文,其他的设备不需要。
- 较少流量:只有组内设备会收到,所以会减少网络广播流量。
- 避免不必要的处理:非 VRRP 路由器不会接收 VRRP 广告报文,因此不会对这些报文进行不必要的处理,这可以提高网络的整体效率。
VRRP 使用的组播地址:
- 224.0.0.18(对于 IPv4)
- FF02::12(对于 IPv6)
- Keepalived可以对地址进行修改

9-2.Keepalived工作原理
# 核心
keepalived是采用vrrp虚拟路由冗余协议。
keepalived工作原理是在vrrp虚拟路由冗余协议的基础上实现的。
1.vrrp虚拟路由冗余协议
1.它是为了解决单点故障的。
2.通过竞选协议将路由交给某一台vrrp组路由。
3.当vrrp正常工作时,组内的master(主)自动发送数据包,backup(备)接受数据包,目的告知backup(备)我还存活。当backup(备)无法接受到master(主)数据包,就会自动接管master(主)的资源。backup节点可以有多个,通过优先级竞选,但是keepalived服务器一般都是成对出现。
4.VRRP默认对数据包进行了加密,keepalived官网默认还是推荐使用明文来配置认证。
2.keepalived工作原理
1.keepalived就是基于VRRP协议实现的高可用,master的优先级必须高于backup,因此启动时master优先获得机器的IP资源,backup处于等待状态;若master挂掉后,backup顶替上来,继续提供服务。
2.在keepalived工作时,master角色的机器会一直发送VRRP广播数据包,这个数据包为了告知其其他的backup还存活,此时backup不会抢夺资源。当backup无法再接收到这个数据包,就会进行竞选出新的master来接管旧master资源。
9-3.Keepalived脑裂
# 简单理解:
就是master机器其实活着,但是backup无法接收到master的数据包,导致backup机器以为master挂了,竞选出来的新的master机器并且获得了vip(vrrp的虚拟路由地址ip),导致了出现了两个虚拟ip地址。导致流量无法正常走。
# 原因(可能出现): 要实现心跳检测,需要让至少两台服务器实现互相通信,数据包收发,主要通过如下方式实现
1.两台或者多台机器之间无法正常通信(线路,配置错误)。
2.网卡驱动损坏,master、backup IP地址冲突。
3.防火墙配置错误,导致心跳消息收不到
4.配置文写错了,两台机器的虚拟路由ID不一致。
# 解决方式:
1.使用双心跳线路,防止单线路损坏,只要确保master的心跳数据包能发给backup。
2.通过脚本程序检测脑裂情况(keepalived支持脚本的检测)
判断是否两边都有VIP,如果心跳重复,强制关闭一个心跳节点(直接发送关机命令,强制断掉主节点的电源)
4.做好脑裂监控,如果发现脑裂,人为第一时间干预处理。
5.如果开启了防火墙,注意要允许心跳IP的访问。
9-4.Keepalived故障解决脚本
9-4-1.master机器故障解决脚本
# master机器出现nginx故障。导致无法访问。
这个脚本运行在mstart机器,最先开始获取vrrp虚拟路由ip的机器。
目的:在Keepalived机器发现master节点出现问题是,先进行抢救一下,无法抢救,无法关闭Keepalived,防止故障情况出现。
1.脚本
作用:就是检查nginx的进程数量,如果等于0那么重启nginx,如果重启失败,关闭keepalived,释放vip给backup
vim /etc/keepalived/check_web.sh
NGINX_STATUS=$(ps -ef|grep ngin[x]|wc -l)
# 如果nginx挂了
if [ ${NGINX_STATUS} == 0 ]
then
systemctl restart nginx > /dev/null 2>&1
# 如果重启失败
if [ $? == 1 ]
then
# keepalived没必要活着了
systemctl stop keepalived
fi
fi
# chmod +x /etc/keepalived/check_web.sh
2.keepalived的脚本
global_defs {
router_id lb-5
}
vrrp_script check_web {
script "/etc/keepalived/check_web.sh"
interval 5
}
vrrp_instance VIP_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
track_script {
check_web
}
}
9-4-2.backup机器故障解决脚本
# 这个脚本运行在backup机器 backup 机器出现nginx故障。导致无法访问。
作为备用节点,主节点故障随时接管。
目的:backup机器因为某种原因,无法接受到master的数据包,导致backup抢夺vip,导致master与backup都有vip情况。
1.backup机器故障,抢夺master的vip[执行在backup机器上]
# 当前脚本的意思就是,如果master机器有vip,并且backup机器上也有vip,就直接停止backup机器的keepalived服务
vim /etc/keepalived/check_vip.sh
#!/bin/bash
MASTER_VIP=$(ssh 10.0.0.5 ip a|grep 10.0.0.3|wc -l) # 查看master机器的vip
MY_VIP=$(ip a|grep 10.0.0.3|wc -l) # 查看当前所在的backup机器的vip
# 如果远程有VIP并且自己本地也存在了VIP,就干掉自己
if [ ${MASTER_VIP} == 1 -a ${MY_VIP} == 1 ]
then
systemctl stop keepalived
fi
chmod +x /etc/keepalived/check_vip.sh # 设置执行权限
2.修改keepalived的配置文件(使用keepalived内部的配置功能,调用这个脚本,或者写一个定时器也可以)
# 条件:master机器与backup机器之间需要免密登录,同时需要给脚本设置执行权限
vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb-6
}
# 1.定义脚本 vrrp_script(关键字) check_vip(自定义)
vrrp_script check_vip {
script "/etc/keepalived/check_vip.sh" # 脚本的路径
interval 5 # 2.脚本执行的时间间隔
}
vrrp_instance VIP_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
# 3. track_script调动设置脚本的名字
track_script {
check_vip # 脚本的名字
}
}
3.免密登录(因为脚本主要监控的时master机器的vip,需要在backup机器上链接master机器进行免密)
1.生成秘钥
ssh-keygen
2.发送公钥给master机器免密
ssh-copy-id root@10.0.0.5
9-5.keepalived安装配置
9-5-1.命令安装
1.安装
yum install keepalived -y
sudo apt install keepalived -y
2.配置文件所在位置
/etc/keepalived/keepalived.conf
9-5-2.编译安装
1.下载解压
sudo wget -P /opt/ https://www.keepalived.org/software/keepalived-2.3.3.tar.gz
sudo tar xvf keepalived-2.0.8.tar.gz && cd keepalived-2.0.8
2.安装环境依赖# 注意ubuntu 安装的最新版本,就版本需要安装指定的依赖环境
sudo apt install -y openssl-* build-essential libssl-dev libpcap-dev libnl-genl-3-dev libnfnetlink-dev
sudo yum install -y openssl-devel libpcap-devel libnl3-devel libnfnetlink-devel
3.编译安装
sudo ./configure --prefix=/usr/local/keepalived
sudo make && sudo make install # 编译与安装可执行文件
4.配置文件
编译安装路径/etc/keepalived/keepalived.conf # 没有需要创建即可
5.启动
sudo sbin/keepalived -D -f /opt/keepalived/etc/keepalived/keepalived.conf
journalctl -f | grep keepalived # 查看关于keepalived的日志
9-5-3.配置说明
1.配置
global_defs {
router_id <路由器ID【随便都可以】,不能重复必须是唯一值>
}
# 导入脚本
vrrp_script check_nginx{
# 脚本执行路径
seript "/usr/local/keepalived/etc/keepalived/nginx_pid.sh"
# 探针 每两秒运行一次
interrval 2
# 失败次数 1
fall 1
}
vrrp_instance <组播的名字,同一组必须相同> {
state MASTER # 当前组中的角色属性
interface ens33 # 绑定网卡,将虚拟ip的流量转发给当前网卡
mcast_src_ip 192.168.116.130 # 修改默认的组播地址 224.0.0.18,修改为192.168.116.130,可以不设置。
virtual_router_id <设置数字,虚拟路由的id值,用一组必须相同>
priority 100 # 设置的优先级
advert_int 1 # 设置通告时间的间隔,主路由器将每 2 秒向备份路由器发送一次 VRRP 通告。
authentication { # 组播的密码,这可以提高网络的安全性,防止未经授权的设备参与 VRRP 通信
auth_type PASS # 指定认证类型为密码认证。
auth_pass 1111 # 指定密码。密码长度限制为 8 个字符。
}
track_scrip{
check_nginx # 调用脚本
}
virtual_ipaddress {
192.168.200.17/24 # 设置虚vip地址
}
}
2.常规脚本
# !/bin/bash
naginx_kp_check(){
nginxpid=`ps -C nginx --no-header |wc -l` # 检查nginx
if [ $nginxpid -eq 0];then
/usr/local/nginx/sbin/nginx
sleep 1
nginxpid=`ps -C nginx --no-header |wc -l`
if if [ $nginxpid -eq 0];then
systemctl stop keepalived
fi
fi
}
naginx_kp_check
9-6.keepalived部署
使用机器:
机器 作用 192.168.85.135 主节点 192.168.85.144 从节点 使用配置:
global_defs { router_id <路由器ID【随便都可以】,不能重复必须是唯一值> } vrrp_instance <VRRP路由器组组名,同一组必须相同> { state <MASTER或者BACKUP> interface <网卡名称,接受的流量会给到这网卡> virtual_router_id <设置数字,虚拟路由的id值,用一组必须相同> priority: <优先级,master > backup,相同的情况下也会先给master> advert_int <设置数字,发送组播的间隔时间> authentication { # 认证形式(在同一组播中需要进行认证,内网可以使用明文形式) auth_type PASS # 密码 auth_pass <设置密码,相同组必须相同,否则无法通信> } virtual_ipaddress { <配置机器所在的网段地址> } } # 参数解释: router_id : 当前机器的id/随机不能重复 state:当前机器的角色 interface:绑定的网卡,vip与那个张网卡进行通信 virtual_router_id:当前路由组的id【只要在这个组中,id都是一样的】 priority:优先级 master 必须大于 backup authentication:认证形式,在同一组中得相互通信的认证密码 virtual_ipaddress :指定的虚级ip
9-6-1.两个节点nginx配置
1.nginx配置
server {
listen 80;
server_name _;
location / {
root /www/80/;
index index.html;
}
}
2.配置index文件内容,内容不同
echo '192.168.85.135' > /www/80/index.html
echo '192.168.85.144' > /www/80/index.html
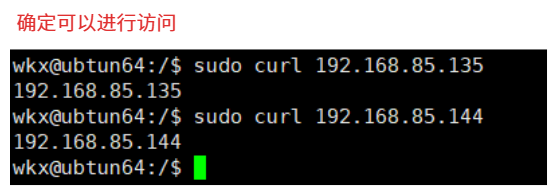
9-6-2.配置keepalived-主节点
1.机器都需要安装keepalived
yum install keepalived -y
2.编译配置文件
global_defs {
router_id 192.168.85.135
}
vrrp_instance VIP_1 {
state MASTER
interface ens33
virtual_router_id 50
priority:150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.85.200/24
}
}
3.启动服务
sudo systemctl start keepalived
9-6-2.配置keepalived-从节点
1.机器都需要安装keepalived
yum install keepalived -y
2.配置文件
global_defs {
router_id 192.168.85.144
}
vrrp_instance VIP_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority:100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.85.200/24
}
}
3.启动服务
sudo systemctl start keepalived
9-6-4.测试

9-6-5.总结
# 配置文件的参数
1.router_id 唯一不同 # 这个值随意设置,不能重复
2.state 角色不同 # BACKUP 与 MASTER
3.priority 权重设置不同 # 根据主与备进行设置
# 公网中得怎么部署keepalived
操作不变,还是执行一个局域网的ip地址(虚拟ip),而需要网络工程师,进行配置公网与内网的nat转换,我们只需要做好内网的配置信息,将vip给网络工程师,他来做公网与局域网的nat转换。

9-7.共有云的高可用
阿里云文档说明:
https://help.aliyun.com/zh/slb/
https://help.aliyun.com/zh/slb/classic-load-balancer/product-overview/high-availability
# 云产品的部署更为方便,选择方式更多。
10.HTTPS配置
模块:ngx_http_ssl_module
文档:https://nginx.org/en/docs/http/ngx_http_ssl_module.html
介绍:是Nginx的核心模块,用于为HTTP服务器进行SSL/TLS加密。通过这个模块,可以进行HTTPS请求处理,确保服务器的通信是加密的。模块不是默认构建的,它应该使用
--with-http_ssl_module配置参数背景说明(为什么使用HTTPS):
- 网络的实现不同主机之间的同, 在最初利用TCP/IP协议簇的相关协议概念,已经满足了两台主机之间相同通信的目的。
- 真正实现两台主机之间的稳定可靠通讯,其实是一件非常困难的事情了,如果还要再通讯的基础上保证数据传输的安全性。
- 对于默认的两台主机而言,早期传输数据信息并没有通过加密方式传输数据,设备两端传输的数据本身实际是明文的,只要能截取到传输的数据包,就可以直接看到传输的数据信息,所以根本没有安全性可言。
- 早期利用明文传输协议:
FTP、HTTP、SMTP、Telnet- 后期使用加密协议:
https ssh涉及到的安全问题:
- 如果两个机器之间传输数据,采用明文的方式进行传递,那么安全性非常低,很容易被黑客抓包,修改你的数据。
- 在不使用加密的方式下,如果在访问登录页面或者交易页面进行支付金额是,被黑客截获的请求并且进行加工修改,那么就会出现很严重的问题(数据篡改,数据窃听,冒充身份)。
Nginx模块作用:
- 加密通信:通过 SSL/TLS 加密,客户端与服务器之间的数据传输被加密,防止数据在传输过程中被窃听或篡改,可以端可以通过服务器SSL证书验证服务器的身份,确保连接是正确的服务器,而不是中间攻击者。
- 提供安全WEB服务:机密HTTP流量,支持多种加密算法,可以选择不同的加密方式。
- 可以配置 OCSP Stapling(在线证书状态协议),提高证书验证的效率和安全性。配置灵活:可以通过配置文件指定 SSL 证书和私钥的路径。可以根据需要配置支持的加密套件,以满足不同的安全需求。
加密提供安全性:
- 数据在传输过程中加密,防止窃听或者篡改。
- 客户端通过验证服务器的证书来确认服务器的身份,防止中间人攻击。
- 使用消息认证算法(如HMAC)确保数据在传输过程中未被篡改。
加密方式:
数据加密方式 描述 主要解决的问题 常用算法 对称加密 指数据加密和解密使用相同的密钥 数据的机密性 DES,AES 非对称加密 也叫公钥加密,指数据加密和解密使用不同的密钥--密钥对儿 身份验证 DSA,RSA 单向加密 指只能加密数据,而不能解密数据 数据的完整性 MD5,SHA系列算法
对称加密:
非对称加密:
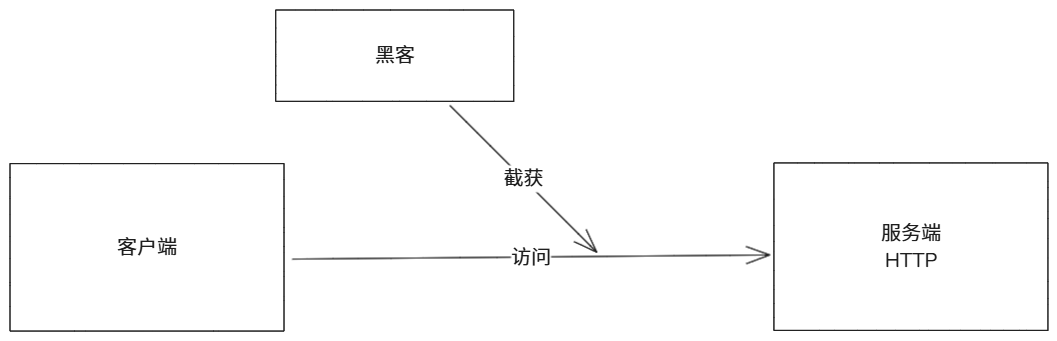
10-1.HTTPS加密过程
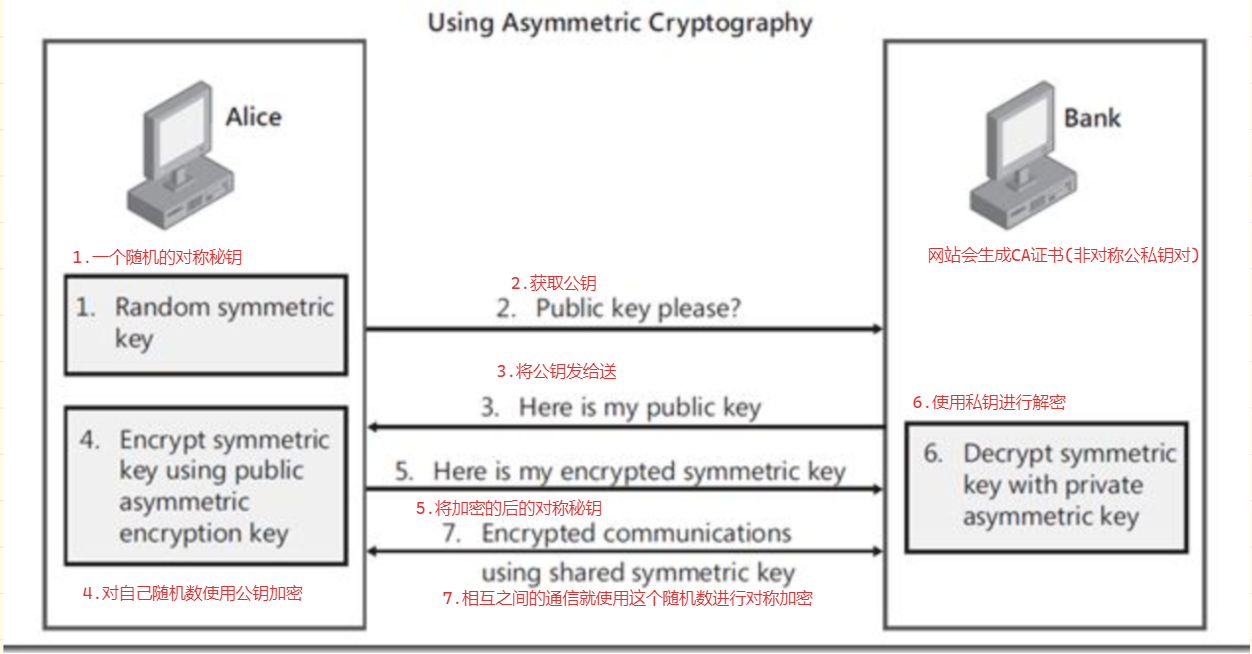
1.证书公钥加密:
证书:SSL/TLS 证书是一个数字文件,包含服务器的公钥、服务器的身份信息(如域名、组织名称等)以及证书颁发机构(CA)的签名。
公钥加密:客户端(如浏览器)使用服务器的公钥对数据进行加密。只有服务器持有对应的私钥,才能解密这些数据。这种方式确保了数据的隐私性。
2.对称加密(对称加密):
对会话加密:在建立安全连接后,客户端和服务器会协商生成一个对称加密密钥(称为会话密钥),用于加密和解密后续的通信数据。
对称加密:常见的对称加密算法包括AES(高级加密标准)、ChaCha20等。对称加密比公钥加密更高效,适合大量数据的加密。
3.身份验证:
证书验证:客户端通过验证服务器的SSL证书来确认服务器的身份。证书由受信任的证书颁发机构(CA)签发,客户端会检查证书的有效性、过期时间、域名匹配等信息。
双向认证:在某些场景下,服务器也可以要求客户端提供证书,进行双向身份验证。

10-2.HTTP与HTTPS安全区别
HTTPS:
- 可以理解HTTP + SSL/TLS 协议的总和。
- HTTPS通过在HTTP下使用SSL/TLS协议来加密数据传输,从而提供安全的Web通信。
- SSL/TLS 协议:SSL/TLS 协议位于传输层和应用层之间,为应用层协议提供安全服务,用于网络通信提供加密,身份验证和数据完整性保护。
- SSL/TLS 协议:它工作在传输层(如TCP)和应用层之间,可以为多种应用层协议(如HTTP、FTP、SMTP等)提供安全保障。
- SSL/TLS特点:通过使用公钥/私钥加密技术、数字证书和对称加密算法,确保数据在传输过程中的安全性和隐私性。
HTTP:
- 不使用SSL/TLS的HTTP通信,就是不加密的通信。所有信息明文传播,带来了三大风险。
- 窃听风险(eavesdropping):第三方可以获知通信内容。
- 篡改风险(tampering):第三方可以修改通信内容。
- 冒充风险(pretending):第三方可以冒充他人身份参与通信。
HTTPS:
- SSL/TLS协议是为了解决这三大风险而设计的,希望达到:
- 所有信息都是加密传播,第三方无法窃听。
- 具有校验机制,一旦被篡改,通信双方会立刻发现。
- 配备身份证书,防止身份被冒充。
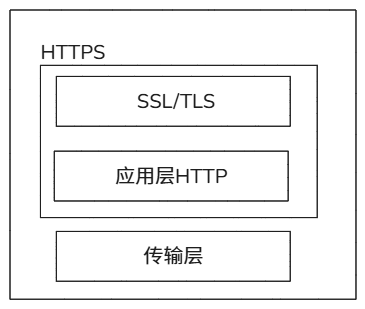

10-3.HTTPS证书
证书的方式:
- 自签名证书:有服务器自己签发的证书,不被浏览器信任,适用于开发环境。
- CA签发证书:由受信任的证书颁发机构签发的证书,浏览器会自动信任。
腾讯云关于证书的文档:https://cloud.tencent.com/document/product/400/7995
无证书:没有证书会被浏览器不信任,数据都是明文传输,会被黑客截取。
有证书:会被浏览器信任,图标也是不一样的。
证书的区别:
DV类型证书:
- 中文全称是域名验证型证书,证书审核方式为通过验证域名所有权即可签发证书。此类型证书适合个人和小微企业申请,价格较低,申请快捷,但是证书中无法显示企业信息,安全性较差。在浏览器中显示锁型标志。
OV类型证书:
- 中文全称是企业验证型证书,证书审核方式为通过验证域名所有权和申请企业的真实身份信息才能签发证书。目前OV类型证书是全球运用最广,兼容性最好的证书类型。此证书类型适合中型企业和互联网业务申请。在浏览器中显示锁型标志,并能通过点击查看到企业相关信息。支持ECC高安全强度加密算法,加密数据更加安全,加密性能更高。
EV类型证书:
- 中文全称是增强验证型证书,证书审核级别为所有类型最严格验证方式,在OV类型的验证基础上额外验证其他企业的相关信息,比如银行开户许可证书。EV类型证书多使用于银行,金融,证券,支付等高安全标准行业。其在地址栏可以显示独特的EV绿色标识地址栏,最大程度的标识出网站的可信级别。支持ECC高安全强度加密算法,加密数据更加安全,加密性能更高。

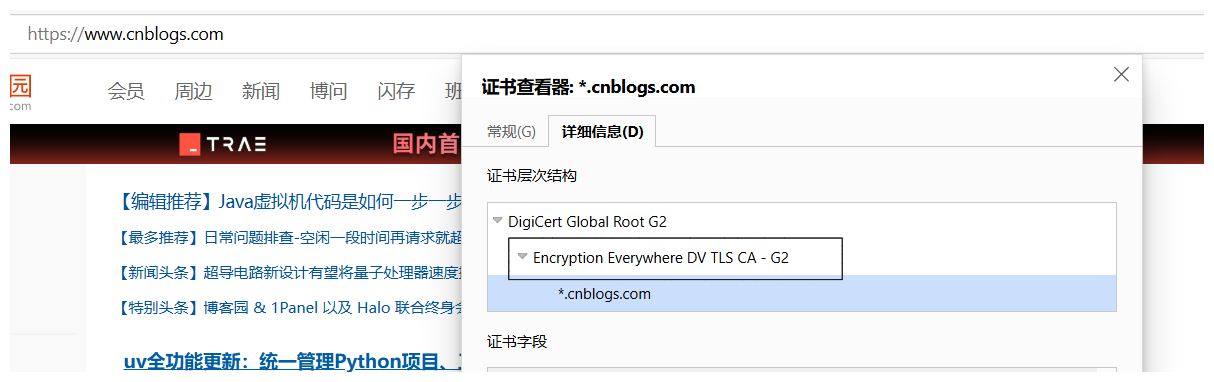
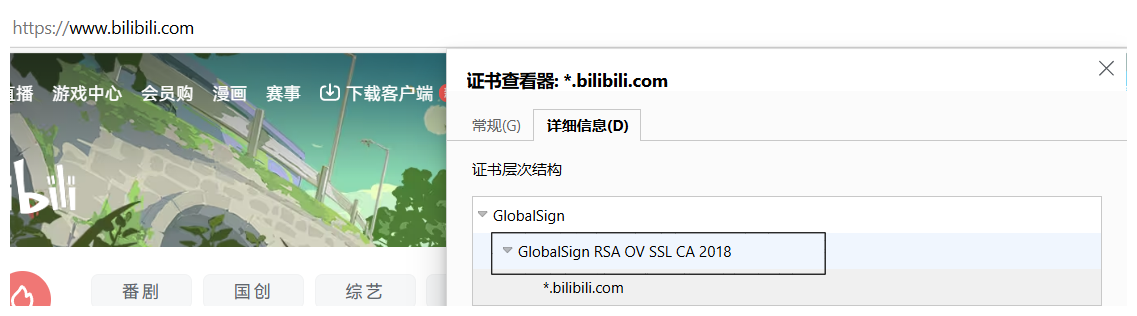
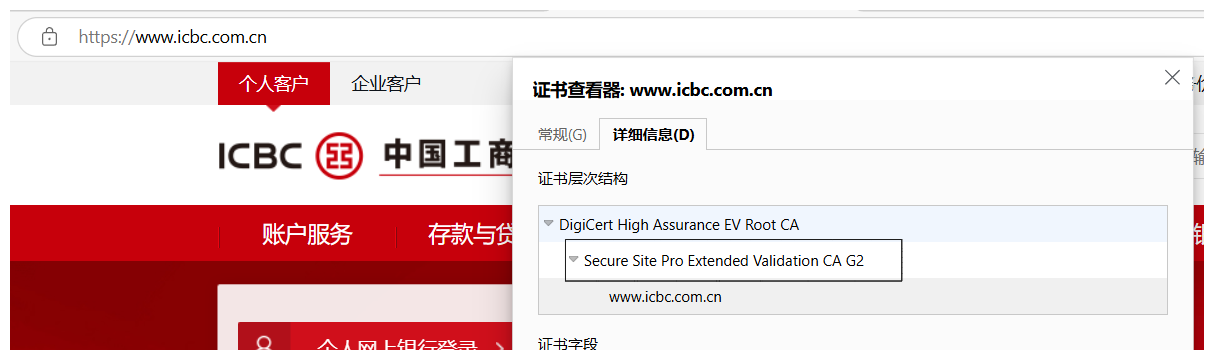
10-4.模块参数解释
| 指令 | 作用 |
|---|---|
ssl_certificate |
指定 SSL 证书文件的路径。SSL 证书通常包含了服务器的公钥和身份信息。 |
ssl_certificate_key |
指定 SSL 私钥文件的路径。私钥用于解密通过公钥加密的数据。 |
ssl_protocols |
指定 Nginx 支持的 SSL/TLS 协议版本,如 TLSv1.2 或 TLSv1.3。默认:ssl_protocols TLSv1.2 TLSv1.3; |
ssl_ciphers |
指定 Nginx 支持的加密套件(ciphers)。加密套件定义了加密算法、密钥交换算法和消息认证码(哪些加密算法组合来建立 SSL/TLS 连接。)。默认:ssl_ciphers HIGH:!aNULL:!MD5; |
ssl_session_cache |
指定 SSL 会话缓存的类型和大小。会话缓存可以提高 HTTPS 连接的建立速度。默认:ssl_session_cache none; |
ssl_session_timeout |
设置 SSL 会话的超时时间。默认:ssl_session_timeout 5m; |
ssl_session_tickets |
控制是否启用会话票据,这是一种会话恢复机制,可以在会话超时后恢复会话( 允许客户端和服务器在断开连接后重新建立连接时,不需要再次进行完整的握手过程,从而减少延迟和计算开销。)。默认:ssl_session_tickets on; |
# ssl_session_cache 指令:
none:不使用会话缓存。
builtin:使用 Nginx 内置的会话缓存,大小由第二个参数指定。
shared:使用共享内存来存储会话信息,适用于多进程模型,可以跨多个 worker 进程共享。
http {
...
server {
listen 443 ssl; # 使用HTTPS常规443端口 ssl 开启https
keepalive_timeout 70;
ssl_protocols TLSv1.2 TLSv1.3; # 支持的 SSL/TLS 协议版本
ssl_ciphers AES128-SHA:AES256-SHA:RC4-SHA:DES-CBC3-SHA:RC4-MD5; # 指定 Nginx 支持的加密套件
ssl_certificate /usr/local/nginx/conf/cert.pem; # 配置公钥
ssl_certificate_key /usr/local/nginx/conf/cert.key; # 配置私钥
ssl_session_cache shared:SSL:10m; # 使用共享内存来存储 SSL 会话信息,缓存大小为 10 MB。
ssl_session_timeout 10m; # 超时10分钟
}
}
10-5.部署操作-自签
# 自签的证书只能用于测试使用
1.安装自建证书的命令
yum install openssl openssl-devel -y
sudo apt intall openssl -y
2.使用OpenSSL生成一个私钥。以下命令将创建一个2048位的RSA私钥
sudo openssl genrsa -out private.key 2048
3.通过私钥生成一个自签名证书,需要填写一些信息,如国家,组织等等
sudo openssl req -days 36500 -x509 -sha256 -nodes -newkey rsa:2048 -keyout private.key -out certificate.crt
sudo openssl x509 -noout -text -in /etc/nginx/ssl_key/certificate.crt # 校验证书
# 参数解释:
req:基于req生成证书
-days 36500:设置证书过期时间 100年
-x509:类型
-newkey rsa:2048:基于rsa非对称加密生产的2048的文件
-keyout private.key:基于那个秘钥进行创建的公钥
-out certificate.crt:公钥出入到那个文件
4.部署测试
# 80 跳转443
server {
listen 80;
server_name abc.linux.cn;
location / {
rewrite ^(.*) https://$server_name$1 redirect;
}
}
server {
listen 443 ssl; # 配置443端口并且添加 ssl参数
server_name abc.linux.cn;
ssl_certificate /etc/nginx/ssl_key/certificate.crt; # ssl_certificate证书公钥文件
ssl_certificate_key /etc/nginx/ssl_key/private.key; # ssl_certificate_key 证书私钥文件
location / {
root /www/88/;
index index.html;
}
}
5.设置本地映射验证配置重启访问
# 本地映射
C:\Windows\System32\drivers\etc\hosts
10.0.0.88 abc.linux.cn
# 验证重启
sudo nginx -t
sudo systemctl restart nginx
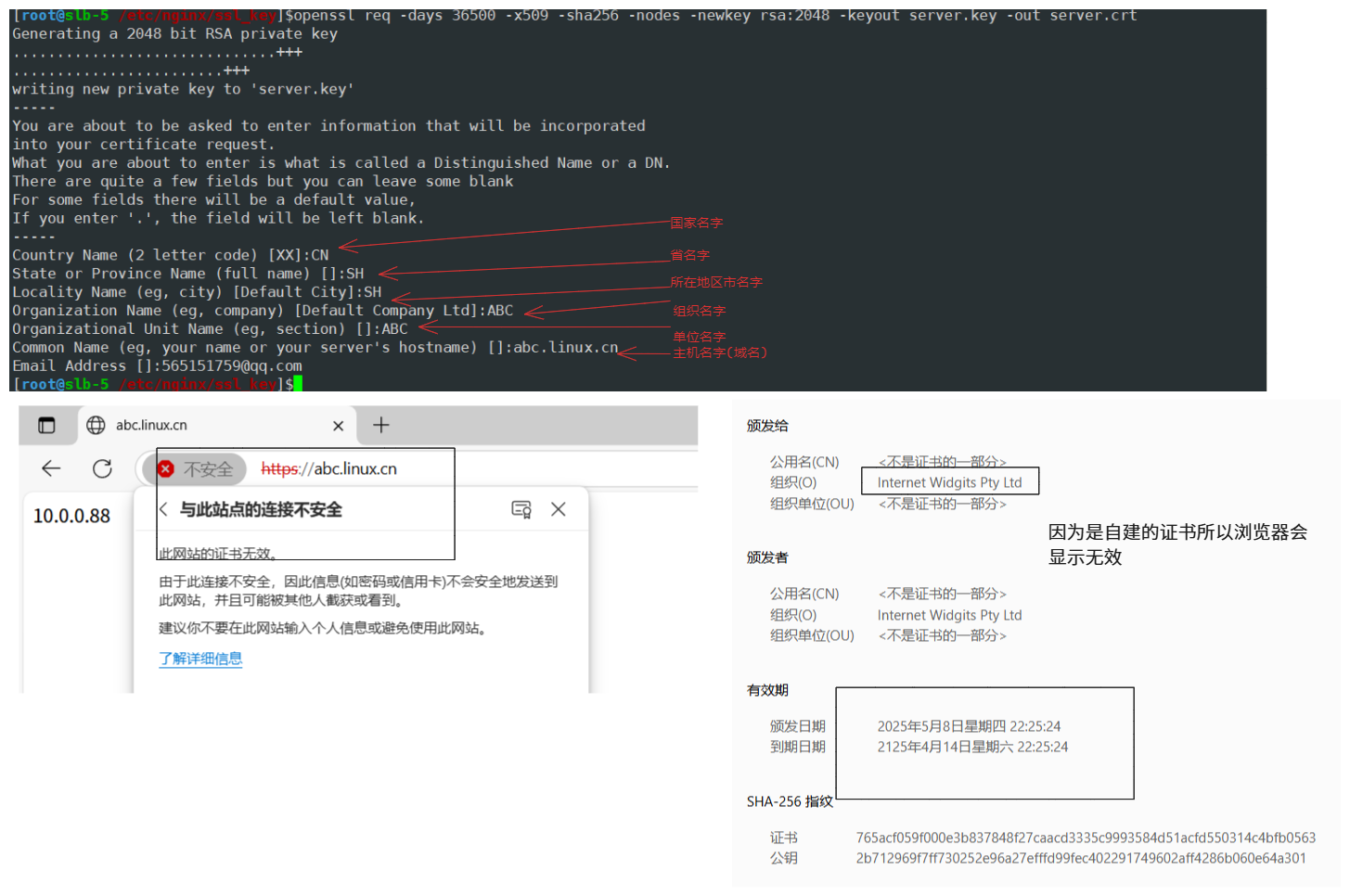
10-6.部署操作-CA签发
# 需要有自己的域名,并且在云厂商下载证书到本地
1.下载,上传到服务器中
2.配置部署
server {
listen 80;
server_name www.kaixinblog.cn;
location / {
rewrite ^(.*) https://$server_name$1 redirect;
}
}
server {
listen 443 ssl; # 配置443端口并且添加 ssl参数
server_name www.kaixinblog.cn;
ssl_certificate /etc/nginx/ssl_key/www.kaixinblog.cn.pem; # ssl_certificate证书公钥文件
ssl_certificate_key /etc/nginx/ssl_key/www.kaixinblog.cn.key; # ssl_certificate_key 证书私钥文件
location / {
root /www/88/;
index index.html;
}
}
3.设置本地映射验证配置重启访问
# 本地映射
C:\Windows\System32\drivers\etc\hosts
10.0.0.88 www.kaixinblog.cn
# 验证重启
sudo nginx -t
sudo systemctl restart nginx
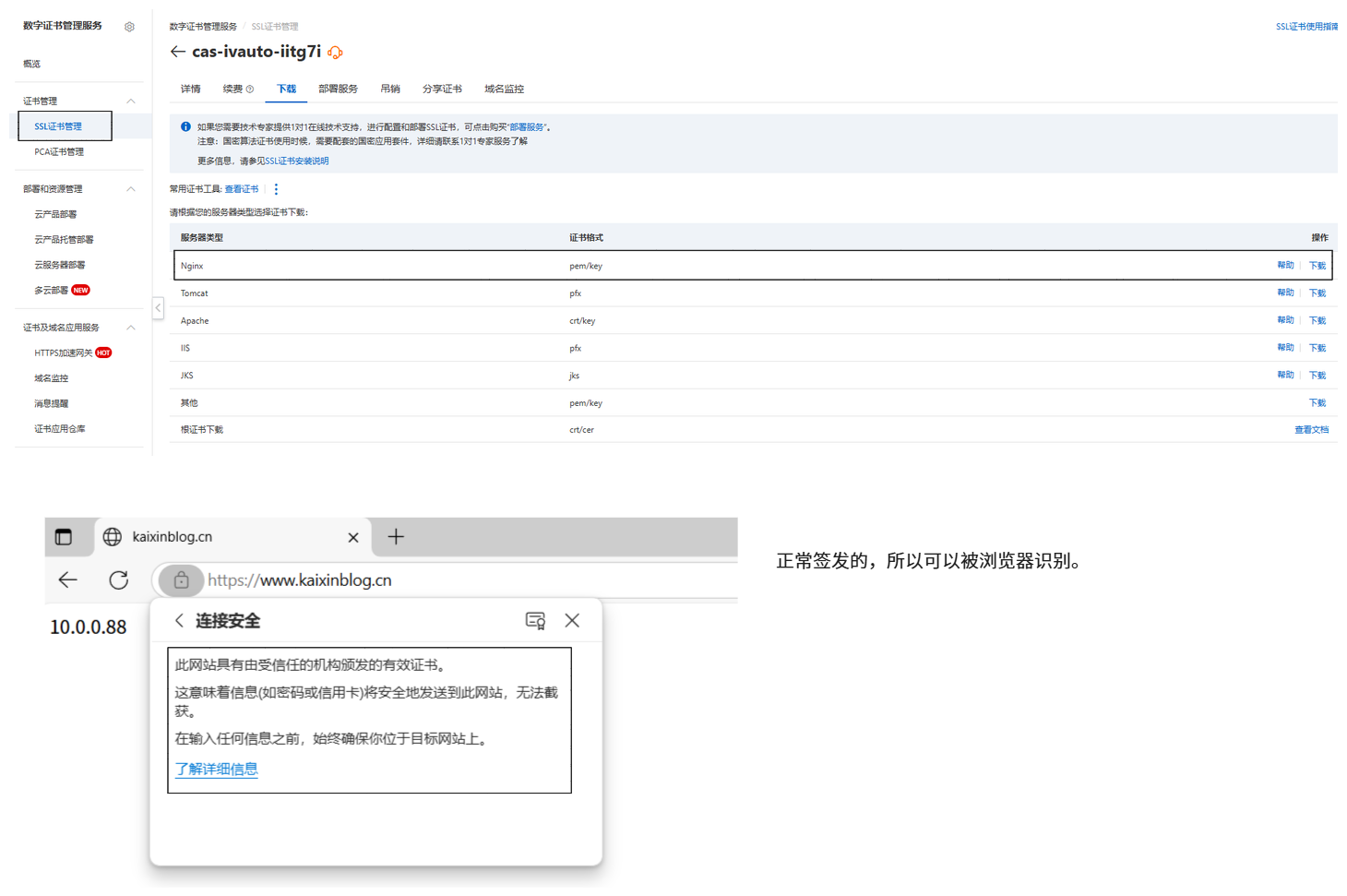
11.通过Nginx部署
11-1.LNMP单机架构
什么是LNMP:
- LNMP是一种流行的开源软件架构,广泛应用于Web应用程序的部署和动态网站的运行。它代表Linux操作系统、Nginx Web服务器、MySQL数据库管理系统(或MariaDB)以及PHP脚本处理语言。LNMP架构相比传统的LAMP(Linux + Apache + MySQL + PHP)架构,更注重高并发性能和资源利用率,适合现代高流量网站。
特点:
- LNMP架构中,Nginx是一个高性能的HTTP和反向代理Web服务器,同时也提供了IMAP/POP3/SMTP服务,其特点是占有内存少,并发能力强。MySQL是一种开放源代码的关系型数据库管理系统(RDBMS),使用最常用的数据库管理语言--结构化查询语言(SQL)进行数据库管理。PHP即“超文本预处理器”,是一种通用开源脚本语言。
为什么使用:
- 在创业初期,研发资源有限,研发人力有限,技术储备有限,需要选择一个易维护、简单的技术架构。
- 产品需要快速研发上线,并能够满足快速迭代要求,现实情况决定了一开始没有时间和精力来选择一个过于复杂的分布式架构系统,研发速度必须要快。
- 创业初期,业务复杂度比较低,业务量也比较小,如果选择过于复杂的架构,反而会增加研发难度以及运维难度。
- 遵从选择合适的技术而不是最好的技术原则,并权衡研发效率和产品目标,同时创业初期只有一个PHP研发人员,过于复杂的技术架构必然会带来比较高昂的学习成本。
- 基于如上的因素,LNMP架构就是最合适的。简单成本低,速度快。在盈利后,可以将动态语言的后端转换为静态语言的后端,这样可以提高更高的并发。
- 类似于这种架构:一般三台服务器足以,Nginx与后台系统部署在一台机器,Mysql数据库单独服务器,redis缓存一台服务器。
架构优势:
- 单体架构,架构简单,清晰的分层结构。
- 可以快速研发,满足产品快速迭代要求
- 没有复杂的技术,技术学习成本低,同时运维成本低,无需专业的运维(开发一般忙不过来,任何大小的公司,都至少得有一个运维,除非真的是一个很烂的小作坊),节省开支。
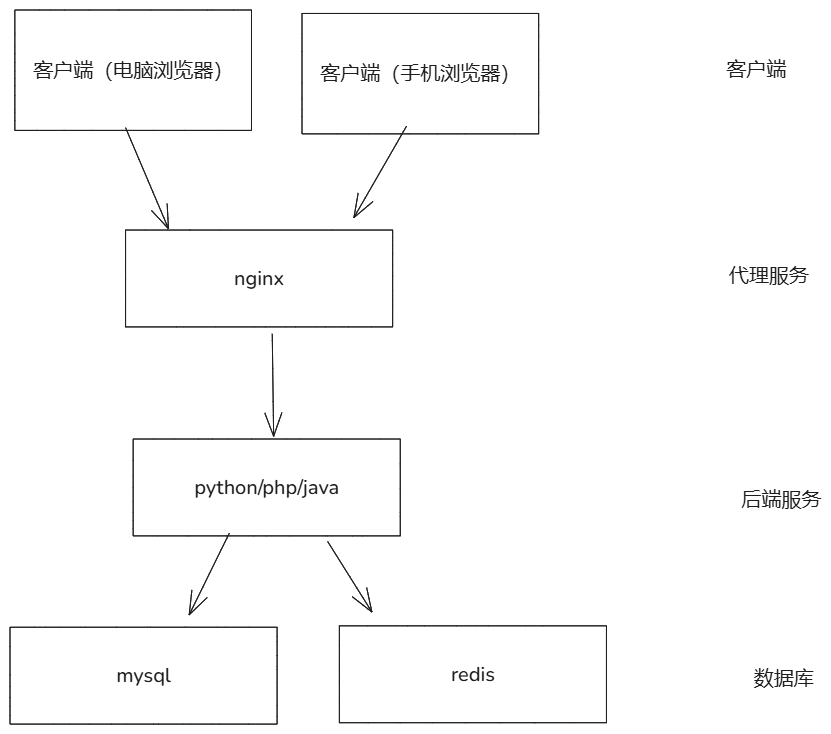
11-2.集群架构
什么是集群:
- 一堆机器,做同一件事情,集群服务器,只有基于集群的环境才能实现负载均衡,2个机器以上组成了一个集群,也就是一堆机器提供了一个网站的服务。
概念:
集群就是指一组(若干个)相互独立的计算机,利用高速通信网络组成的一个较大的计算机服务系统,每个集群节点(即集群中的每台计算机)都是运行各自服务的独立服务器。这些服务器之间可以彼此通信,协同向用户提供应用程序,系统资源和数据,并以单一系统的模式加以管理。当用户请求集群系统时,集群给用户的感觉就是一个单一独立的服务器,而实际上用户请求的是一组集群服务器。- 例如:打开谷歌,百度的页面,看起来好简单,也许你觉得用几分钟就可以制作出相似的网页,而实际上,这个页面的背后是由成千上万台服务器集群协同工作的结果。若要用一句话描述集群,即一堆服务器合作做同一件事,这些机器可能需要统一协调管理,可以分布在一个机房,也可以分布在全国全球各个地区的多个机房。和传统的高性能计算机技术相比,集群技术可以利用各档次的服务器作为节点,系统造价低,可以实现很高的运算速度,完成大运算量的计算,具有较高的响应能力,能够满足当今日益增长的信息服务的需求。
- 集群技术是一种通用的技术,其目的是为了解决单机运算能力的不足、IO能力的不足、提高服务的可靠性、获得规模可扩展能力,降低整体方案的运维成本(运行、升级、维护成本)。只要在其他技术不能达到以上的目的,或者虽然能够达到以上的目的,但是成本过高的情况下,就可以考虑采用集群技术。
- 集群就是一堆服务器同时干一件事。比如提供网页功能。
为什么需要集群:
- 高性能:比如一些国家的计算密集型(天气采集等...)。需要计算机很强大的运算处理能力,即使大型计算机的算力也是有限,很难单独完成任务。
- 因为计算时间可能会相当长,也许几天,甚至几年或更久。 因此,对于这类复杂的计算业务,便使用了计算机集群技术,集中几十上百台,甚至成千上万台计算机进行计算。
- 假如你配一个LNMP环境,每次只需要服务10个并发请求,那么单台服务器一定会比多个服务器集群要快。 只有当并发或总请求数量超过单台服务器的承受能力时,服务器集群才会体现出优势。
- 简单来说就类似于盖楼房,1个人可以盖,但是需要很久很久才能完成。
- 价格有效性:通常一套系统集群架构,只需要几台或数十台服务器主机即可。与动辄价值上百万元的专用超级计算机相比便宜了很多。在达到同样性能需求的条件下,采用计算机集群架构比采用同等运算能力的大型计算机具有更高的性价比。
- 早期的淘宝,支付宝的数据库等核心系统就是使用上百万元的小型机服务器。
- 后因使用维护成本太高以及扩展设备费用成几何级数翻倍,甚至成为扩展瓶颈,人员维护也十分困难,最终使用PC服务器集群替换之,比如,把数据库系统从小机结合Oracle数据库迁移到MySQL开源数据库结合PC服务器上来。 不但成本下降了,扩展和维护也更容易了。
- 可伸缩性:当服务负载,压力增长时,针对集群系统进行较简单的扩展即可满足需求,且不会降低服务质量。
- 通常情况下,硬件设备若想扩展性能,不得不增加新的CPU和存储器设备,如果加不上去了,就不得不购买更高性能的服务器,就拿我们现在的服务器来讲,可以增加的设备总是有限的。
- 如果采用集群技术,则只需要将新的单个服务器加入现有集群架构中即可,从访问的客户角度来看,系统服务无论是连续性还是性能上都几乎没有变化,系统在不知不觉中完成了升级,加大了访问能力,轻松地实现了扩展。
- 集群系统中的节点数目可以增长到几千乃至上万个,其伸缩性远超过单台超级计算机。
- 高可用性: 单一的计算机系统总会面临设备损毁的问题,如CPU,内存,主板,电源,硬盘等,只要一个部件坏掉,这个计算机系统就可能会宕机,无法正常提供服务。在集群系统中,尽管部分硬件和软件也还是会发生故障,但整个系统的服务可以是7*24小时可用的。
- 集群架构技术可以使得系统在若干硬件设备故障发生时仍可以继续工作,这样就将系统的停机时间减少到了最小。
- 集群系统在提高系统可靠性的同时,也大大减小了系统故障带来的业务损失,目前几乎100%的互联网网站都要求7*24小时提供服务。
- 透明性:多个独立计算机组成的松耦合集群系统构成一个虚拟服务器。
- 用户或客户端程序访问集群系统时,就像访问一台高性能,高可用的服务器一样,集群中一部分服务器的上线,下线不会中断整个系统服务,这对用户也是透明的。
- 可管理性:整个系统可能在物理上很大,但其实容易管理,就像管理一个单一映像系统一样。在理想状况下,软硬件模块的插入能做到即插即用。
- 可编程性:在集群系统上,容易开发及修改各类应用程序。
集群的分类:
- 负载均衡集群
- 目的是将工作负载均匀地分配到多个节点上,以提高系统的整体性能和响应速度。
- 常用于Web服务器、应用服务器等需要处理大量并发请求的场景。
- 高可用性集群
- 目的是确保系统在硬件或软件故障时仍能继续运行。
- 通过冗余和故障转移机制来实现服务的不间断运行。
- 常用于数据库服务器、应用服务器等关键业务系统。

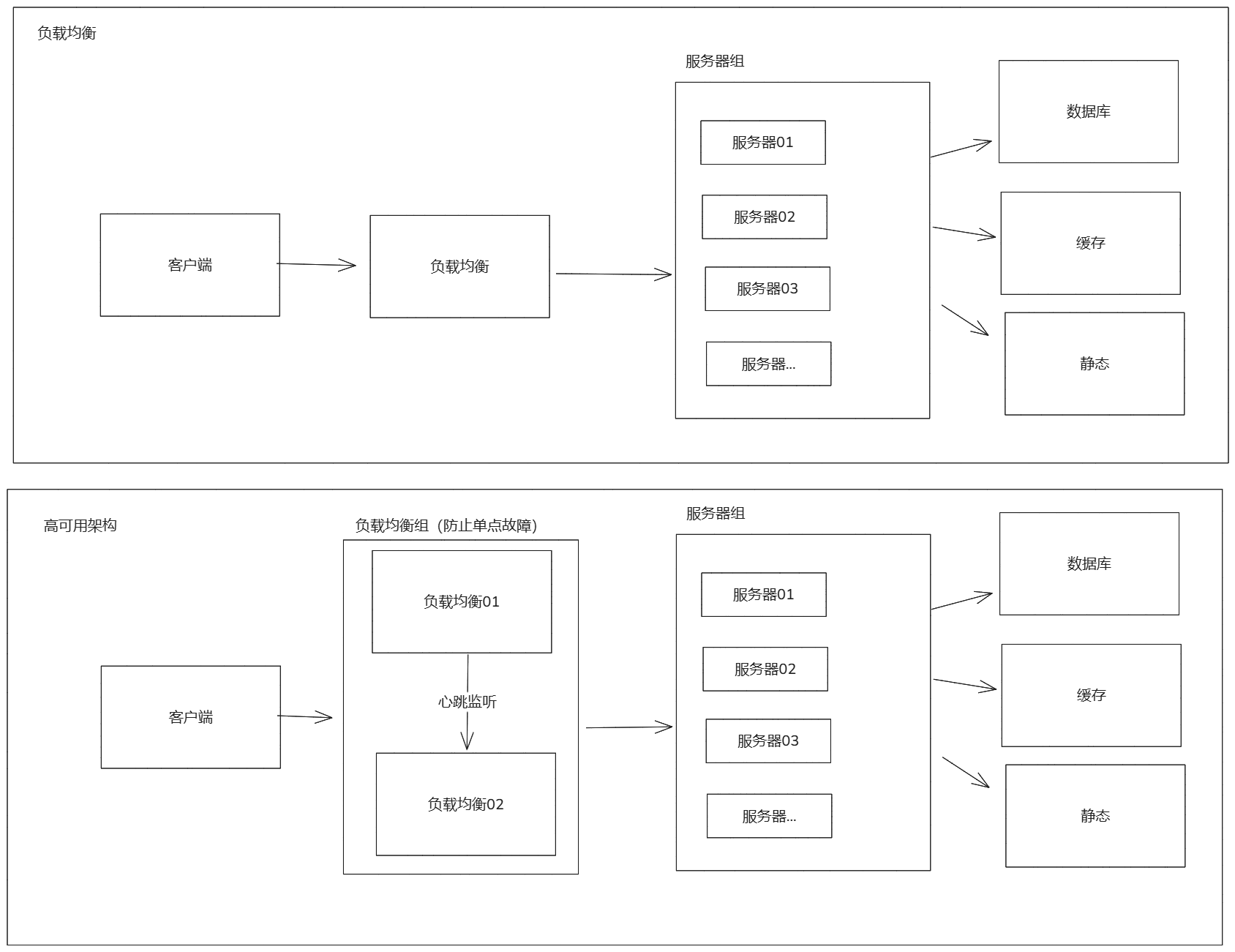
11-2-1.负载均衡架构
- 负载均衡集群为企业提供了更为实用,性价比更高的系统架构解决方案。
说明:
- 负载均衡集群可以把很多客户集中的访问请求负载压力尽可能平均地分摊在
服务器集群中处理。客户访问请求负载通常包括应用程序处理负载和网络流量负载。
- 网络负载: 用户通过客户端访问服务器。
- 应用程序处理负载: 用户发送的请求需要服务器的后端程序进行处理的逻辑(请求数据库,写入,等等)。
- 这样的系统非常适合使用同一组应用程序为大量用户提供服务的模式,每个节点都可以承担一定的访问请求负载压力,并且可以实现访问请求在各节点之间动态分配,以实现负载均衡。
- 负载均衡集群运行时,一般是通过一个或多个前端负载均衡器将客户访问请求分发到后端的一组服务器上,从而达到整个系统的高性能和高可用性。一般高可用性集群和负载均衡集群会使用类似的技术,或同时具有高可用性与负载均衡的特点。
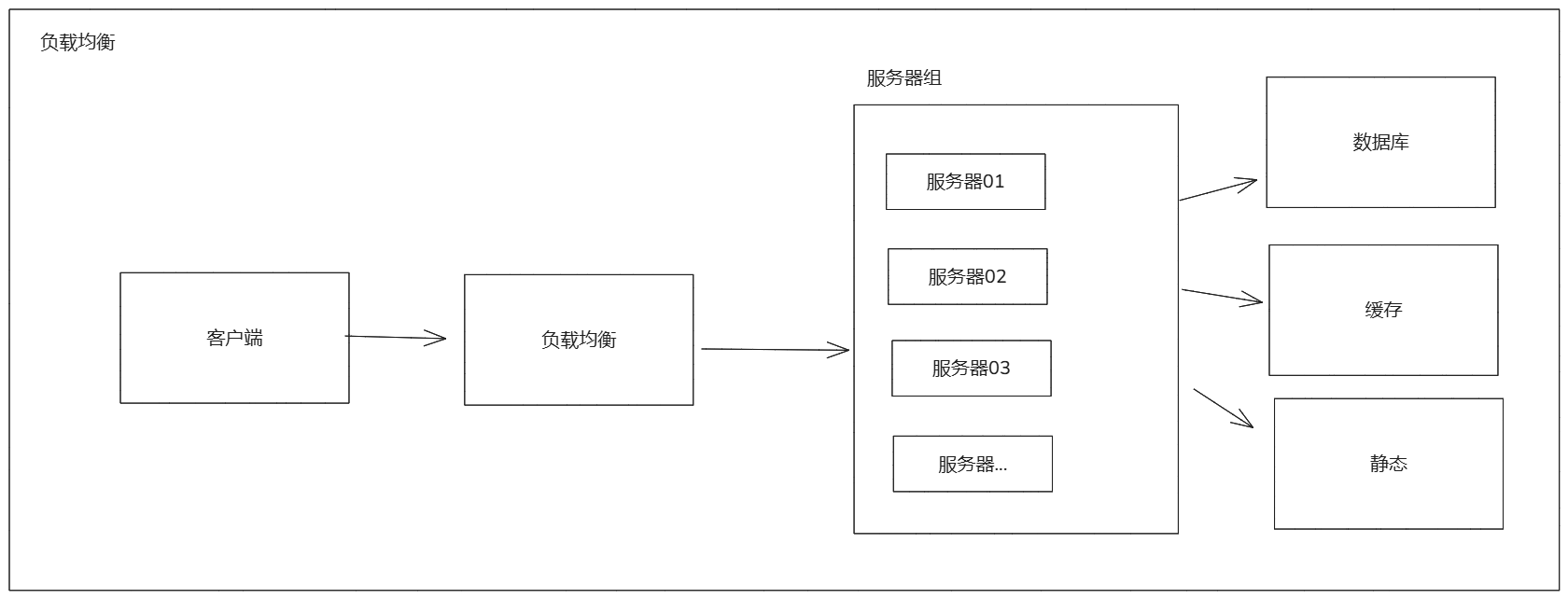
11-2-1.高可用架构
- 作用负载均衡集群针对这种单机的负载均衡器还是存在风险,那么作为网站入口的负载均衡器挂了,那么就会导致用户无法访问公司的网站,业务无法展开。
说明:
- 在集群中任意一个节点失效的情况下,该节点上的所有任务会自动转移到其他正常的节点上。此过程并不影响整个集群的运行。
- 当集群中的一个节点系统发生故障时,运行着的集群服务会迅速作出反应,将该系统的服务分配到集群中其他正在工作的系统上运行。考虑到计算机硬件和软件的容错性,高可用性集群的主要目的是使集群的整体服务尽可能可用(单点状态下不行)。
- 如果高可用性集群中的主节点发生了故障,那么这段时间内将由备节点代替它。备节点通常是主节点的镜像。当它代替主节点时,它可以完全接管主节点(包括IP地址及其他资源)提供服务,因此,使集群系统环境对于用户来说是一致的,即不会影响用户的访问。
- 高可用性集群使服务器系统的运行速度和响应速度会尽可能的快。他们经常利用在多台机器上运行的
冗余节点来相互跟踪。如果某个节点失败,它的替补者将在几秒钟或更短时间内接管它的职责。因此,对于用户而言,集群里的任意一台机器宕机,业务都不会受影响(理论情况下)。
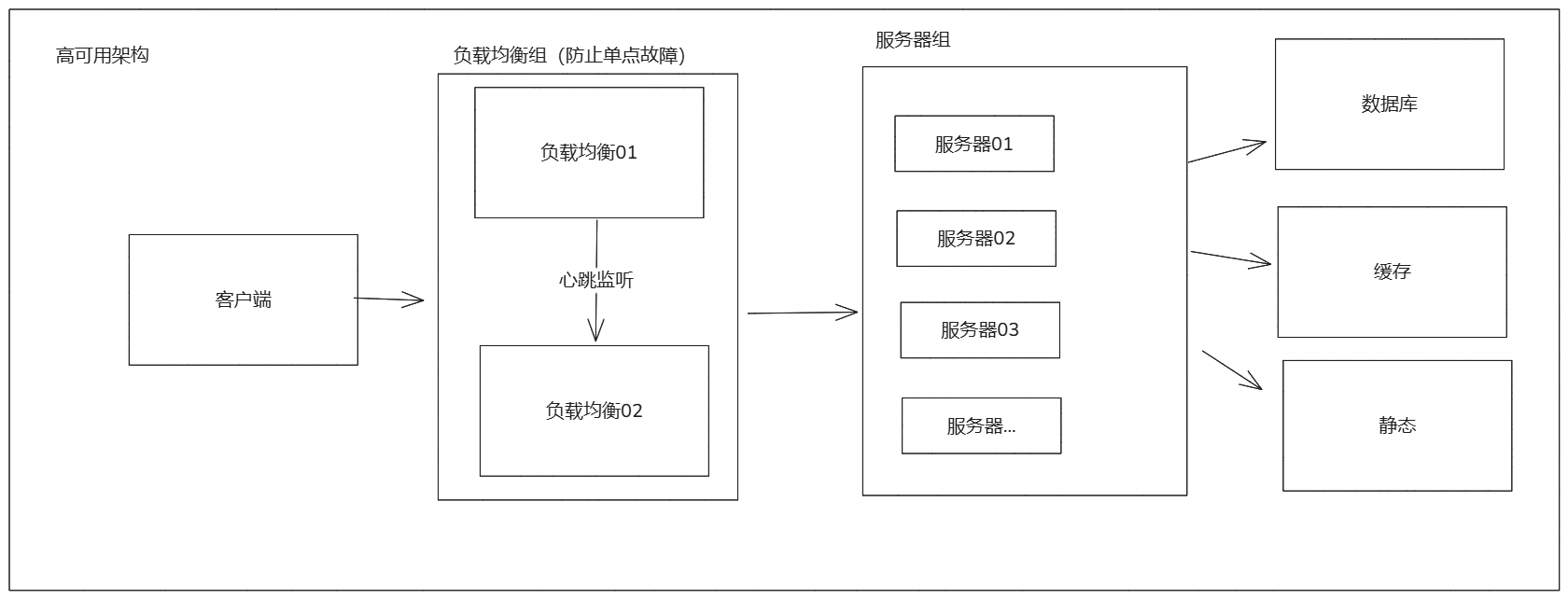
11-2-3总结
# 负载均衡架构,是为了让服务器可以承受跟高的并发请求。高可用架构,是为了防止单点故障。
11-3.云服务器实际部署
11-4.前后端分离部署
11-4-1.安装前端环境
# ubuntu
1.安装nodejs
sudo curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
sudo apt install -y nodejs
2.安装vue环境
sudo npm config set registry https://registry.npmmirror.com/ --global # 配置源
sudo npm install -g @vue/cli --registry=https://registry.npmmirror.com
sudo npm install -g yarn --registry=https://registry.npmmirror.com
3.创建一个vue项目
sudo vue create vue-test && cd vue-test
sudo yarn add axios
4.在src/main.js添加
import axios from 'axios'// 1.导入axios包
Vue.prototype.$http = axios // 2.全局挂载
5.在vue.config.js添加
module.exports = {
lintOnSave: false
};
6.在文件某个路由下的vue文件中添加上接口
# 使用相对路径
this.$http.get('/api/index').then(res=>{
if(res.data.code === 200){
this.text = res.data.msg;
}
}).catch(error=>{
console.log(error); // 发生报错
})
7.打包为静态文件
sudo yarn build && sudo mv dist/ /etc/nginx
11-4-2.后端接口
1.创建 app.py 文件
from flask import Flask, jsonify
app = Flask(__file__)
@app.route("/api/index")
def index():
return jsonify({
"code": 200,
"msg": "后端接口/api/index",
})
if __name__ == "__main__":
app.run()
2.启动
python3 app.py
11-4-3.nginx配置文件
1.配置
server {
listen 80;
server_name _;
location / {
root /etc/nginx/dist/; # 前端文件所在目录
index index.html;
try_files $uri $uri/ /index.html;
}
location /api/ {
proxy_pass http://127.0.0.1:5000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
2.重启nginx并访问
systemctl restart nginx
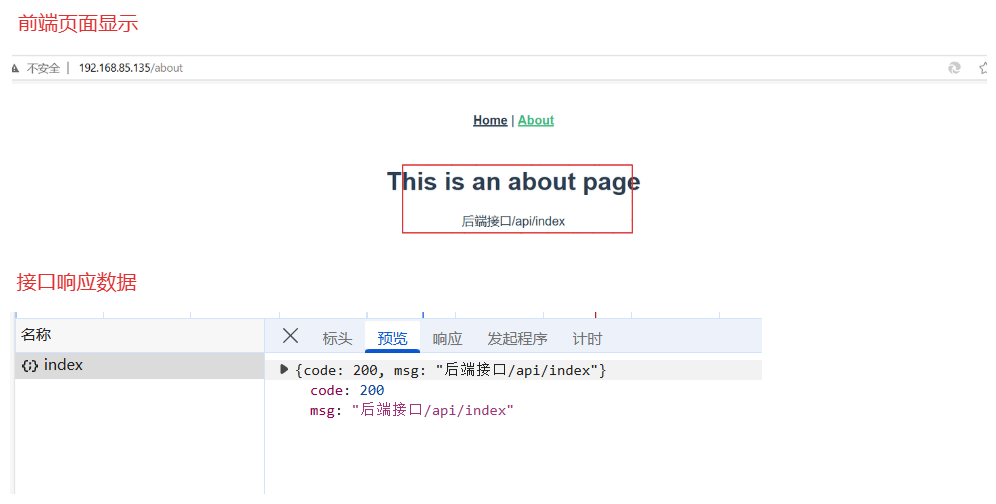
11-4-4.高可用不分离图解
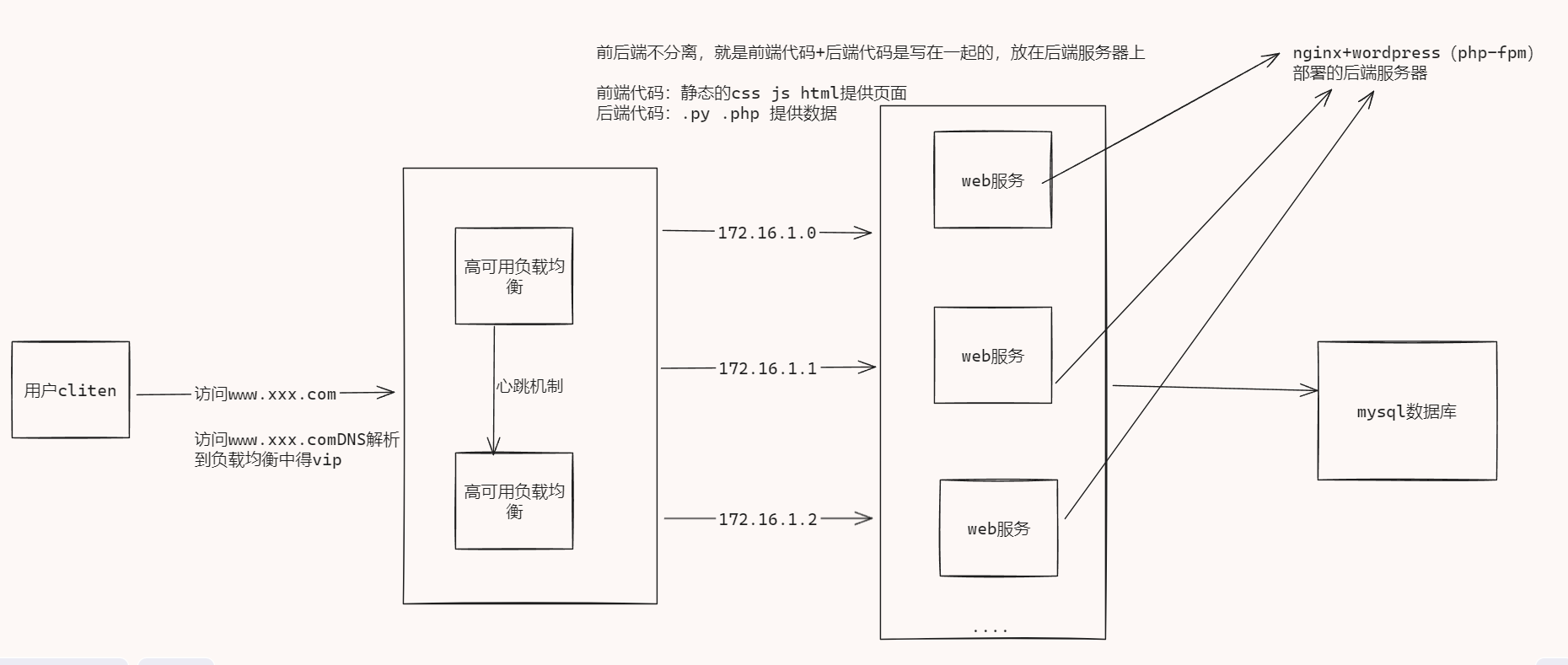
11-4-5.高可用分离图解
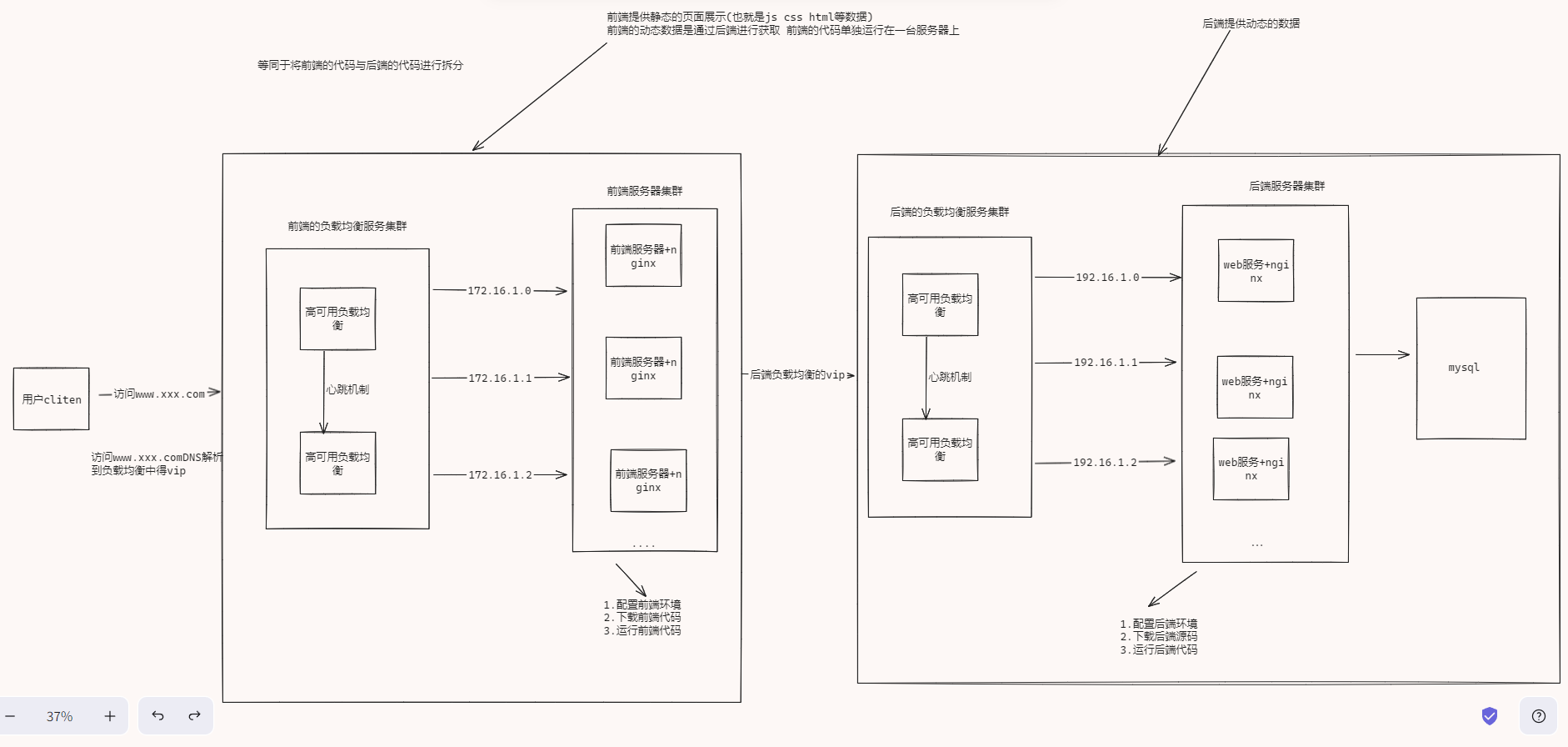
11-5.部署Python程序
- 实现 linux(centos7)+ python+ nginx +mysql的部署操作。
11-5-1.环境-编译安装
1.安装依赖
sudo yum groupinstall "Development Tools"
sudo yum install gcc patch libffi-devel python-devel zlib-devel bzip2 bzip2-devel openssl-devel ncurses-devel sqlite-devel sqlite readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz xz-devel -y # centos7
sudo apt install build-essential zlib1g-dev libncurses5-dev libgdbm-dev libnss3-dev libssl-dev libreadline-dev libffi-dev wget libsqlite3-dev # ubuntu
2.下载
wget https://www.python.org/ftp/python/3.6.9/Python-3.6.9.tgz
wget https://www.python.org/ftp/python/3.9.10/Python-3.9.10.tgz # 安装3.9.10
3.解压
tar -zxf Python-3.6.9.tgz && cd Python-3.6.9
4.安装
./configure --prefix=/opt/python3
make -j${nproc} && make install # 或 make altinstall
5.设置临时环境变量
export PATH=${PATH}:/opt/python3/bin/
6.查看pip 与 python
pip3.9 -V
python3.9 -V

11-5-2.Flask框架项目部署-gunicorn
1.安装flask与gunicorn # 可以使用 uWSGI
pip3.9 install flask -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3.9 install gunicorn -i https://pypi.tuna.tsinghua.edu.cn/simple # 也可以使用uwsgi进行部署
2.创建一个flask的代码
mkdir /opt/test_flask
vim /opt/test_flask/app.py
# python 代码
from flask import Flask
app = Flask(__file__)
@app.route("/")
def index():
return "flask 框架", 200
if __name__ == "__main__":
app.run()
3.启动测试
python3.9 /opt/test_flask/app.py
4.使用gunicorn命令行模式启动flask框架
gunicorn -w 4 -b 127.0.0.1:8000 app:app
gunicorn:这是启动 Gunicorn 服务器的命令。
-w 4: 这个参数指定了 Gunicorn 启动时使用的 worker(工作进程)数目
-b 127.0.0.1:8000: 这个参数指定了 Gunicorn 监听的 IP 地址和端口号。
app:app: 这部分指定了要运行的应用程序。第一个app代表你项目中的app.py文件,app是当前 app= Flask(__file__) 这个app对象,'因为我的入口文件时app,flask对象也是app所以就是app'。
5.使用gunicorn文件配置启动方式 # 常用
vim /opt/test_flask/gunicorn.conf.py
bind = '127.0.0.1:8000'
workers = 4
worker_class = 'gthread'
threads = 2
timeout = 60
keepalive = 2
graceful_timeout = 30
loglevel = 'info'
accesslog = '/opt/test_flask/access.log'
errorlog = '/opt/test_flask/error.log'
daemon = True
chdir = '/'
# 启动命令 -c 指定配置文件
gunicorn -c /opt/test_flask/gunicorn.conf.py opt.test_flask.app:app
opt.test_flask.app:app: 就是:/opt/test_flask/app.py 内的 app= Flask(__file__) 这个对象
# 注意:
1.如果你在文件项目文件内 /opt/test_flask/ 执行命令:'gunicorn -c /opt/test_flask/gunicorn.conf.py opt.test_flask.app:app' 是无法启动的,它会找到你当前目录下 /opt/test_flask/opt/test_flask/app.py 的入口文件启动,这样是错误的,如果需要再/opt/test_flask/文件内启动,命令:'gunicorn -c /opt/test_flask/gunicorn.conf.py app:app' 修改。
2.如果使用'gunicorn -c /opt/test_flask/gunicorn.conf.py opt.test_flask.app:app'启动,就需要再根目录下执行这条命令
3.如果配置 chdir = '/' 参数,在你使用 gunicorn 命令时,就会从linux的跟目录启动,那么就需要 opt.test_flask.app:app 从根目录指定到项目的启动文件。
6.编写配置文件,进行反向代理
server {
listen 80;
server_name _;
location / {
proxy_pass http://127.0.0.1:8000; # 转发到 Gunicorn 服务
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
7.访问
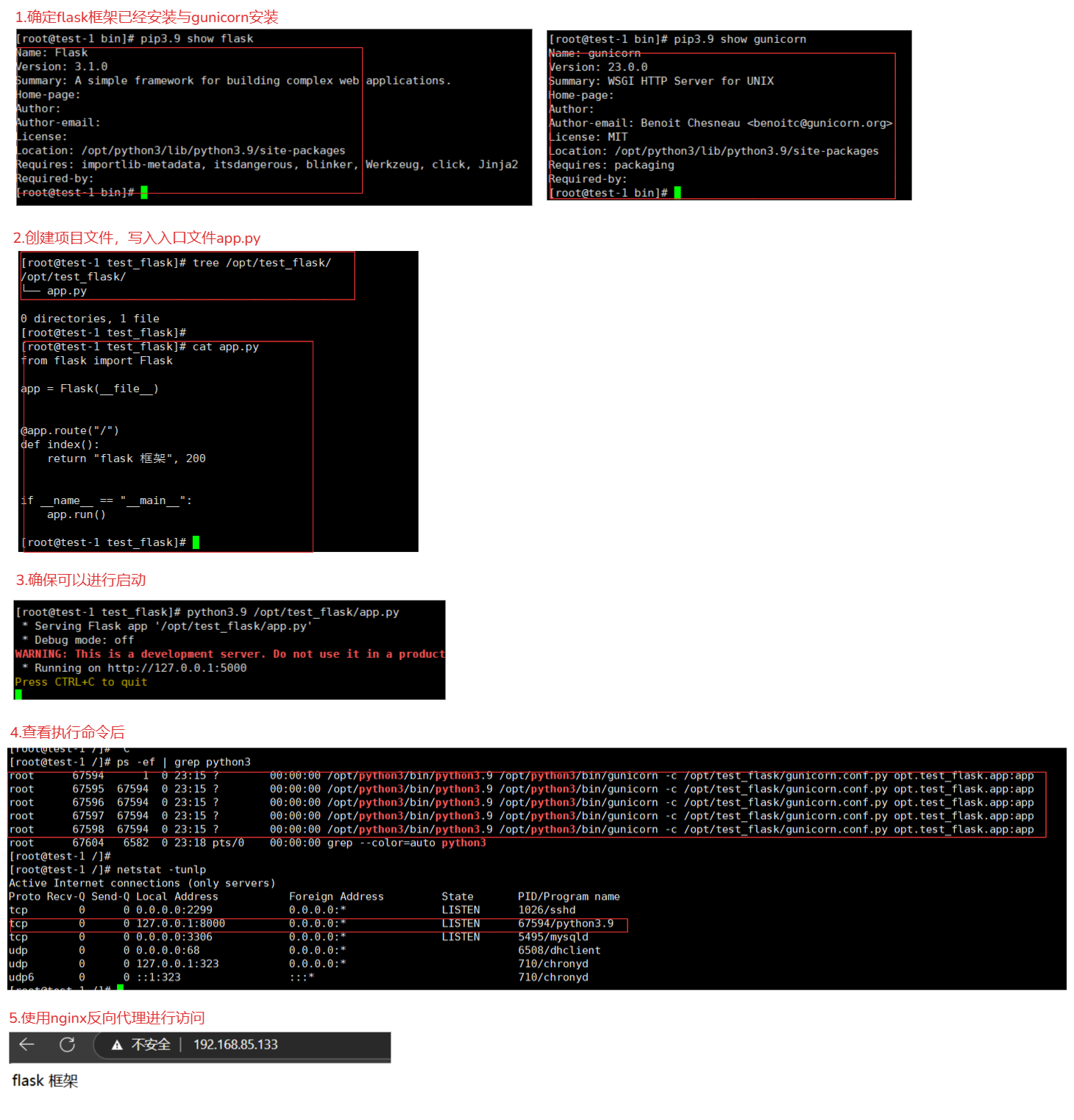
11-5-3.gunicorn配置说明文件
- Gunicorn 是一个基于 HTTP 协议的 WSGI 服务器,它通过标准的 HTTP 协议与客户端通信。
- 当你使用 Nginx 作为反向代理时,只需要将请求转发到 Gunicorn 监听的地址即可,而不需要使用特殊的协议(如 uWSGI 协议)。
- 所以在 Nginx 配置文件中使用
proxy_pass,而不是uwsgi_pass。 - 文档:https://gunicorn.org/
- 建议最好使用
Supervisor管理Gunicorn。
1.配置参数说明:
bind = '0.0.0.0:8000' # 监听的 IP 地址和端口号
workers = 4 # 进程数,根据服务器性能进行调整
worker_class = 'gthread' # 工作模式,可选值有 sync, eventlet, gevent, tornado, gthread 等
threads = 2 # 每个工作进程的线程数
timeout = 60 # 请求超时时间,单位为秒
keepalive = 2 # 长连接超时时间
graceful_timeout = 30 # 优雅关闭超时时间
loglevel = 'info' # 日志级别,可选值有 debug, info, warning, error, critical
accesslog = '-' # 访问日志输出位置,这里配置为标准输出
errorlog = '-' # 错误日志输出位置,这里配置为标准输出
worker_connections = 1000 # 每个 worker 进程允许的最大并发连接数
backlog = 2048 # 允许的挂起连接数,超过这个数目的连接将被拒绝
preload_app = True # 是否在 master 进程启动时加载应用程序。设置为 True 可以减少 worker 进程的启动时间
daemon = False # 是否以守护进程模式运行 Gunicorn 后台运行
pidfile = /tmp/gunicorn.pid # 存储 master 进程 ID 的文件路径
user = nginx # 用户
group = nginx # 用户组
umask = 0 # 设置 worker 进程的文件创建掩码
raw_env = [] # 设置环境变量
chdir = '/' # 切换到指定目录
proc_name = 'gunicorn' # 设置 Gunicorn 的进程名
limit_request_line = 4094 # 请求行的最大大小
limit_request_fields = 100 # 请求头字段的最大数量
limit_request_field_size = 8190 # 请求头字段的最大大小
2.关闭与启动
# 启动
gunicorn -c /opt/flask_app/gunicorn.conf.py opt.flask_app.app:app
-c /opt/flask_app/gunicorn.conf.py : 指定gunicorn的配置文件
opt.flask_app.app:app:从项目目录到入口文件的flask对象
# 关闭,使用kill命令直接终止进程
ps -ef | grep python3
kill -INT <pid>
ps -ef | grep python3 # 查看一下就可以了
11-5-4.Dajngo框架项目部署-uwgis
1.安装django与uwsgi
pip3.9 install django==2.1.7 -i https://pypi.tuna.tsinghua.edu.cn/simple # 避免出现SQLite数据库问题
pip3.9 install uwsgi -i https://pypi.tuna.tsinghua.edu.cn/simple
2.uwsgi编译安装方式
wget http://projects.unbit.it/downloads/uwsgi-lts.tar.gz
tar -zxf uwsgi-lts.tar.gz && cd uwsgi-2.0.20
make # 就会在当前目录下获取一个二进制命令
ln -s /opt/uwsgi-2.0.20/uwsgi /usr/bin/uwsgi # 软连接
3.创建一个django项目,启动测试
django-admin startproject test_django
python3.9 /opt/test_django/manage.py runserver # 启动
# 在django配置settings.py文件中修改
ALLOWED_HOSTS = ["*"]
4.创建uwsgi.ini配置文件
vim /opt/test_django/uwsgi.ini
[uwsgi]
uid = root
gid = root
# socket = /tmp/uwsgi/uwsgi.sock # 使用uwsgi协议使用的uwsgi_pass反向代理uwsgi_pass unix:///tmp/uwsgi/uwsgi.sock;
socket = 127.0.0.1:8000 # 使用uwsgi协议,使用的uwsgi_pass反向代理 uwsgi_pass uwsgi://127.0.0.1:8000;
# http = 127.0.0.1:9090 # 使用的http协议,使用nginx的proxy_pass反向代理。可以http://127.0.0.1:9090 访问
master = true
workers = 2
processes = 4
threads = 2
vacuum = true
max-request = 1000
pidfile = /tmp/uwsgi/uwsgi.pid
daemonize =/tmp/uwsgi/uwsgi.log
logformat = %(addr) - %(user) | %(ltime) | pid:%(pid) wid:%(wid) | %(proto) %(status) | %(method) | %(host)%(uri) | request_body_size:%(cl) | response_body_size:%(rsize)
limit-as = 512
chdir = /opt/test_django/
module = test_django.wsgi
5.启动使用
uwsgi --ini /opt/test_django/uwsgi.ini
6.配置nginx配置文件
server {
listen 80;
server_name _;
location / {
include uwsgi_params;
uwsgi_pass uwsgi://127.0.0.1:8000;
uwsgi_param UWSGI_SCRIPT test_django.wsgi.py; # 配置wsgi的启动文件
uwsgi_param UWSGI_CHDIR /opt/test_django/; # 项目的跟目录
uwsgi_temp_file_write_size 256k;
uwsgi_busy_buffers_size 256k;
uwsgi_buffers 16 256k;
uwsgi_buffer_size 128k;
uwsgi_read_timeout 10s;
uwsgi_send_timeout 10s;
uwsgi_connect_timeout 10s;
}
}
7.浏览器访问
# using kill to send the signal
kill -HUP `cat /tmp/project-master.pid`
# or the convenience option --reload
uwsgi --reload /tmp/project-master.pid
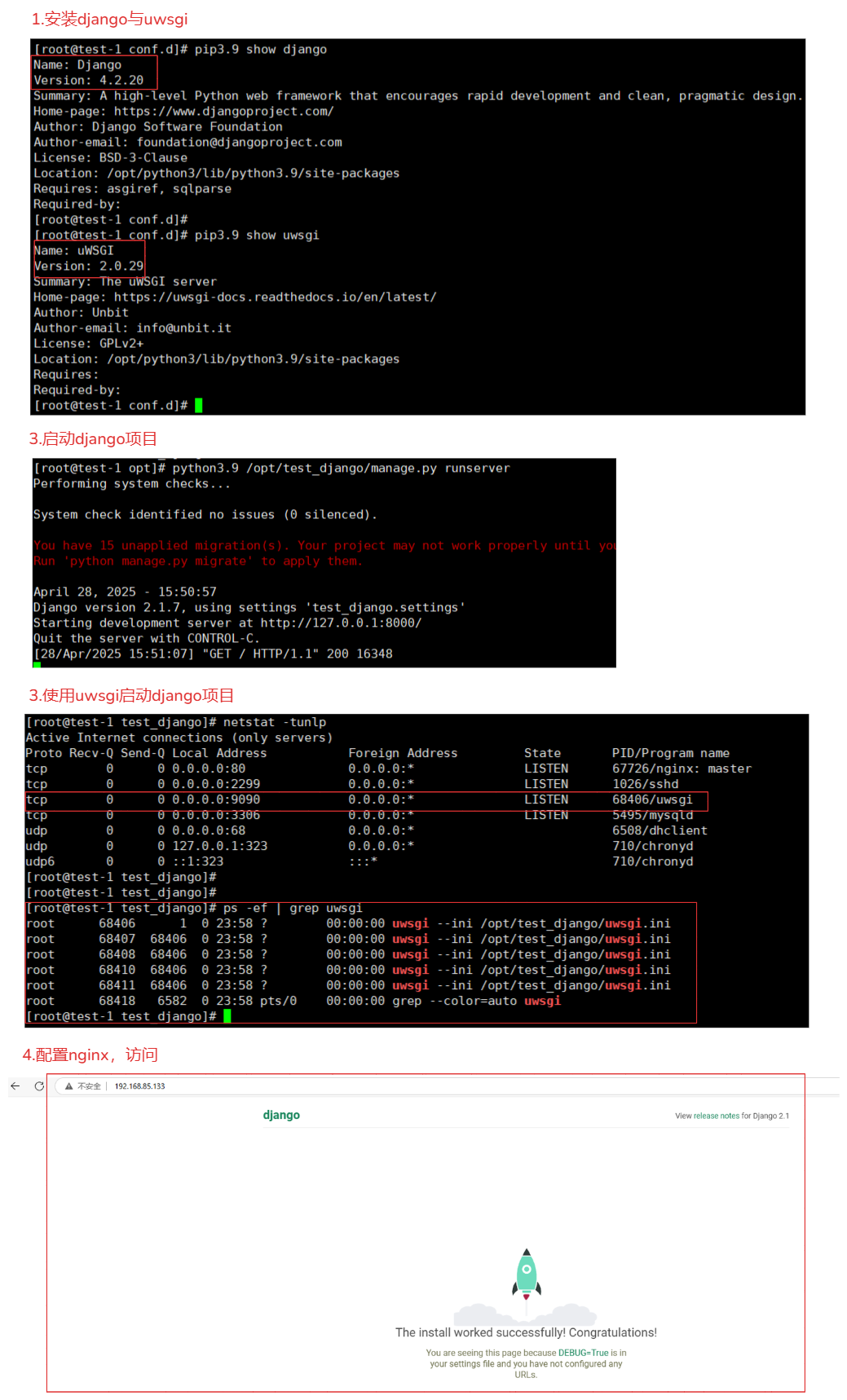
11-5-5.uwgis配置说明
- uwgis 不仅支持
HTTP协议、uWSGI 协议部署方式,还支持FastCGI 协议、HTTP/2 协议、WebSocket 协议。 - 所以在 Nginx 配置文件中可以使用
proxy_pass(配置文件需要使用http指令,uWSGI 将以 HTTP 协议监听指定的地址和端口),也可以使用uwsgi_pass(需要使用socket指令,Nginx 将请求以 HTTP 协议转发到 uWSGI。)。 - 文档:https://uwsgi-docs.readthedocs.io/en/latest/
- 建议最好使用
Supervisor管理uwgis。
# 参数说明
[uwsgi]
uid = root # 指定用户
gid = root # 指定用户组
# socket = /tmp/uwsgi/uwsgi.sock # 使用uwsgi协议使用的uwsgi_pass反向代理uwsgi_pass unix:///tmp/uwsgi/uwsgi.sock;
socket = 127.0.0.1:8000 # 使用uwsgi协议,使用的uwsgi_pass反向代理 uwsgi_pass uwsgi://127.0.0.1:8000;
# http = 127.0.0.1:9090 # 使用的http协议,使用nginx的proxy_pass反向代理。可以http://127.0.0.1:9090 访问
master = true # 启用主进程管理器
workers = 2 # 开起2个子进程数,提升并发量,建议设置服务器的 CPU 核心数的倍数
processes = 4 # 指定启动的 uWSGI 工作进程数量 通过工作进程来提并发量
threads = 2 # 指定每个 uWSGI 工作进程中的线程数量 每个工作进程可以包含多个线程来处理请求 增加线程数量可以提高每个工作进程的并发处理能力,但也会增加系统资源的消耗
vacuum = true # 当 uWSGI 退出时,自动清理 UNIX 套接字和 PID 文件
max-request = 1000 # 每个 worker 处理的最大请求数
pidfile = /tmp/uwsgi/uwsgi.pid # pid存储文件
daemonize =/tmp/uwsgi/logs/uwsgi.log # 日志存储文件
logformat = %(addr) - %(user) | %(ltime) | pid:%(pid) wid:%(wid) | %(proto) %(status) | %(method) | %(host)%(uri) | request_body_size:%(cl) | response_body_size:%(rsize) # 存储日志格式
limit-as = 512 # 用于设置 uWSGI 进程的内存限制 将进程的内存控制在512m
chdir = "django项目的根目录所在路径"
module = "django项目的根目录wsgi文件" # 也就是你创建的django项目 主项目名称.uwsgi.py
no-site = true # 禁用 Python 的 site 模块 site 模块是 Python 中的一个标准模块,它会在 Python 解释器启动时自动导入,并且会添加一些额外的路径到 sys.path 中,这可能会导致一些意外的行为或不必要的路径被包含。
vhost = true # 开起虚拟主机模式,Host 头信息来区分不同的虚拟主机,并将请求路由到相应的应用程序
buffer-size = 65535 #用于设置 uWSGI 服务器与客户端之间通信的缓冲区大小,表示每个连接的缓冲区大小为 65535 字节。适当调整缓冲区大小可以根据实际需求和服务器性能来提高数据传输的效率,从而优化系统的性能表现。
reload-threads = 3 # 设置用于重新加载应用程序的线程数量。当应用程序代码发生变化时,uWSGI 可以使用多个线程来平滑地重载新的应用程序代码。
reload-mercy = 8 # 设置重新加载应用程序的等待时间。在重新加载应用程序时,uWSGI 会等待一段时间来容忍旧的工作进程继续处理请求,直到新的工作进程完全启动。
# 启动
uwsgi --ini /uwsgi_path/uwsgi.ini # 启动
uwsgi --reload /uwsgi_path/uwsgi.ini # 重载
uwsgi --stop /uwsgi_path/uwsgi.pid # 关闭
11-6.部署PHP程序
- 实现 linux(centos7)+ php + nginx +mysql的部署操作。
11-6-1.安装php
1.卸载旧环境
yum remove php php-fpm php-common -y
2.环境包 # 因为网络问题无法下载软件。大公司都会自建yum仓库
rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
3.安装php7
yum install -y php71w-cli php71w-common php71w-devel php71w-embedded php71w-gd php71w-mcrypt php71w-mbstring php71w-pdo php71w-xml php71w-fpm php71w-mysqlnd php71w-opcache php71w-pecl-memcached php71w-pecl-redis php71w-pecl-mongodb php71w-json php71w-pecl-apcu php71w-pecl-apcu-devel
4.验证
php -v
5.修改配置,将用户与用户组进行修改www用户
grep -E '^(group|user)' /etc/php-fpm.d/www.conf
# 用户与用户组修改为www
sed -ri '/^(user)/ s#apache#www#' /etc/php-fpm.d/www.conf
sed -ri '/^(group)/ s#apache#www#' /etc/php-fpm.d/www.conf

11-6-2.安装mysql数据库
1.安装
yum install mariadb-server mariadb -y
2.启动mysql
systemctl start mariadb.service
3.查看端口 # 默认启动在3306端口
netstat -tunlp | grep 3306
4.创建密码
mysqladmin password 123456
5.验证
mysql -uroot -p123456 -e "show variables like 'hostname';"
11-6-3.配置nginx
1.创建测试数据
mkdir /code && chown -P www.www /code && echo '<?php phpinfo() ?>' > /code/index.php
2.nginx配置
server{
listen 80;
server_name _;
# 静态请求,资源存放路径
root /code; # 根目录
location / {
index index.php;
}
# 动态请求处理,正则匹配区分大小写以php结尾
location ~ \.php$ {
fastcgi_pass 127.0.0.1:9000; # 转发地址
fastcgi_index index.php; # 设置的首页
# 保留url格式,本质上就是将http的协议数据转为fastcgi格式进行赋值
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
# 存储者faskcgi使用的变量(让faskcgi可以懂的nginx的内置变量)
include fastcgi_params;
}
}
# 参数说明
$document_root 就表示当前locatin设置的root或是alias的目录
SCRIPT_FILENAME 用于在php中确定脚本名字
fastcgi_script_name 请求的URL
整体意思是,用户发来的php相关请求,包括请求中的所有参数,全部转发给127.0.0.1:9000的php程序。
# 补充说明:
SCRIPT_FILENAME $document_root$fastcgi_script_name 解释显示的是一个文件的路径,将文件路径赋值给SCRIPT_FILENAME
$document_root: 就是root参数配置根路径
$fastcgi_script_name:就是当前访问php文件的路径
比如:
http://10.0.0.8/task_phpinfo.php = /task_phpinfo.php
http://10.0.0.8/www/task_phpinfo.php = /www/task_phpinfo.php
http://10.0.0.8/www/asdasdas/task_phpinfo.php = /www/asdasdas/task_phpinfo.php
$document_root$fastcgi_script_name:就是 root/访问的php文件路径进行拼接
比如:
/code/task_phpinfo.php
11-6-4.启动测试
1.启动
systemctl start nginx
systemctl start php-fpm
2.查看端口访问网页
netstat -tunlp
11-6-5.识别mysql链接
1.创建一个链接mysql的php文件
vim /code/mysql-test.php
# 添加内容,识别mysql数据库
<?php
$server="127.0.0.1";
$mysql_user="root";
$mysql_pwd="123456";
// 创建数据库连接
$conn=mysqli_connect($server,$mysql_user,$mysql_pwd);
// 检测连通性
if($conn){
echo "mysql successful \n";
}else {
die( "Connection failed: " . mysqli_connect_error());
}
?>
2.重启一下php-fpm
systemctl restart php-fpm
3.访问查看是否可以正常链接
# 如果未识别启动,需要安装php驱动。
11-6-6.部署wecenter论坛
1.下载源码
https://wenda.isimpo.cn/timeline/index.html # 需要登录操作
2.解压文件
unzip wecenter-master.zip
3.添加nginx配置文件
vim etc/nginx/conf.d/wecenters.conf
server {
listen 80;
server_name _;
# 将location 简写
root /opt/wecenter-master/;
index index.php index.html;
# 动态接口,访问动态请求
location ~ \.php$ {
root /opt/wecenter-master/;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
3.创建专属的wecenter数据库
mysql -uroot -p123456 -e "create database wecenter character set utf8 collate utf8_bin; "
4.重启
systemctl restart php-fpm
systemctl restart nginx
5.访问
192.168.85.133:80 # 按照安装说明配置即可进行下一步即可
11-6-7.部署wordpress博客系统
1.下载源码 # 网址:https://cn.wordpress.org/download/
wget https://cn.wordpress.org/wordpress-6.3.1-zh_CN.tar.gz # 版本过高可能导致php版本不兼容
2.解压
tar -zxvf latest-zh_CN.tar.gz
3.配置nginx
vim /etc/nginx/conf.d/wordpress.conf
server {
listen 81;
server_name _;
location / {
root /opt/wordpress/;
index index.html index.php;
}
location ~ \.php$ {
root /opt/wordpress/;
fastcgi_index index.php;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
}
3.创建数据库
mysql -uroot -p123456 -e "create database wordpress character set utf8 collate utf8_bin; "
4.重启
systemctl restart php-fpm
systemctl restart nginx
5.访问
192.168.85.133:81
11-7.部署java程序
- java项目也是通过proxy_pass进行代理的。
Spring Boot框架是带有tomcat服务器的,tomcat支持http服务器功能,所以使用proxy_pass反向代理。- 如果没有Tomcat ,就需要另外准备Tomcat ,部署到 Tomcat 中进行管理。
# 当前部署过程是,将war包部署到Tomcat中进行管理,然后在使用nginx反向代理。
1.jpress与tomcat和java环境
2.安装jdk环境,设置环境变量
tar -zxf /opt/javatest/jdk-8u221-linux-x64.tar.gz -C /opt/javatest/
ln -s /opt/javatest/jdk1.8.0_221/ /opt/jdk8
vim /etc/profile 写入:
export JAVA_HOME=/opt/jdk8/ # 设置家目录
export PATH=${PATH}:${JAVA_HOME}/bin/:${JAVA_HOME}/jre/bin/ # 设置环境变量
export CLASSPATH=.$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$JAVA_HOME/lib/tools.jar # 设置classpath类目录
source /etc/profile
java -version
3.解压tomcat,设置软连接
tar -zxf /opt/javatest/apache-tomcat-8.0.27.tar.gz -C /opt/javatest/
ln -s /opt/javatest/apache-tomcat-8.0.27 /opt/tomcat8
/opt/tomcat8/bin/version.sh # 检查
4.将jperss存放到tomcat的webapps文件中
mv /opt/javatest/jpress.war /opt/tomcat8/webapps/
5.修改tomcat配置
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> # 注释,关闭8009的端口开启
<Context path="" docBase="jpress" reloadable="true" /> # 找到 <Host> 标签 添加,默认首页是 jpress.war 长须
6.启动/关闭tomcat
/opt/tomcat8/bin/catalina.sh stop
/opt/tomcat8/bin/catalina.sh start
7.nginx代理
server {
listen 80;
server_name _;
location / {
proxy_pass http://127.0.0.1:8080; # 到tomcat
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
12.实战配置
12-1.防盗链
模块:ngx_http_referer_module
文档:https://nginx.org/en/docs/http/ngx_http_referer_module.html
# 配置
1.网站的静态资源
valid_referers none blocked *.example.com;
location ~ \.(jpg|png|gif)$ {
if ( $invalid_referer ){
return 404;
}
}
2.代理转发,值判断静态资源
valid_referers none blocked *.kaixinblog.cn;
location / {
if ( $uri ~* \.(png|jpg|gif|webp)$ ){ # 只判断图片文件
if ( $invalid_referer ){
return 404;
}
}
proxy_pass 127.0.0.1:9000;
}
3.判断所有,如果是其他网站跳转
valid_referers none blocked *.kaixinblog.cn;
location / {
if ( $invalid_referer ){
return 405;
}
proxy_pass 127.0.0.1:9000;
}
# 解释:
valid_referers 指令用于限制 HTTP 请求的来源(请求头中Referer)。它指定了一个字符串列表,只有当请求的 Referer 在该列表中时,才会被允许访问。
"none": 参数表示允许没有 Referer 头部的请求访问资源,即直接访问 URL 而不使用任何网站或链接的跳转时,$http_referer 变量的值是空的。
"blocked": 参数表示只允许没有 Referer 字段或者 Referer 字段为空的请求访问。
"*.kaixinblog.cn":允许访问的域名地址。
${invalid_referer}:就是valid_referers赋值。
12-1-1.测试机器A
ip:192.168.85.135
配置:
server {
listen 80;
server_name _;
valid_referers none blocked *.example.com; # 设置了防盗链
location / {
root /www/80/;
index index.html;
}
location ~ \.(jpg|png|gif)$ {
if ( $invalid_referer ){
return 405;
}
root /www/80/;
}
}
12-1-1.测试机器B
ip:192.168.85.144
配置:
server {
listen 80;
server_name _;
location / {
root /www/80;
index index.html;
}
}
index.html 文件
192.168.85.144
<img src="http://192.168.85.135/image-20231001010029371.png" />
12-2.域名绑定后不允许ip访问
# 实现只能域名访问,不可以ip访问
配置:
# 也可以直接使用http_host变量进行判断处理。
map $http_host $allowed_domain {
default 0;
~^www\.linux\.com$ 1;
~^linux\.com$ 1;
}
server {
listen 80;
server_name _;
location / {
if ($allowed_domain = 0) {
return 403;
}
root /www/80;
index index.html;
}
}
# 参数解释:
map 指令的主要作用就是将 $http_host 变量的值映射到另一个变量上,以便在 server 块中使用
$http_host 是请求的主机名。
$allowed_domain 设置一个变量
default 0; 默认值参数为0
~^www\.linux\.com$ 1 和 ~^linux\.com$ 1 表示允许访问 www.linux.com 和 linux.com 域名,访问时$allowed_domain就是1。
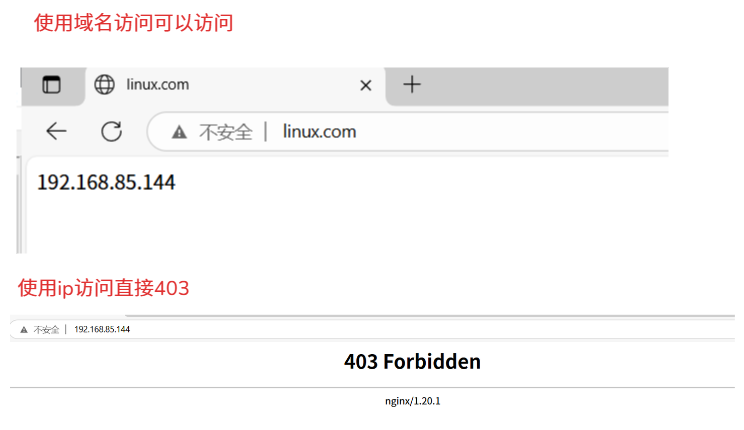
12-3.HTTP跳转HTTPS
server { # 使用return
listen 80;
server_name example.com;
location / {
return 301 https://$host$request_uri;
}
}
server { # 使用rewrite
listen 80;
server_name example.com;
location / {
rewrite ^(.*)$ https://$host$1 permanent;
}
}
server {
listen 443 ssl http2;
server_name example.com;
ssl_certificate /path/to/cert.pem;
ssl_certificate_key /path/to/key.pem;
location / {
proxy_pass 127.0.0.1:9000; # 代理地址
proxy_set_header Host $http_host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 30;
proxy_send_timeout 60;
proxy_read_timeout 60;
}
}
# 从http://example.com/ 转为 https://example.com/,2级域名跳转到3级域名也是同理。
12-4.静态资源缓存
location ~* \.(jpg|jpeg|gif|png|css|js|ico|xml)$ {
add_header Cache-Control "public"; # 添加请求头,表示可以被中间件进行缓存
expires 30d; # 缓存30天
etag on;
last_modified on;
}
etag 解释:
是 HTTP 协议中的一个头部字段,用于标识资源的一个特定版本。on 表示启用 ETag 生成。ETag 通常是一个哈希值,用于在后续请求中检查资源是否被修改。如果资源未被修改,服务器可以返回 304 Not Modified 状态码,告知客户端使用缓存的版本。
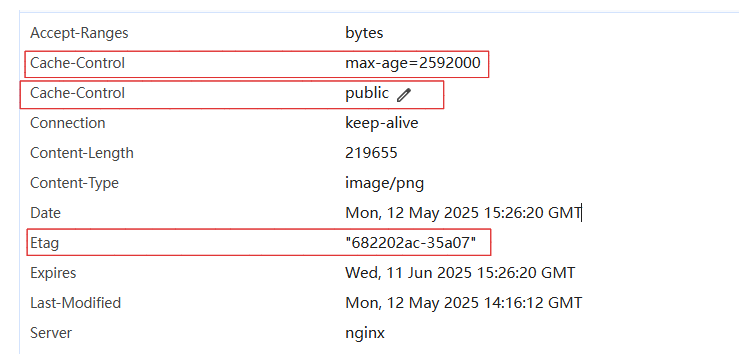
12-5.黑名单限流设置
# 限制ip访问
模块:ngx_http_access_module
文档:https://nginx.org/en/docs/http/ngx_http_access_module.html
# 注意模块中deny参数与allow参数的顺序
server {
listen 80;
server_name example.com;
location / {
# 拒绝特定 IP 地址
deny 192.168.1.100;
deny 10.0.0.1;
# 允许其他 IP 地址
allow all;
# 其他配置
root /var/www/html;
index index.html;
}
}
# 限制访问请求次数
模块:ngx_http_limit_req_module
文档:https://nginx.org/en/docs/http/ngx_http_limit_req_module.html
http {
# 定义一个请求限制区域
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
}
server {
listen 80;
server_name example.com;
location / {
# 应用请求限制
limit_req zone=one burst=5 nodelay;
# 其他配置
root /var/www/html;
index index.html;
}
}
12-6.跨域问题
# 跨域问题的出现:
1.不同的域名
请求域名:http://example.com
响应域名:http://another-example.com
2.不同的端口
请求域名:http://example.com:80
响应域名:http://example.com:81
3.不同的协议
请求域名:http://example.com
响应域名:https://example.com
1.配置全局跨域
server {
listen 80;
server_name example.com;
location / {
# 允许所有域名跨域
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
# 处理 OPTIONS 预检请求
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
# 其他配置
proxy_pass http://backend;
}
}
2.定义规定域名进行跨域
map $http_origin $cors_origin {
default "";
"~^https://example.com$" $http_origin;
"~^https://another.com$" $http_origin;
}
server {
listen 80;
server_name example.com;
location / {
# 动态设置允许的域名
add_header 'Access-Control-Allow-Origin' $cors_origin;
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
# 处理 OPTIONS 预检请求
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
# 其他配置
proxy_pass http://backend;
}
}
12-6-1.测试
# 80端口index.html文件内容
192.168.85.135
<img id="image"/>
<script>
fetch('http://192.168.85.135:81/image-20231001010029371.png')
.then(response => response.blob())
.then(blob => {
const url = URL.createObjectURL(blob);
document.getElementById('image').src = url;
})
.catch(error => console.error('Error:', error));
</script>
# nginx配置如下
server {
listen 80;
server_name _;
root /www/80/;
location / {
index index.html;
}
}
server {
listen 81;
server_name _;
root /www/81/;
location ~* \.(jpg|jpeg|gif|png|css|js|ico|xml)$ {
# 允许所有域名跨域
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
# 处理 OPTIONS 预检请求
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
return 204;
}
add_header Cache-Control "public";
expires 30d;
etag on;
}
}
# 注意:
将跨域内容发到location外部可能导致不生效,也就是add_header不会添加或者冲突,导致还是存储跨域问题,所以建议放到location内部。
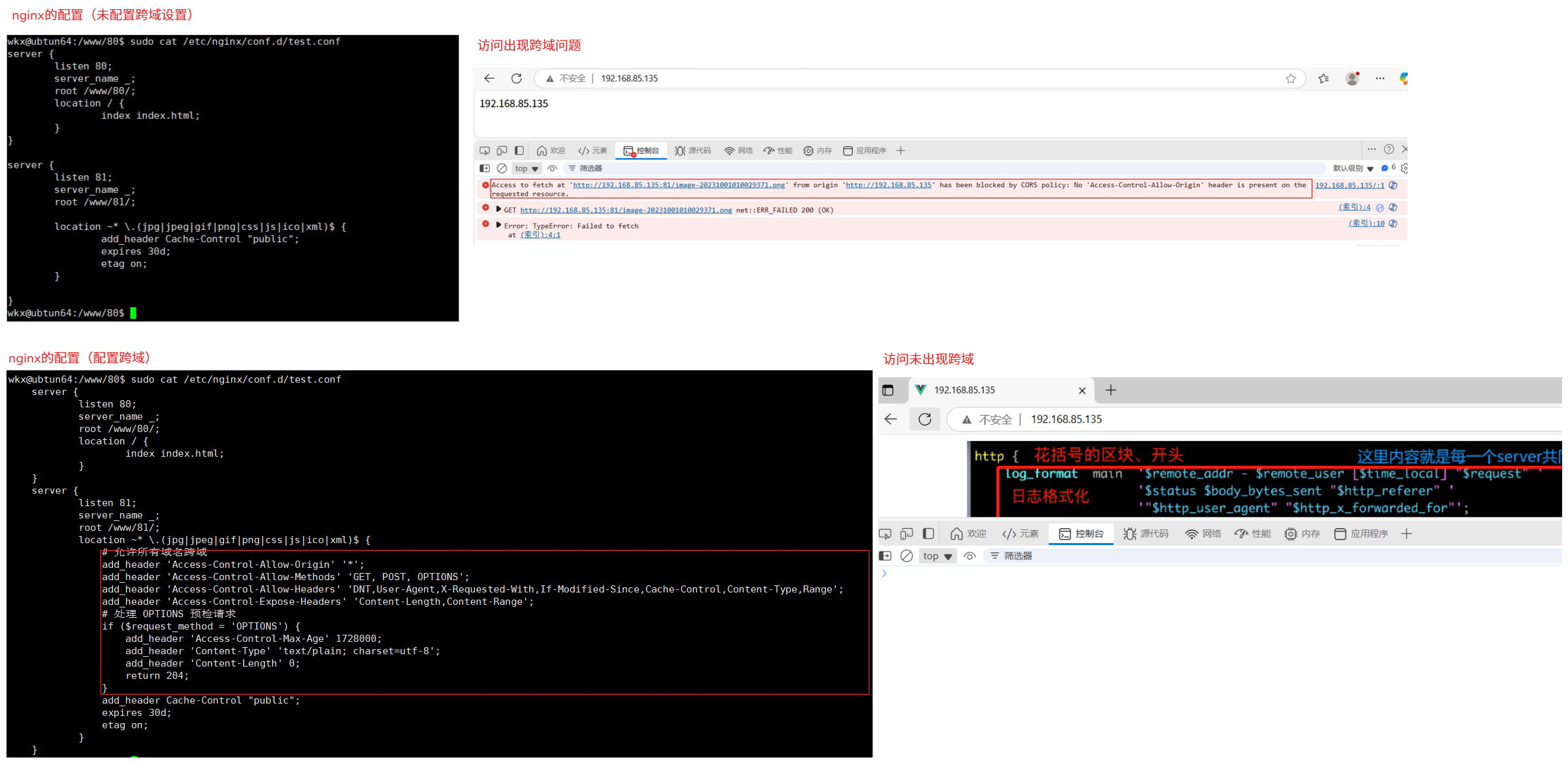
12-7.服务器组Cookie问题
1.使用iphash算法,保证访问的是同一个后端接口
http {
upstream backend {
ip_hash; # 启用 IP 哈希
server api1.example.com;
server api2.example.com;
}
server {
listen 80;
server_name example.com;
location / {
proxy_pass http://backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
2.使用jwt token + Redis 或其他共享存储实现会话保持
1.登录后,返回验证通过的token值给前端,存储到共享存储中 redis
2.前端将token值进行携带访问时,返回给后端
3.后端接口进行验证token值。
12-8.优化
1. 关于cpu的核心优化(一个进程跑在一个核上 对核数的充分利用)
目标:实现大并发
# 手动开启
worker_processes 4; # 工作进程数量 按照cpu的总核心调整
worker_cpu_affinity 0001 0010 0100 1000; # 代表开启了4个核0001 0010 0100 1000 cup的亲和力(设置充分的利用多核优势)
# 或者直接使用auto参数自动开启
worker_processes auto;
worker_cpu_affinity auto;
worker_connections 1024; # 进程下的线程数量,可以并发的数量
2.长链接优化
http时tcp协议
目标就是:减少3次握手 4次挥手的过程
keepalive_timeout 5; # 长链接时间5秒内
keepalive_requests 8192; # 每个链接接收的最大请求数(不能次数太多,要适当的释放进程和链接,将资源释放掉,防止内存溢出)
3.数据压缩
目标:减少带宽的成本
# 通过测试将9kb的文件请求 变为1.1kb大小的请求
gzip on; # 开启压缩
gzip_proxied any; # ngixn做前端代理时应开启,表示无论后端服务器的headers头返回什么信息,都无条件压缩
gzip_min_length 1k ; # 对于小文件不压缩(小于1k不压缩)
gzip_buffers 4 8k ; # 设置压缩所需的缓冲区大小
gzip_comp_level 6; # 压缩的级别 1-9 压缩 数字远大压缩越好,但是会占用cpu的时间
gzip_types text/plain text/css application/x-javascript application/javascript application/xml; # 对什么样的类型文件进行压缩
gzip_vary on; # 是否在http header中添加vary: accept-encoding 建议开启 压缩加密
gzip_disable "MSIE[1-6]\."; # 禁用ie 6 压缩
gzip_http_version 1.0; # 设置压缩针对的http协议版本
查看是否开启压缩在响应头中查看
Content-Encoding: gzip
4.客户端缓存
目标:减少带宽,将图片放到用户的缓存中,加快访问速度
# 图片类型的静态资源在用户本地中缓存1小时
location ~* \.(png|gif)$ {
expires 3h; # 配置后静态文件会缓存到用户缓存中,3个小时(缓存前端打包的工具)
}
5.静态文件匹配返回
location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ {
root /usr/local/python3/myblog/; # 指定静态资源目录 指向nginx/html 文件也可以
}
6.根据不同情况缓存不同的内容
location ~* \.(jpg|jpeg)$ {
expires 30d;
add_header Cache-Control "public";
}
location ~* \.gif$ {
expires 30d;
add_header Cache-Control "public";
}
location ~* \.png$ {
expires 30d;
add_header Cache-Control "public";
}
location ~* \.css$ {
expires 7d;
add_header Cache-Control "public";
}
location ~* \.js$ {
expires 7d;
add_header Cache-Control "public";
}
7.try_files 用于指定Nginx在尝试访问文件时的顺序。它可以防止暴露服务器文件系统的结构,并提高安全性
server {
listen 80;
server_name example.com;
root /path/to/your/static/files;
location / {
try_files $uri $uri/ @fallback;
}
# 默认是返回404页面
location @fallback {
# 返回自定义的错误页面
error_page 404 /custom_404.html; # 修改当前内容
return 404;
}
}
try_files $uri $uri/ @fallback; 用于尝试访问文件,如果文件不存在则跳转到 @fallback 位置。
location @fallback { ... } 定义了一个命名位置 @fallback,用于处理文件不存在的情况。
error_page 404 /custom_404.html; 指定了当文件不存在时应该返回的自定义页面的路径。
return 404; 确保返回的状态码是 404。
你可以根据需要自定义错误页面的内容和路径
try_files $uri $uri/ /index.html; # 当前访问当前的路径根据路径匹配 $uri $uri/ 如果都无法匹配到 $uri/index.html返回首页